

How Vericast optimized feature engineering using Amazon SageMaker Processing
This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process… Feature engineering refers to the process where relevant variables are identified, selected, and man…
This post is co-written by Jyoti Sharma and Sharmo Sarkar from Vericast.
For any machine learning (ML) problem, the data scientist begins by working with data. This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process. One aspect of this data preparation is feature engineering.
Feature engineering refers to the process where relevant variables are identified, selected, and manipulated to transform the raw data into more useful and usable forms for use with the ML algorithm used to train a model and perform inference against it. The goal of this process is to increase the performance of the algorithm and resulting predictive model. The feature engineering process entails several stages, including feature creation, data transformation, feature extraction, and feature selection.
Building a platform for generalized feature engineering is a common task for customers needing to produce many ML models with differing datasets. This kind of platform includes the creation of a programmatically driven process to produce finalized, feature engineered data ready for model training with little human intervention. However, generalizing feature engineering is challenging. Each business problem is different, each dataset is different, data volumes vary wildly from client to client, and data quality and often cardinality of a certain column (in the case of structured data) might play a significant role in the complexity of the feature engineering process. Furthermore, the dynamic nature of a customer’s data can also result in a large variance of the processing time and resources required to optimally complete the feature engineering.
AWS customer Vericast is a marketing solutions company that makes data-driven decisions to boost marketing ROIs for its clients. Vericast’s internal cloud-based Machine Learning Platform, built around the CRISP-ML(Q) process, uses various AWS services, including Amazon SageMaker, Amazon SageMaker Processing, AWS Lambda, and AWS Step Functions, to produce the best possible models that are tailored to the specific client’s data. This platform aims at capturing the repeatability of the steps that go into building various ML workflows and bundling them into standard generalizable workflow modules within the platform.
In this post, we share how Vericast optimized feature engineering using SageMaker Processing.
Solution overview
Vericast’s Machine Learning Platform aids in the quicker deployment of new business models based on existing workflows or quicker activation of existing models for new clients. For example, a model predicting direct mail propensity is quite different from a model predicting discount coupon sensitivity of the customers of a Vericast client. They solve different business problems and therefore have different usage scenarios in a marketing campaign design. But from an ML standpoint, both can be construed as binary classification models, and therefore could share many common steps from an ML workflow perspective, including model tuning and training, evaluation, interpretability, deployment, and inference.
Because these models are binary classification problems (in ML terms), we are separating the customers of a company into two classes (binary): those that would respond positively to the campaign and those that would not. Furthermore, these examples are considered an imbalanced classification because the data used to train the model wouldn’t contain an equal number of customers who would and would not respond favorably.
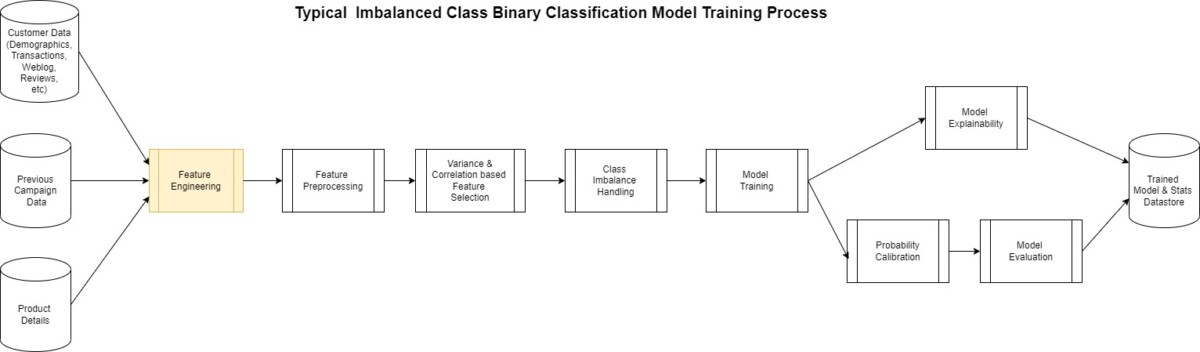
The actual creation of a model such as this follows the generalized pattern shown in the following diagram.
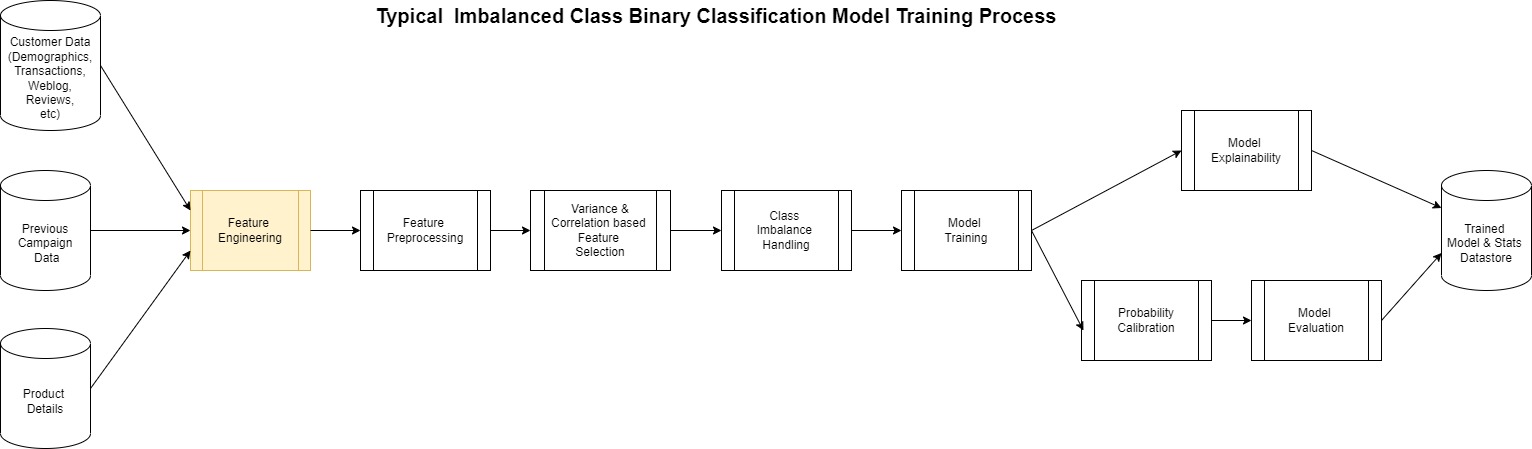
Most of this process is the same for any binary classification except for the feature engineering step. This is perhaps the most complicated yet at times overlooked step in the process. ML models are largely dependent on the features used to create it.
Vericast’s cloud-native Machine Learning Platform aims to generalize and automate the feature engineering steps for various ML workflows and optimize their performance on a cost vs. time metric by using the following features:
- The platform’s feature engineering library – This consists of an ever-evolving set of transformations that have been tested to yield high-quality generalizable features based on specific client concepts (for example, customer demographics, product details, transaction details, and so on).
- Intelligent resource optimizers – The platform uses AWS’s on-demand infrastructure capability to spin up the most optimal type of processing resources for the particular feature engineering job based on the expected complexity of the step and the amount of data it needs to churn through.
- Dynamic scaling of feature engineering jobs – A combination of various AWS services is used for this, but most notably SageMaker Processing. This ensures that the platform produces high-quality features in a cost-efficient and timely manner.
This post is focused around the third point in this list and shows how to achieve dynamic scaling of SageMaker Processing jobs to achieve a more managed, performant, and cost-effective data processing framework for large data volumes.
SageMaker Processing enables workloads that run steps for data preprocessing or postprocessing, feature engineering, data validation, and model evaluation on SageMaker. It also provides a managed environment and removes the complexity of undifferentiated heavy lifting required to set up and maintain the infrastructure needed to run the workloads. Furthermore, SageMaker Processing provides an API interface for running, monitoring, and evaluating the workload.
Running SageMaker Processing jobs takes place fully within a managed SageMaker cluster, with individual jobs placed into instance containers at run time. The managed cluster, instances, and containers report metrics to Amazon CloudWatch, including usage of GPU, CPU, memory, GPU memory, disk metrics, and event logging.
These features provide benefits to Vericast data engineers and scientists by assisting in the development of generalized preprocessing workflows and abstracting the difficulty of maintaining generated environments in which to run them. Technical problems can arise, however, given the dynamic nature of the data and its varied features that can be fed into such a general solution. The system must make an educated initial guess as to the size of the cluster and instances that compose it. This guess needs to evaluate criteria of the data and infer the CPU, memory, and disk requirements. This guess may be wholly appropriate and perform adequately for the job, but in other cases it may not. For a given dataset and preprocessing job, the CPU may be undersized, resulting in maxed out processing performance and lengthy times to complete. Worse yet, memory could become an issue, resulting in either poor performance or out of memory events causing the entire job to fail.
With these technical hurdles in mind, Vericast set out to create a solution. They needed to remain general in nature and fit into the larger picture of the preprocessing workflow being flexible in the steps involved. It was also important to solve for both the potential need to scale up the environment in cases where performance was compromised and to gracefully recover from such an event or when a job finished prematurely for any reason.
The solution built by Vericast to solve this issue uses several AWS services working together to reach their business objectives. It was designed to restart and scale up the SageMaker Processing cluster based on performance metrics observed using Lambda functions monitoring the jobs. To not lose work when a scaling event takes place or to recover from a job unexpectedly stopping, a checkpoint-based service was put in place that uses Amazon DynamoDB and stores the partially processed data in Amazon Simple Storage Service (Amazon S3) buckets as steps complete. The final outcome is an auto scaling, robust, and dynamically monitored solution.
The following diagram shows a high-level overview of how the system works.

In the following sections, we discuss the solution components in more detail.
Initializing the solution
The system assumes that a separate process initiates the solution. Conversely, this design is not designed to work alone because it won’t yield any artifacts or output, but rather acts as a sidecar implementation to one of the systems that use SageMaker Processing jobs. In Vericast’s case, the solution is initiated by way of a call from a Step Functions step started in another module of the larger system.
Once the solution initiated and a first run is triggered, a base standard configuration is read from a DynamoDB table. This configuration is used to set parameters for the SageMaker Processing job and has the initial assumptions of infrastructure needs. The SageMaker Processing job is now started.
Monitoring metadata and output
When the job starts, a Lambda function writes the job processing metadata (the current job configuration and other log information) into the DynamoDB log table. This metadata and log information maintains a history of the job, its initial and ongoing configuration, and other important data.
At certain points, as steps complete in the job, checkpoint data is added to the DynamoDB log table. Processed output data is moved to Amazon S3 for quick recovery if needed.
This Lambda function also sets up an Amazon EventBridge rule that monitors the running job for its state. Specifically, this rule is watching the job to observe if the job status changes to stopping or is in a stopped state. This EventBridge rule plays an important part in restarting a job if there is a failure or a planned auto scaling event occurs.
Monitoring CloudWatch metrics
The Lambda function also sets a CloudWatch alarm based on a metric math expression on the processing job, which monitors the metrics of all the instances for CPU utilization, memory utilization, and disk utilization. This type of alarm (metric) uses CloudWatch alarm thresholds. The alarm generates events based on the value of the metric or expression relative to the thresholds over a number of time periods.
In Vericast’s use case, the threshold expression is designed to consider the driver and the executor instances as separate, with metrics monitored individually for each. By having them separate, Vericast knows which is causing the alarm. This is important to decide how to scale accordingly:
- If the executor metrics are passing the threshold, it’s good to scale horizontally
- If the driver metrics cross the threshold, scaling horizontally will probably not help, so we must scale vertically
Alarm metrics expression
Vericast can access the following metrics in its evaluation for scaling and failure:
- CPUUtilization – The sum of each individual CPU core’s utilization
- MemoryUtilization – The percentage of memory that is used by the containers on an instance
- DiskUtilization – The percentage of disk space used by the containers on an instance
- GPUUtilization – The percentage of GPU units that are used by the containers on an instance
- GPUMemoryUtilization – The percentage of GPU memory used by the containers on an instance
As of this writing, Vericast only considers CPUUtilization, MemoryUtilization, and DiskUtilization. In the future, they intend to consider GPUUtilization and GPUMemoryUtilization as well.
The following code is an example of a CloudWatch alarm based on a metric math expression for Vericast auto scaling:
This expression illustrates that the CloudWatch alarm is considering DriverMemoryUtilization (memoryDriver), CPUUtilization (cpuDriver), DiskUtilization (diskDriver), ExecutorMemoryUtilization (memoryExec), CPUUtilization (cpuExec), and DiskUtilization (diskExec) as monitoring metrics. The number 80 in the preceding expression stands for the threshold value.
Here, IF((cpuDriver) > 80, 1, 0 implies that if the driver CPU utilization goes beyond 80%, 1 is assigned as the threshold else 0. IF(AVG(METRICS("memoryExec")) > 80, 1, 0 implies that all the metrics with string memoryExec in it are considered and an average is calculated on that. If that average memory utilization percentage goes beyond 80, 1 is assigned as the threshold else 0.
The logical operator OR is used in the expression to unify all the utilizations in the expression—if any of the utilizations reach its threshold, trigger the alarm.
For more information on using CloudWatch metric alarms based on metric math expressions, refer to Creating a CloudWatch alarm based on a metric math expression.
CloudWatch alarm limitations
CloudWatch limits the number of metrics per alarm to 10. This can cause limitations if you need to consider more metrics than this.
To overcome this limitation, Vericast has set alarms based on the overall cluster size. One alarm is created per three instances (for three instances, there will be one alarm because that would add up to nine metrics). Assuming the driver instance is to be considered separately, another separate alarm is created for the driver instance. Therefore, the total number of alarms that are created are roughly equivalent to one third the number of executor nodes and an additional one for the driver instance. In each case, the number of metrics per alarm is under the 10 metric limitation.
What happens when in an alarm state
If a predetermined threshold is met, the alarm goes to an alarm state, which uses Amazon Simple Notification Service (Amazon SNS) to send out notifications. In this case, it sends out an email notification to all subscribers with the details about the alarm in the message.
Amazon SNS is also used as a trigger to a Lambda function that stops the currently running SageMaker Processing job because we know that the job will probably fail. This function also records logs to the log table related to the event.
The EventBridge rule set up at job start will notice that the job has gone into a stopping state a few seconds later. This rule then reruns the first Lambda function to restart the job.
The dynamic scaling process
The first Lambda function after running two or more times will know that a previous job had already started and now has stopped. The function will go through a similar process of getting the base configuration from the original job in the log DynamoDB table and will also retrieve updated configuration from the internal table. This updated configuration is a resources delta configuration that is set based on the scaling type. The scaling type is determined from the alarm metadata as described earlier.
The original configuration plus the resources delta are used because a new configuration and a new SageMaker Processing job are started with the increased resources.
This process continues until the job completes successfully and can result in multiple restarts as needed, adding more resources each time.
Vericast’s outcome
This custom auto scaling solution has been instrumental in making Vericast’s Machine Learning Platform more robust and fault tolerant. The platform can now gracefully handle workloads of different data volumes with minimal human intervention.
Before implementing this solution, estimating the resource requirements for all the Spark-based modules in the pipeline was one of the biggest bottlenecks of the new client onboarding process. Workflows would fail if the client data volume increased, or the cost would be unjustifiable if the data volume decreased in production.
With this new module in place, workflow failures due to resource constraints have been reduced by almost 80%. The few remaining failures are mostly due to AWS account constraints and beyond the auto scale process. Vericast’s biggest win with this solution is the ease with which they can onboard new clients and workflows. Vericast expects to speed up the process by at least 60–70%, with data still to be gathered for a final number.
Though this is viewed as a success by Vericast, there is a cost that comes with it. Based on the nature of this module and the concept of dynamic scaling as a whole, the workflows tend to take around 30% longer (average case) than a workflow with a custom-tuned cluster for each module in the workflow. Vericast continues to optimize in this area, looking to improve the solution by incorporating heuristics-based resource initialization for each client module.
Sharmo Sarkar, Senior Manager, Machine Learning Platform at Vericast, says, “As we continue to expand our use of AWS and SageMaker, I wanted to take a moment to highlight the incredible work of our AWS Client Services Team, dedicated AWS Solutions Architects, and AWS Professional Services that we work with. Their deep understanding of AWS and SageMaker allowed us to design a solution that met all of our needs and provided us with the flexibility and scalability we required. We are so grateful to have such a talented and knowledgeable support team on our side.”
Conclusion
In this post, we shared how SageMaker and SageMaker Processing have enabled Vericast to build a managed, performant, and cost-effective data processing framework for large data volumes. By combining the power and flexibility of SageMaker Processing with other AWS services, they can easily monitor the generalized feature engineering process. They can automatically detect potential issues generated from lack of compute, memory, and other factors, and automatically implement vertical and horizontal scaling as needed.
SageMaker and its tools can help your team meet its ML goals as well. To learn more about SageMaker Processing and how it can assist in your data processing workloads, refer to Process Data. If you’re just getting started with ML and are looking for examples and guidance, Amazon SageMaker JumpStart can get you started. JumpStart is an ML hub from which you can access built-in algorithms with pre-trained foundation models to help you perform tasks such as article summarization and image generation and pre-built solutions to solve common use cases.
Finally, if this post helps you or inspires you to solve a problem, we would love to hear about it! Please share your comments and feedback.
About the Authors
 Anthony McClure is a Senior Partner Solutions Architect with the AWS SaaS Factory team. Anthony also has a strong interest in machine learning and artificial intelligence working with the AWS ML/AI Technical Field Community to assist customers in bringing their machine learning solutions to reality.
Anthony McClure is a Senior Partner Solutions Architect with the AWS SaaS Factory team. Anthony also has a strong interest in machine learning and artificial intelligence working with the AWS ML/AI Technical Field Community to assist customers in bringing their machine learning solutions to reality.
 Jyoti Sharma is a Data Science Engineer with the machine learning platform team at Vericast. She is passionate about all aspects of data science and focused on designing and implementing a highly scalable and distributed Machine Learning Platform.
Jyoti Sharma is a Data Science Engineer with the machine learning platform team at Vericast. She is passionate about all aspects of data science and focused on designing and implementing a highly scalable and distributed Machine Learning Platform.
 Sharmo Sarkar is a Senior Manager at Vericast. He leads the Cloud Machine Learning Platform and the Marketing Platform ML R&D Teams at Vericast. He has extensive experience in Big Data Analytics, Distributed Computing, and Natural Language Processing. Outside work, he enjoys motorcycling, hiking, and biking on mountain trails.
Sharmo Sarkar is a Senior Manager at Vericast. He leads the Cloud Machine Learning Platform and the Marketing Platform ML R&D Teams at Vericast. He has extensive experience in Big Data Analytics, Distributed Computing, and Natural Language Processing. Outside work, he enjoys motorcycling, hiking, and biking on mountain trails.
Author: Anthony McClure