

Deploy generative AI models from Amazon SageMaker JumpStart using the AWS CDK
Like all AI, generative AI is powered by ML models—very large models that are pre-trained on vast corpora of data and commonly referred to as foundation models (FMs)… The size and general-purpose nature of FMs make them different from traditional ML models, which typically perform specific tas…
The seeds of a machine learning (ML) paradigm shift have existed for decades, but with the ready availability of virtually infinite compute capacity, a massive proliferation of data, and the rapid advancement of ML technologies, customers across industries are rapidly adopting and using ML technologies to transform their businesses.
Just recently, generative AI applications have captured everyone’s attention and imagination. We are truly at an exciting inflection point in the widespread adoption of ML, and we believe every customer experience and application will be reinvented with generative AI.
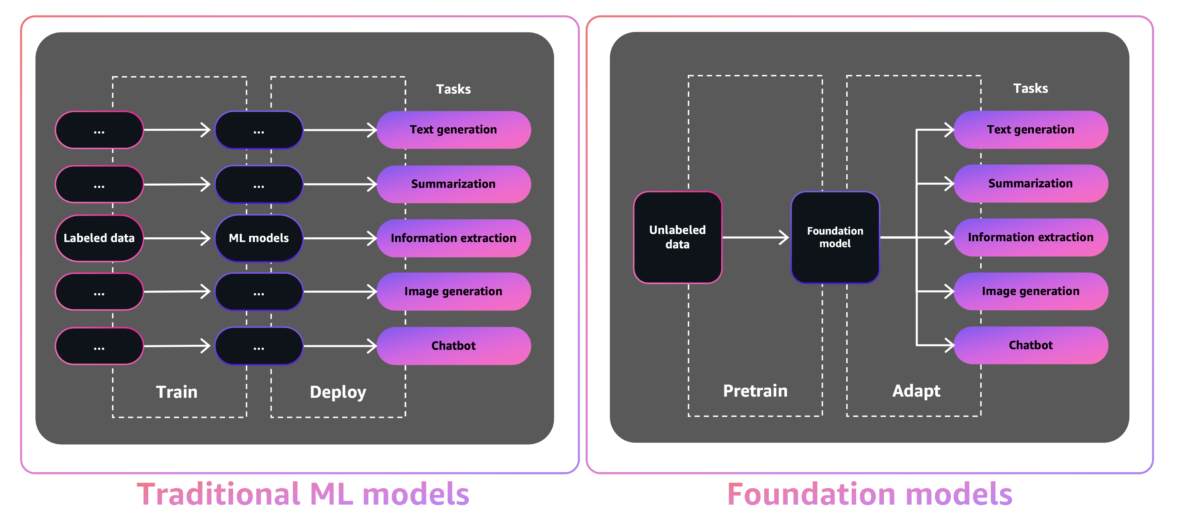
Generative AI is a type of AI that can create new content and ideas, including conversations, stories, images, videos, and music. Like all AI, generative AI is powered by ML models—very large models that are pre-trained on vast corpora of data and commonly referred to as foundation models (FMs).
The size and general-purpose nature of FMs make them different from traditional ML models, which typically perform specific tasks, like analyzing text for sentiment, classifying images, and forecasting trends.
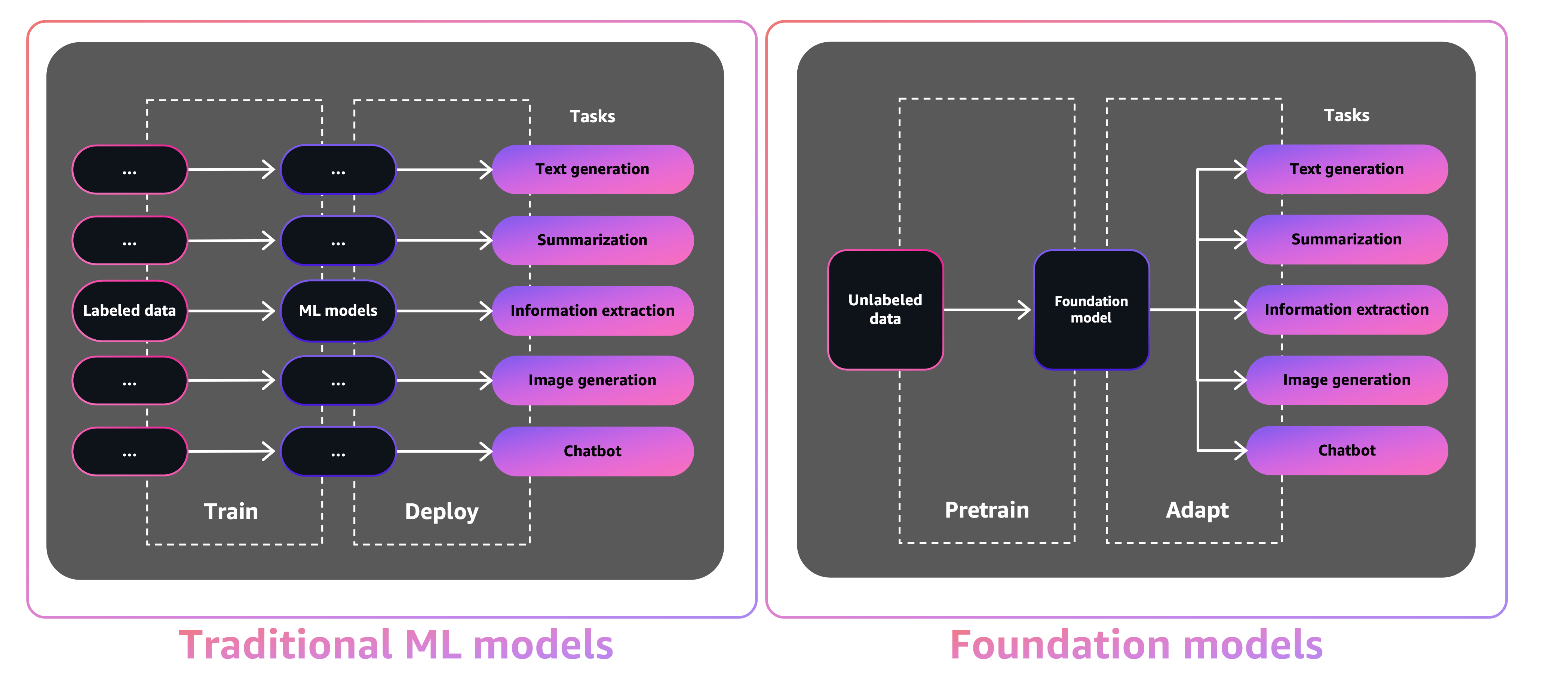
With tradition ML models, in order to achieve each specific task, you need to gather labeled data, train a model, and deploy that model. With foundation models, instead of gathering labeled data for each model and training multiple models, you can use the same pre-trained FM to adapt various tasks. You can also customize FMs to perform domain-specific functions that are differentiating to your businesses, using only a small fraction of the data and compute required to train a model from scratch.
Generative AI has the potential to disrupt many industries by revolutionizing the way content is created and consumed. Original content production, code generation, customer service enhancement, and document summarization are typical use cases of generative AI.
Amazon SageMaker JumpStart provides pre-trained, open-source models for a wide range of problem types to help you get started with ML. You can incrementally train and tune these models before deployment. JumpStart also provides solution templates that set up infrastructure for common use cases, and executable example notebooks for ML with Amazon SageMaker.
With over 600 pre-trained models available and growing every day, JumpStart enables developers to quickly and easily incorporate cutting-edge ML techniques into their production workflows. You can access the pre-trained models, solution templates, and examples through the JumpStart landing page in Amazon SageMaker Studio. You can also access JumpStart models using the SageMaker Python SDK. For information about how to use JumpStart models programmatically, see Use SageMaker JumpStart Algorithms with Pretrained Models.
In April 2023, AWS unveiled Amazon Bedrock, which provides a way to build generative AI-powered apps via pre-trained models from startups including AI21 Labs, Anthropic, and Stability AI. Amazon Bedrock also offers access to Titan foundation models, a family of models trained in-house by AWS. With the serverless experience of Amazon Bedrock, you can easily find the right model for your needs, get started quickly, privately customize FMs with your own data, and easily integrate and deploy them into your applications using the AWS tools and capabilities you’re familiar with (including integrations with SageMaker ML features like Amazon SageMaker Experiments to test different models and Amazon SageMaker Pipelines to manage your FMs at scale) without having to manage any infrastructure.
In this post, we show how to deploy image and text generative AI models from JumpStart using the AWS Cloud Development Kit (AWS CDK). The AWS CDK is an open-source software development framework to define your cloud application resources using familiar programming languages like Python.
We use the Stable Diffusion model for image generation and the FLAN-T5-XL model for natural language understanding (NLU) and text generation from Hugging Face in JumpStart.
Solution overview
The web application is built on Streamlit, an open-source Python library that makes it easy to create and share beautiful, custom web apps for ML and data science. We host the web application using Amazon Elastic Container Service (Amazon ECS) with AWS Fargate and it is accessed via an Application Load Balancer. Fargate is a technology that you can use with Amazon ECS to run containers without having to manage servers or clusters or virtual machines. The generative AI model endpoints are launched from JumpStart images in Amazon Elastic Container Registry (Amazon ECR). Model data is stored on Amazon Simple Storage Service (Amazon S3) in the JumpStart account. The web application interacts with the models via Amazon API Gateway and AWS Lambda functions as shown in the following diagram.
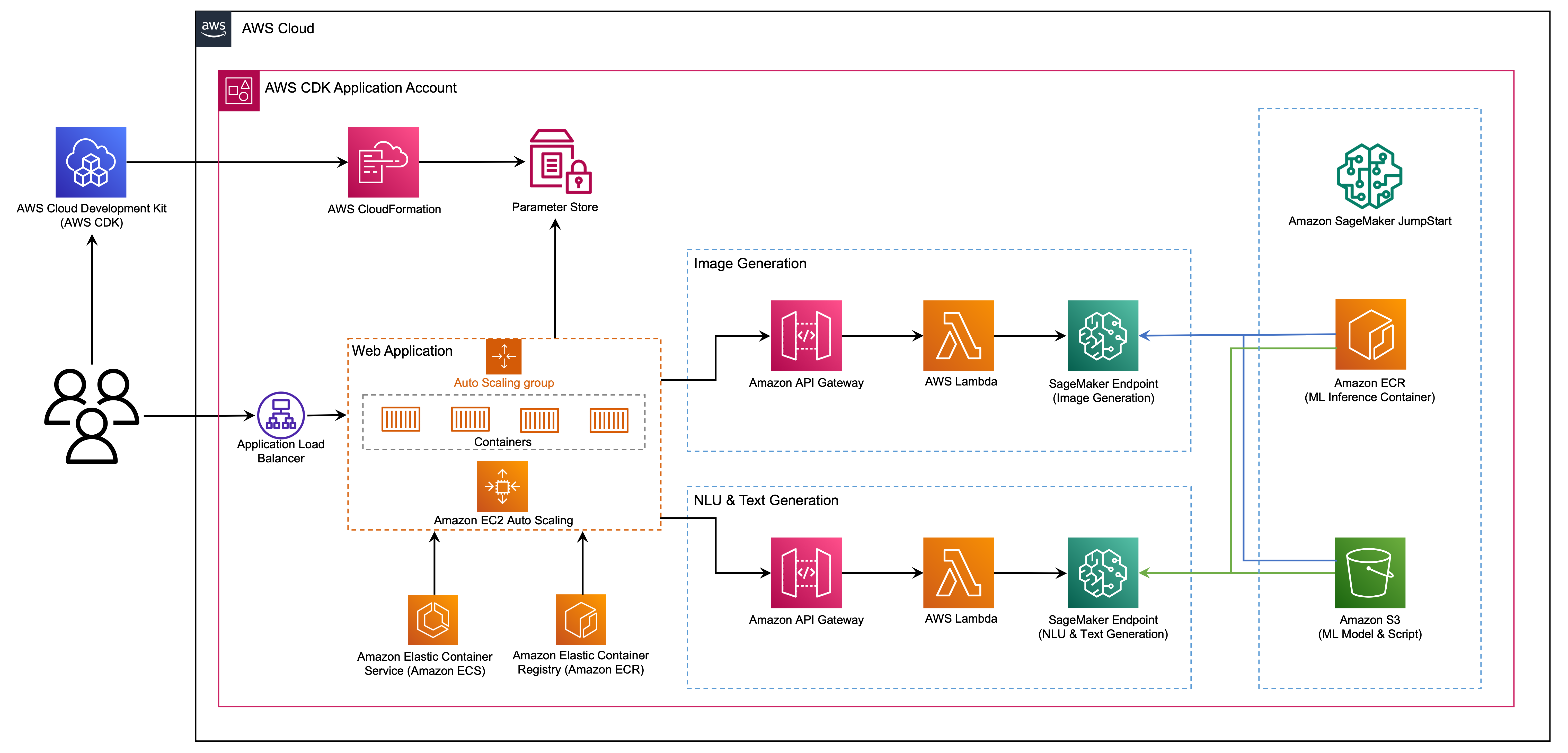
API Gateway provides the web application and other clients a standard RESTful interface, while shielding the Lambda functions that interface with the model. This simplifies the client application code that consumes the models. The API Gateway endpoints are publicly accessible in this example, allowing for the possibility to extend this architecture to implement different API access controls and integrate with other applications.
In this post, we walk you through the following steps:
- Install the AWS Command Line Interface (AWS CLI) and AWS CDK v2 on your local machine.
- Clone and set up the AWS CDK application.
- Deploy the AWS CDK application.
- Use the image generation AI model.
- Use the text generation AI model.
- View the deployed resources on the AWS Management Console.
We provide an overview of the code in this project in the appendix at the end of this post.
Prerequisites
You must have the following prerequisites:
- An AWS account
- The AWS CLI v2
- Python 3.6 or later
- node.js 14.x or later
- The AWS CDK v2
- Docker v20.10 or later
You can deploy the infrastructure in this tutorial from your local computer or you can use AWS Cloud9 as your deployment workstation. AWS Cloud9 comes pre-loaded with AWS CLI, AWS CDK and Docker. If you opt for AWS Cloud9, create the environment from the AWS console.
The estimated cost to complete this post is $50, assuming you leave the resources running for 8 hours. Make sure you delete the resources you create in this post to avoid ongoing charges.
Install the AWS CLI and AWS CDK on your local machine
If you don’t already have the AWS CLI on your local machine, refer to Installing or updating the latest version of the AWS CLI and Configuring the AWS CLI.
Install the AWS CDK Toolkit globally using the following node package manager command:
Run the following command to verify the correct installation and print the version number of the AWS CDK:
Make sure you have Docker installed on your local machine. Issue the following command to verify the version:
Clone and set up the AWS CDK application
On your local machine, clone the AWS CDK application with the following command:
Navigate to the project folder:
Before we deploy the application, let’s review the directory structure:
The stack folder contains the code for each stack in the AWS CDK application. The code folder contains the code for the Lambda functions. The repository also contains the web application located under the folder web-app.
The cdk.json file tells the AWS CDK Toolkit how to run your application.
This application was tested in the us-east-1 Region, but it should work in any Region that has the required services and inference instance type ml.g4dn.4xlarge specified in app.py.
Set up a virtual environment
This project is set up like a standard Python project. Create a Python virtual environment using the following code:
Use the following command to activate the virtual environment:
If you’re on a Windows platform, activate the virtual environment as follows:
After the virtual environment is activated, upgrade pip to the latest version:
Install the required dependencies:
Before you deploy any AWS CDK application, you need to bootstrap a space in your account and the Region you’re deploying into. To bootstrap in your default Region, issue the following command:
If you want to deploy into a specific account and Region, issue the following command:
For more information about this setup, visit Getting started with the AWS CDK.
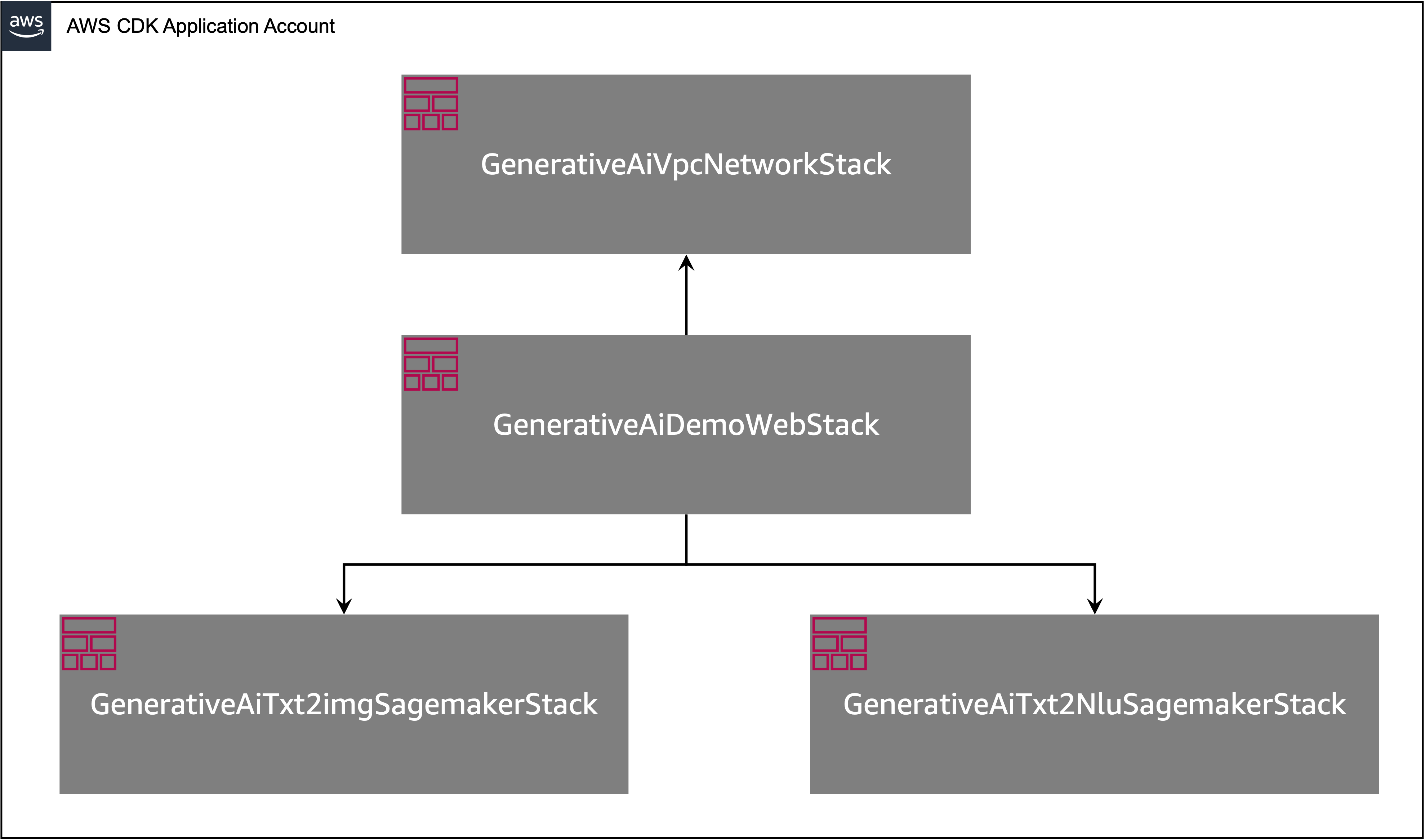
AWS CDK application stack structure
The AWS CDK application contains multiple stacks, as shown in the following diagram.
You can list the stacks in your AWS CDK application with the following command:
The following are other useful AWS CDK commands:
- cdk ls – Lists all stacks in the app
- cdk synth – Emits the synthesized AWS CloudFormation template
- cdk deploy – Deploys this stack to your default AWS account and Region
- cdk diff – Compares the deployed stack with current state
- cdk docs – Opens the AWS CDK documentation
The next section shows you how to deploy the AWS CDK application.
Deploy the AWS CDK application
The AWS CDK application will be deployed to the default Region based on your workstation configuration. If you want to force the deployment in a specific Region, set your AWS_DEFAULT_REGION environment variable accordingly.
At this point, you can deploy the AWS CDK application. First you launch the VPC network stack:
If you are prompted, enter y to proceed with the deployment. You should see a list of AWS resources that are being provisioned in the stack. This step takes around 3 minutes to complete.
Then you launch the web application stack:
After analyzing the stack, the AWS CDK will display the resource list in the stack. Enter y to proceed with the deployment. This step takes around 5 minutes.
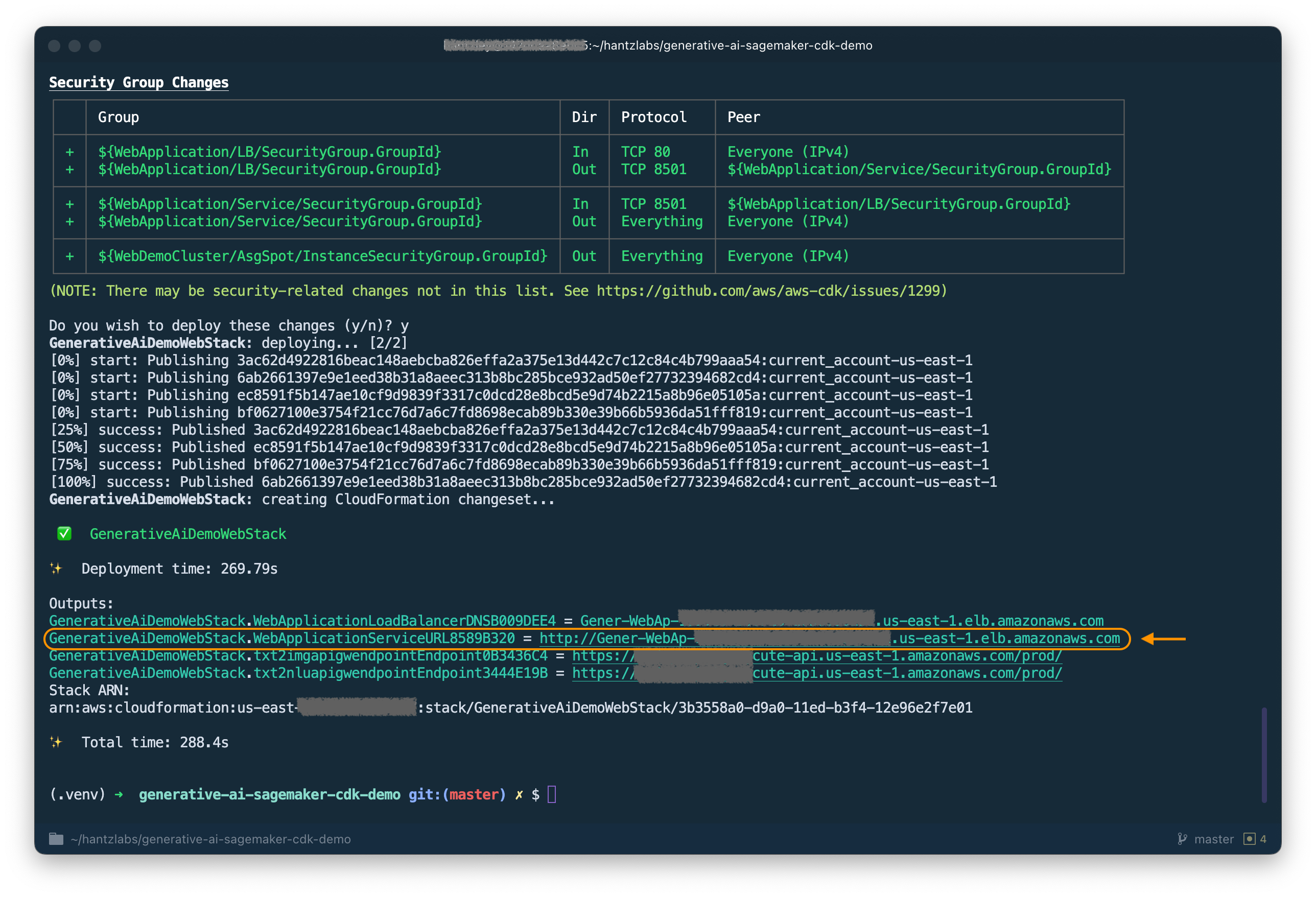
Note down the WebApplicationServiceURL from the output to use later. You can also retrieve it on the AWS CloudFormation console, under the GenerativeAiDemoWebStack stack outputs.
Now, launch the image generation AI model endpoint stack:
This step takes around 8 minutes. The image generation model endpoint is deployed, we can now use it.
Use the image generation AI model
The first example demonstrates how to utilize Stable Diffusion, a powerful generative modeling technique that enables the creation of high-quality images from text prompts.
- Access the web application using the
WebApplicationServiceURLfrom the output ofGenerativeAiDemoWebStackin your browser.

- In the navigation pane, choose Image Generation.
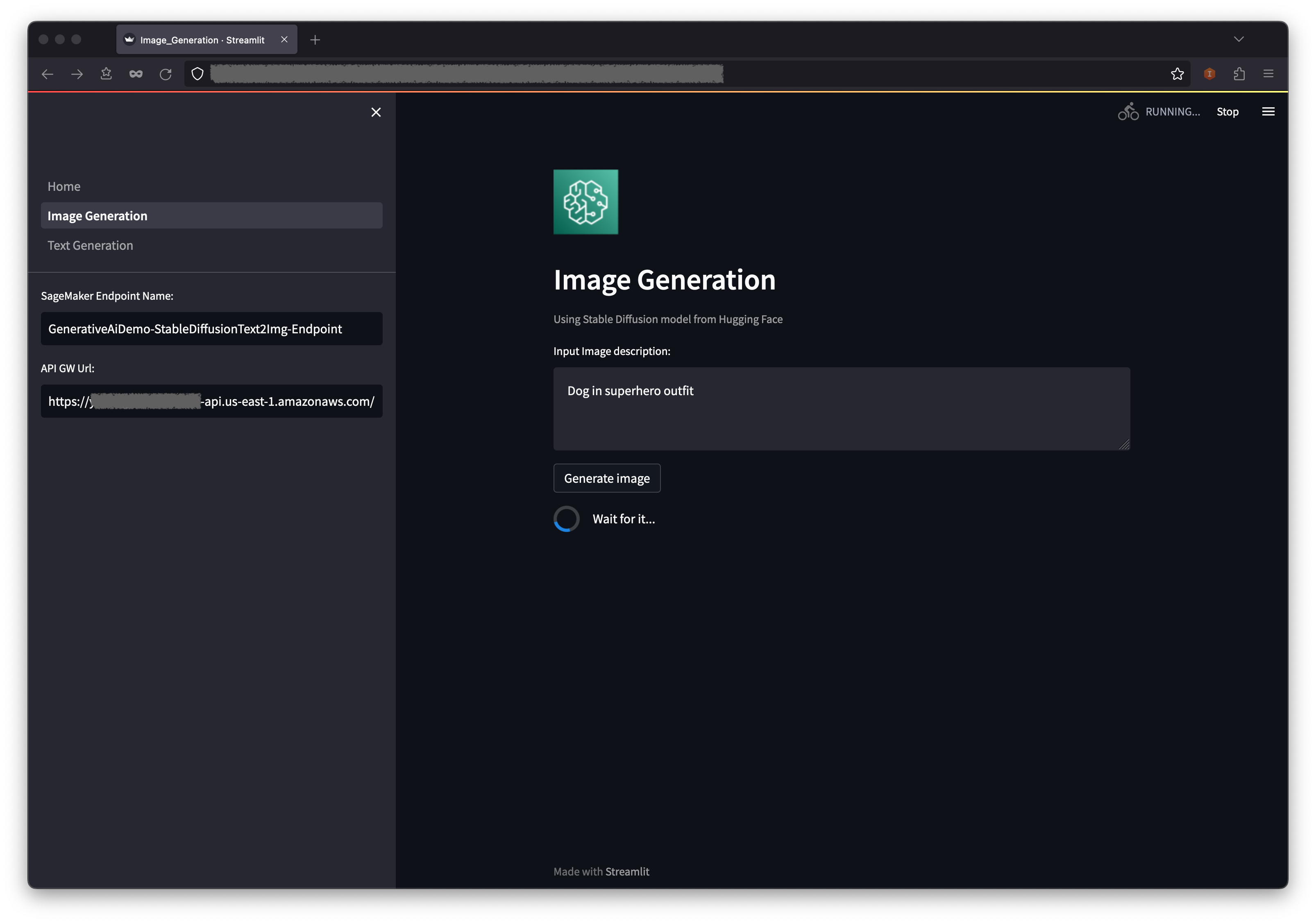
- The SageMaker Endpoint Name and API GW Url fields will be pre-populated, but you can change the prompt for the image description if you’d like.
- Choose Generate image.

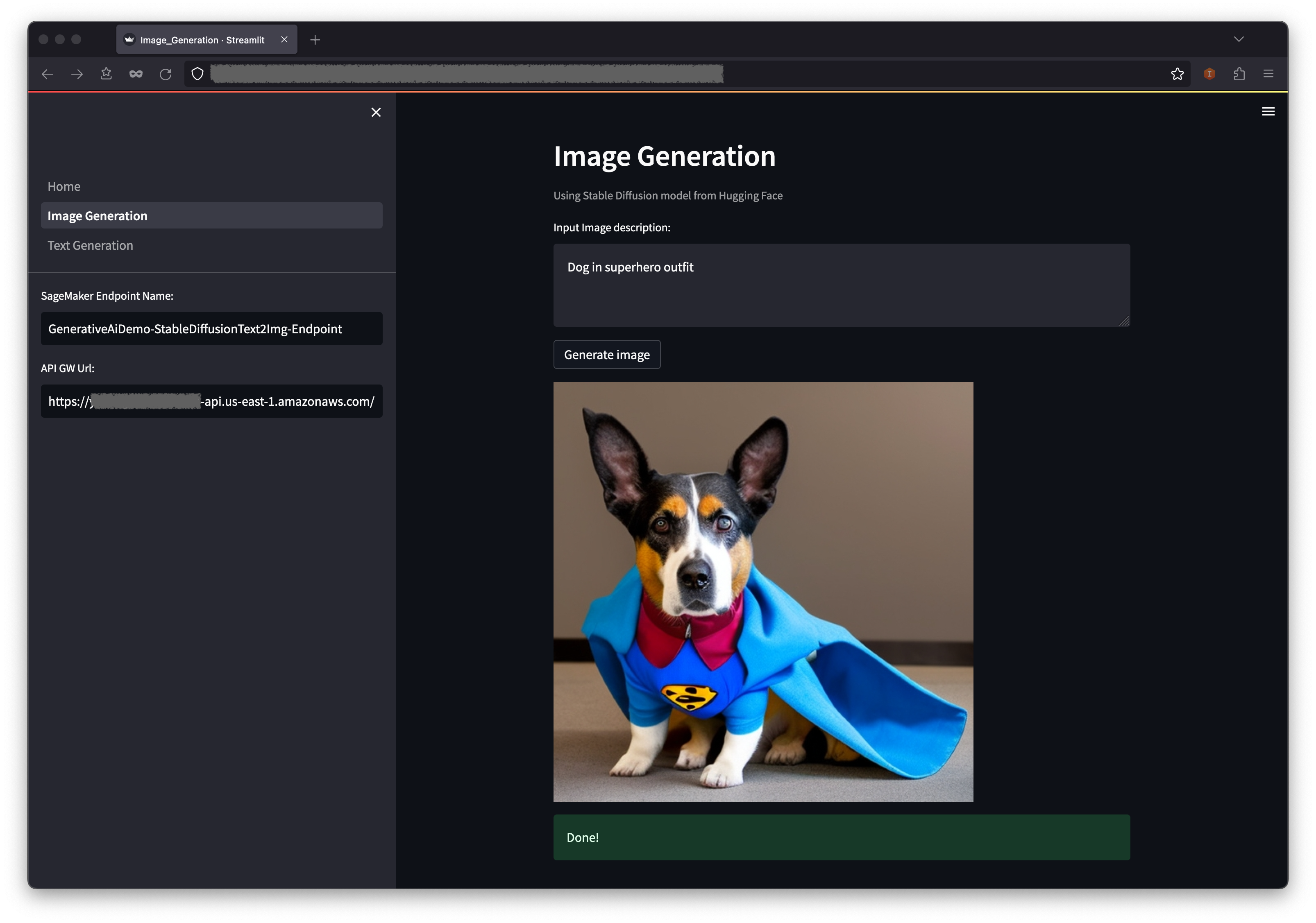
- The application will make a call to the SageMaker endpoint. It takes a few seconds. A picture with the characteristics in your image description will be displayed.

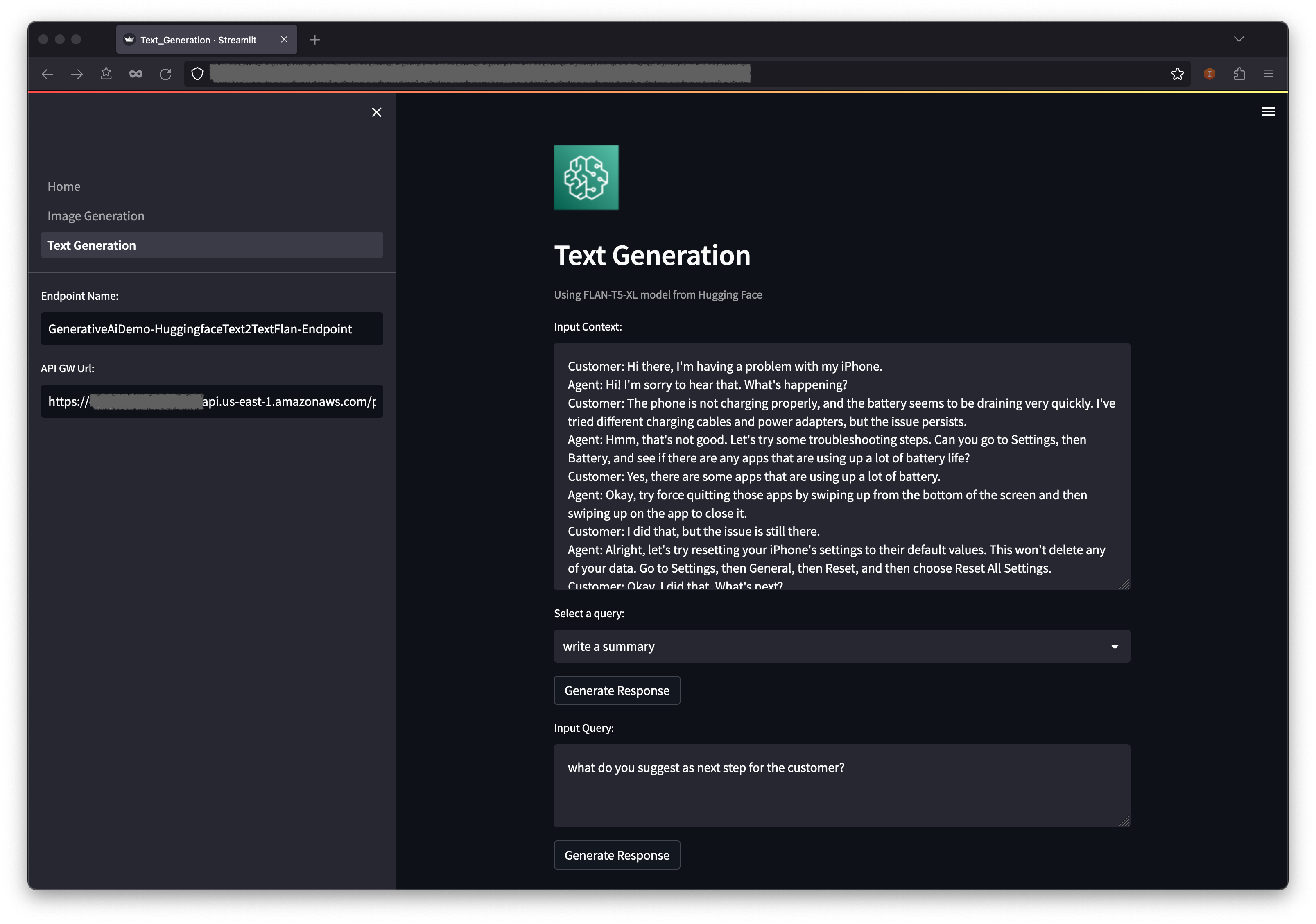
Use the text generation AI model
The second example centers around using the FLAN-T5-XL model, which is a foundation or large language model (LLM), to achieve in-context learning for text generation while also addressing a broad range of natural language understanding (NLU) and natural language generation (NLG) tasks.
Some environments might limit the number of endpoints you can launch at a time. If this is the case, you can launch one SageMaker endpoint at a time. To stop a SageMaker endpoint in the AWS CDK app, you have to destroy the deployed endpoint stack and before launching the other endpoint stack. To turn down the image generation AI model endpoint, issue the following command:
Then launch the text generation AI model endpoint stack:
Enter y at the prompts.
After the text generation model endpoint stack is launched, complete the following steps:
- Go back to the web application and choose Text Generation in the navigation pane.
- The Input Context field is pre-populated with a conversation between a customer and an agent regarding an issue with the customers phone, but you can enter your own context if you’d like.

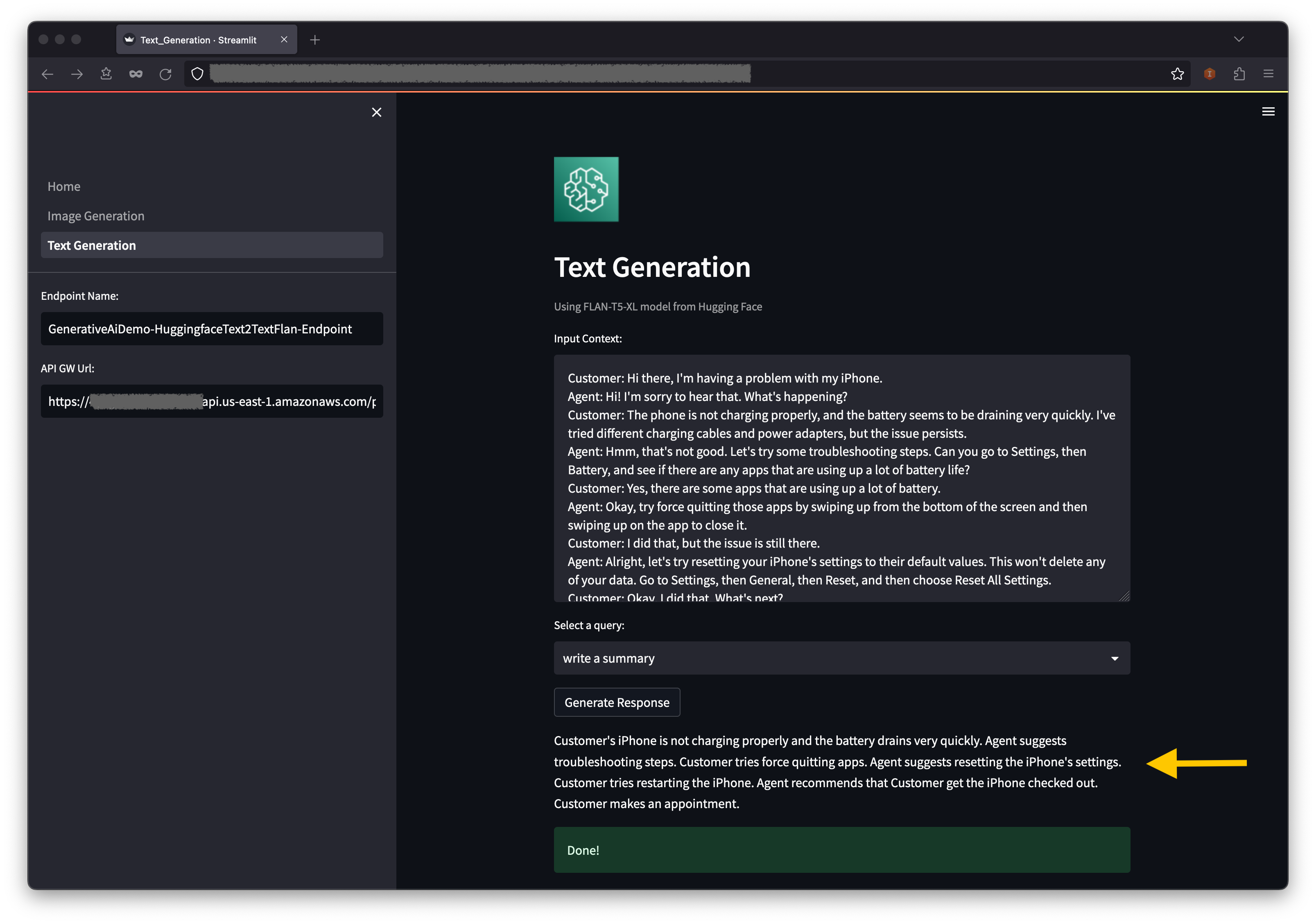
- Below the context, you will find some pre-populated queries on the drop-down menu. Choose a query and choose Generate Response.

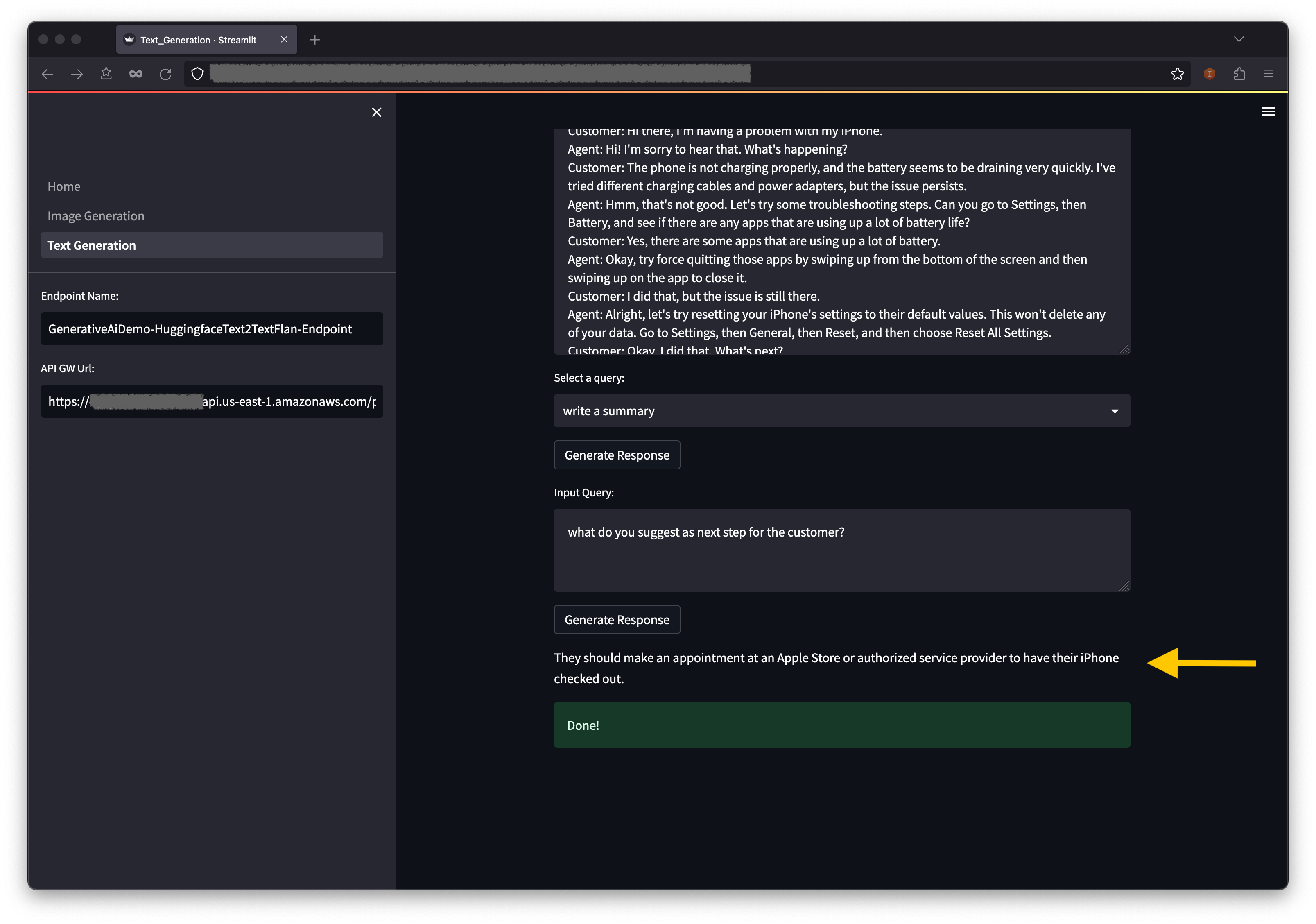
- You can also enter your own query in the Input Query field and then choose Generate Response.

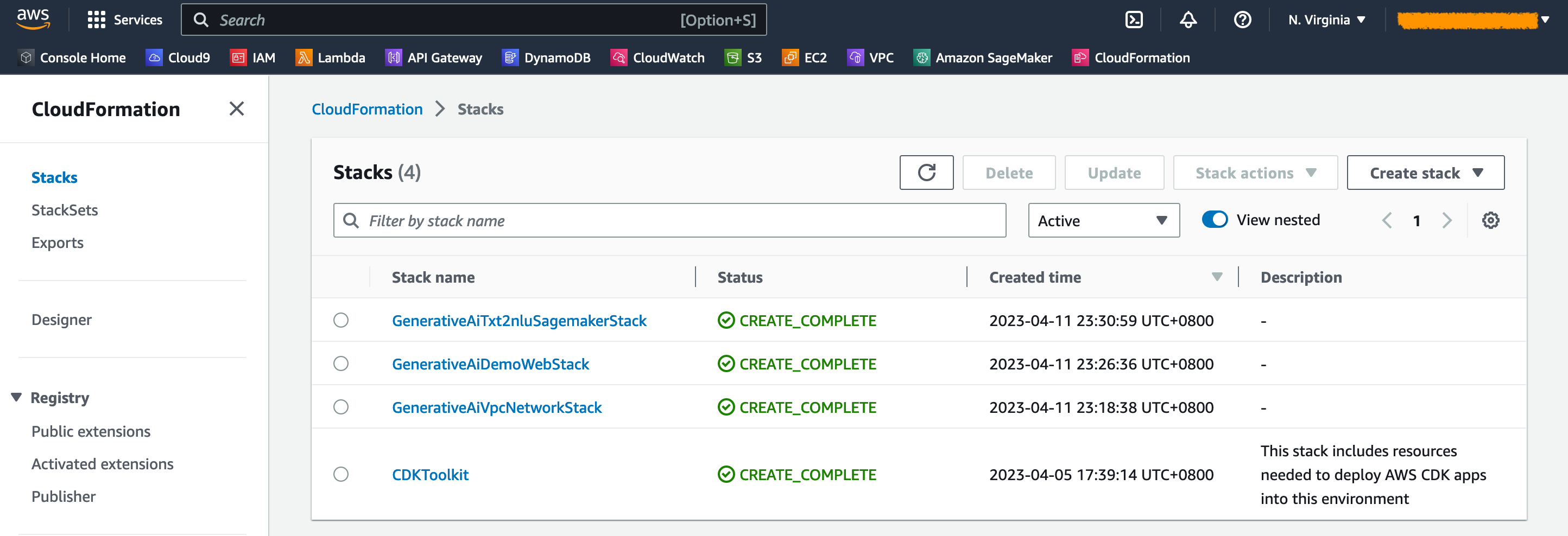
View the deployed resources on the console
On the AWS CloudFormation console, choose Stacks in the navigation pane to view the stacks deployed.
On the Amazon ECS console, you can see the clusters on the Clusters page.
On the AWS Lambda console, you can see the functions on the Functions page.
On the API Gateway console, you can see the API Gateway endpoints on the APIs page.
On the SageMaker console, you can see the deployed model endpoints on the Endpoints page.
When the stacks are launched, some parameters are generated. These are stored in the AWS Systems Manager Parameter Store. To view them, choose Parameter Store in the navigation pane on the AWS Systems Manager console.
Clean up
To avoid unnecessary cost, clean up all the infrastructure created with the following command on your workstation:
Enter y at the prompt. This step takes around 10 minutes. Check if all resources are deleted on the console. Also delete the assets S3 buckets created by the AWS CDK on the Amazon S3 console as well as the assets repositories on Amazon ECR.
Conclusion
As demonstrated in this post, you can use the AWS CDK to deploy generative AI models in JumpStart. We showed an image generation example and a text generation example using a user interface powered by Streamlit, Lambda, and API Gateway.
You can now build your generative AI projects using pre-trained AI models in JumpStart. You can also extend this project to fine-tune the foundation models for your use case and control access to API Gateway endpoints.
We invite you to test the solution and contribute to the project on GitHub. Share your thoughts on this tutorial in the comments!
License summary
This sample code is made available under a modified MIT license. See the LICENSE file for more information. Also, review the respective licenses for the stable diffusion and flan-t5-xl models on Hugging Face.
About the authors
 Hantzley Tauckoor is an APJ Partner Solutions Architecture Leader based in Singapore. He has 20 years’ experience in the ICT industry spanning multiple functional areas, including solutions architecture, business development, sales strategy, consulting, and leadership. He leads a team of Senior Solutions Architects that enable partners to develop joint solutions, build technical capabilities, and steer them through the implementation phase as customers migrate and modernize their applications to AWS.
Hantzley Tauckoor is an APJ Partner Solutions Architecture Leader based in Singapore. He has 20 years’ experience in the ICT industry spanning multiple functional areas, including solutions architecture, business development, sales strategy, consulting, and leadership. He leads a team of Senior Solutions Architects that enable partners to develop joint solutions, build technical capabilities, and steer them through the implementation phase as customers migrate and modernize their applications to AWS.
 Kwonyul Choi is a CTO at BABITALK, a Korean beauty care platform startup, based in Seoul. Prior to this role, Kownyul worked as Software Development Engineer at AWS with a focus on AWS CDK and Amazon SageMaker.
Kwonyul Choi is a CTO at BABITALK, a Korean beauty care platform startup, based in Seoul. Prior to this role, Kownyul worked as Software Development Engineer at AWS with a focus on AWS CDK and Amazon SageMaker.
 Arunprasath Shankar is a Senior AI/ML Specialist Solutions Architect with AWS, helping global customers scale their AI solutions effectively and efficiently in the cloud. In his spare time, Arun enjoys watching sci-fi movies and listening to classical music.
Arunprasath Shankar is a Senior AI/ML Specialist Solutions Architect with AWS, helping global customers scale their AI solutions effectively and efficiently in the cloud. In his spare time, Arun enjoys watching sci-fi movies and listening to classical music.
 Satish Upreti is a Migration Lead PSA and Security SME in the partner organization in APJ. Satish has 20 years of experience spanning on-premises private cloud and public cloud technologies. Since joining AWS in August 2020 as a migration specialist, he provides extensive technical advice and support to AWS partners to plan and implement complex migrations.
Satish Upreti is a Migration Lead PSA and Security SME in the partner organization in APJ. Satish has 20 years of experience spanning on-premises private cloud and public cloud technologies. Since joining AWS in August 2020 as a migration specialist, he provides extensive technical advice and support to AWS partners to plan and implement complex migrations.
Appendix: Code walkthrough
In this section, we provide an overview of the code in this project.
AWS CDK application
The main AWS CDK application is contained in the app.py file in the root directory. The project consists of multiple stacks, so we have to import the stacks:
We define our generative AI models and get the related URIs from SageMaker:
The function get_sagemaker_uris retrieves all the model information from JumpStart. See script/sagemaker_uri.py.
Then, we instantiate the stacks:
The first stack to launch is the VPC stack, GenerativeAiVpcNetworkStack. The web application stack, GenerativeAiDemoWebStack, is dependent on the VPC stack. The dependency is done through parameter passing vpc=network_stack.vpc.
See app.py for the full code.
VPC network stack
In the GenerativeAiVpcNetworkStack stack, we create a VPC with a public subnet and a private subnet spanning across two Availability Zones:
See /stack/generative_ai_vpc_network_stack.py for the full code.
Demo web application stack
In the GenerativeAiDemoWebStack stack, we launch Lambda functions and respective API Gateway endpoints through which the web application interacts with the SageMaker model endpoints. See the following code snippet:
The web application is containerized and hosted on Amazon ECS with Fargate. See the following code snippet:
See /stack/generative_ai_demo_web_stack.py for the full code.
Image generation SageMaker model endpoint stack
The GenerativeAiTxt2imgSagemakerStack stack creates the image generation model endpoint from JumpStart and stores the endpoint name in Systems Manager Parameter Store. This parameter will be used by the web application. See the following code:
See /stack/generative_ai_txt2img_sagemaker_stack.py for the full code.
NLU and text generation SageMaker model endpoint stack
The GenerativeAiTxt2nluSagemakerStack stack creates the NLU and text generation model endpoint from JumpStart and stores the endpoint name in Systems Manager Parameter Store. This parameter will also be used by the web application. See the following code:
See /stack/generative_ai_txt2nlu_sagemaker_stack.py for the full code.
Web application
The web application is located in the /web-app directory. It is a Streamlit application that is containerized as per the Dockerfile:
To learn more about Streamlit, see Streamlit documentation.
Author: Hantzley Tauckoor