

Preview – Connect Foundation Models to Your Company Data Sources with Agents for Amazon Bedrock
In July, we announced the preview of agents for Amazon Bedrock, a new capability for developers to create generative AI applications that complete tasks… Agents for Amazon Bedrock use a concept known as retrieval augmented generation (RAG) to achieve this… To create a knowledge base, specify …
In July, we announced the preview of agents for Amazon Bedrock, a new capability for developers to create generative AI applications that complete tasks. Today, I’m happy to introduce a new capability to securely connect foundation models (FMs) to your company data sources using agents.
With a knowledge base, you can use agents to give FMs in Bedrock access to additional data that helps the model generate more relevant, context-specific, and accurate responses without continuously retraining the FM. Based on user input, agents identify the appropriate knowledge base, retrieve the relevant information, and add the information to the input prompt, giving the model more context information to generate a completion.
Agents for Amazon Bedrock use a concept known as retrieval augmented generation (RAG) to achieve this. To create a knowledge base, specify the Amazon Simple Storage Service (Amazon S3) location of your data, select an embedding model, and provide the details of your vector database. Bedrock converts your data into embeddings and stores your embeddings in the vector database. Then, you can add the knowledge base to agents to enable RAG workflows.
For the vector database, you can choose between vector engine for Amazon OpenSearch Serverless, Pinecone, and Redis Enterprise Cloud. I’ll share more details on how to set up your vector database later in this post.
Primer on Retrieval Augmented Generation, Embeddings, and Vector Databases
RAG isn’t a specific set of technologies but a concept for providing FMs access to data they didn’t see during training. Using RAG, you can augment FMs with additional information, including company-specific data, without continuously retraining your model.
Continuously retraining your model is not only compute-intensive and expensive, but as soon as you’ve retrained the model, your company might have already generated new data, and your model has stale information. RAG addresses this issue by providing your model access to additional external data at runtime. Relevant data is then added to the prompt to help improve both the relevance and the accuracy of completions.
This data can come from a number of data sources, such as document stores or databases. A common implementation for document search is converting your documents, or chunks of the documents, into vector embeddings using an embedding model and then storing the vector embeddings in a vector database, as shown in the following figure.
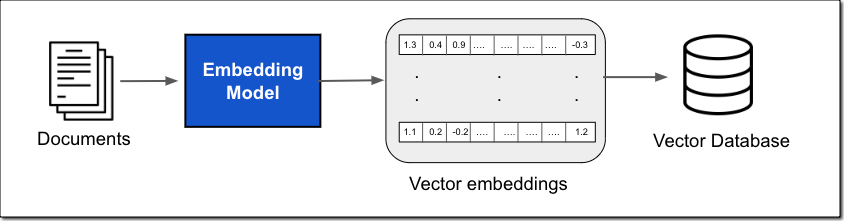
The vector embedding includes the numeric representations of text data within your documents. Each embedding aims to capture the semantic or contextual meaning of the data. Each vector embedding is put into a vector database, often with additional metadata such as a reference to the original content the embedding was created from. The vector database then indexes the vectors, which can be done using a variety of approaches. This indexing enables quick retrieval of relevant data.
Compared to traditional keyword search, vector search can find relevant results without requiring an exact keyword match. For example, if you search for “What is the cost of product X?” and your documents say “The price of product X is […]”, then keyword search might not work because “price” and “cost” are two different words. With vector search, it will return the accurate result because “price” and “cost” are semantically similar; they have the same meaning. Vector similarity is calculated using distance metrics such as Euclidean distance, cosine similarity, or dot product similarity.
The vector database is then used within the prompt workflow to efficiently retrieve external information based on an input query, as shown in the figure below.

The workflow starts with a user input prompt. Using the same embedding model, you create a vector embedding representation of the input prompt. This embedding is then used to query the database for similar vector embeddings to return the most relevant text as the query result.
The query result is then added to the prompt, and the augmented prompt is passed to the FM. The model uses the additional context in the prompt to generate the completion, as shown in the following figure.
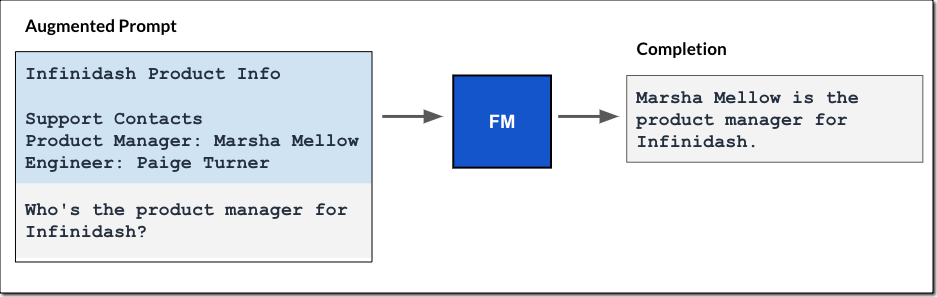
Similar to the fully managed agents experience I described in the blog post on agents for Amazon Bedrock, the knowledge base for Amazon Bedrock manages the data ingestion workflow, and agents manage the RAG workflow for you.
Get Started with Knowledge Bases for Amazon Bedrock
You can add a knowledge base by specifying a data source, such as Amazon S3, select an embedding model, such as Amazon Titan Embeddings to convert the data into vector embeddings, and a destination vector database to store the vector data. Bedrock takes care of creating, storing, managing, and updating your embeddings in the vector database.
If you add knowledge bases to an agent, the agent will identify the appropriate knowledge base based on user input, retrieve the relevant information, and add the information to the input prompt, providing the model with more context information to generate a response, as shown in the figure below. All information retrieved from knowledge bases comes with source attribution to improve transparency and minimize hallucinations.

Let me walk you through those steps in more detail.
Create a Knowledge Base for Amazon Bedrock
Let’s assume you’re a developer at a tax consulting company and want to provide users with a generative AI application—a TaxBot—that can answer US tax filing questions. You first create a knowledge base that holds the relevant tax documents. Then, you configure an agent in Bedrock with access to this knowledge base and integrate the agent into your TaxBot application.
To get started, open the Bedrock console, select Knowledge base in the left navigation pane, then choose Create knowledge base.
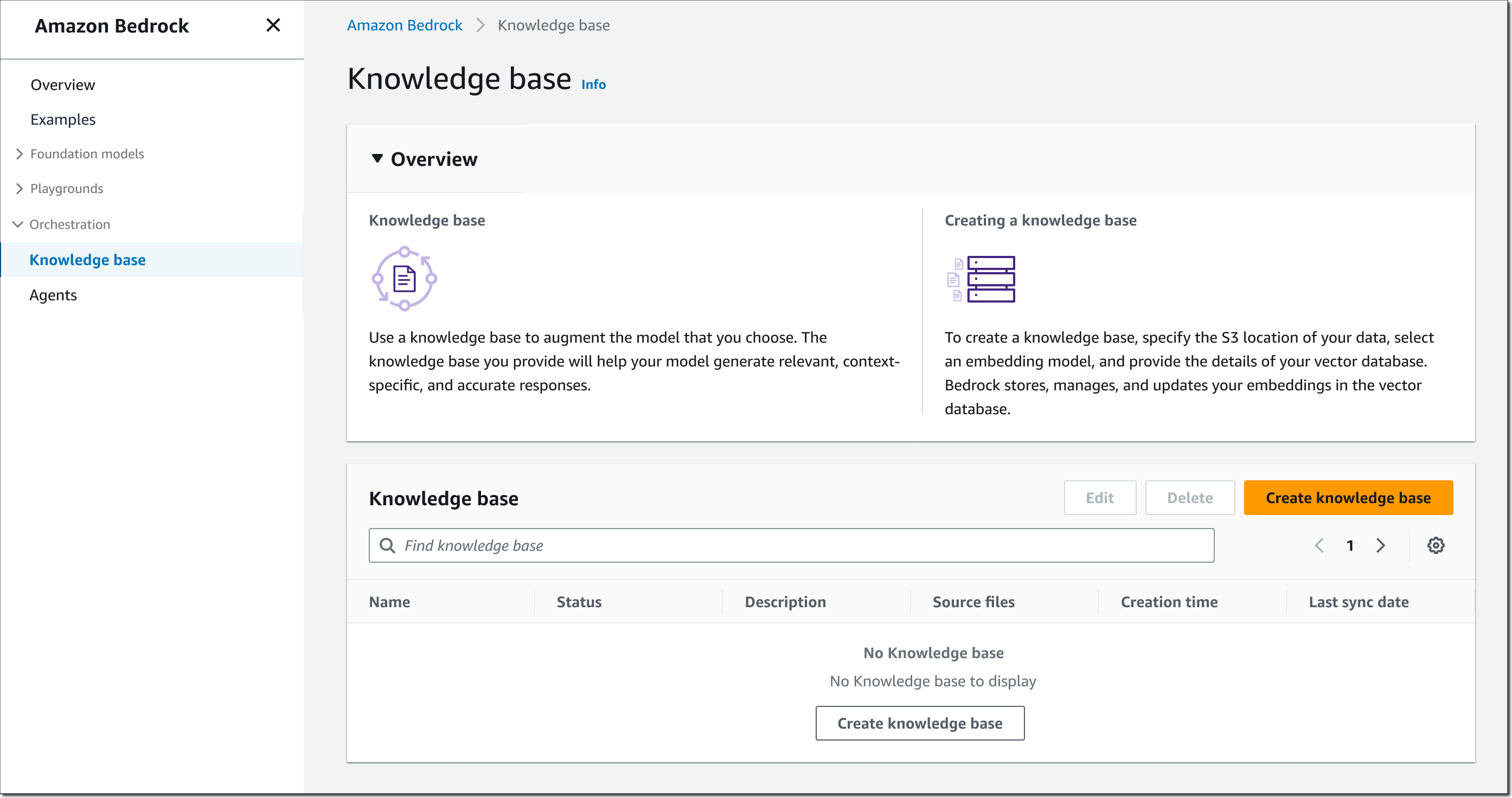
Step 1 – Provide knowledge base details. Enter a name for the knowledge base and a description (optional). You also must select an AWS Identity and Access Management (IAM) runtime role with a trust policy for Amazon Bedrock, permissions to access the S3 bucket you want the knowledge base to use, and read/write permissions to your vector database. You can also assign tags as needed.

Step 2 – Set up data source. Enter a data source name and specify the Amazon S3 location for your data. Supported data formats include .txt, .md, .html, .doc and .docx, .csv, .xls and .xlsx, and .pdf files. You can also provide an AWS Key Management Service (AWS KMS) key to allow Bedrock to decrypt and encrypt your data and another AWS KMS key for transient data storage while Bedrock is converting your data into embeddings.
Choose the embedding model, such as Amazon Titan Embeddings – Text, and your vector database. For the vector database, as mentioned earlier, you can choose between vector engine for Amazon OpenSearch Serverless, Pinecone, or Redis Enterprise Cloud.

Important note on the vector database: Amazon Bedrock is not creating a vector database on your behalf. You must create a new, empty vector database from the list of supported options and provide the vector database index name as well as index field and metadata field mappings. This vector database will need to be for exclusive use with Amazon Bedrock.
Let me show you what the setup looks like for vector engine for Amazon OpenSearch Serverless. Assuming you’ve set up an OpenSearch Serverless collection as described in the Developer Guide and this AWS Big Data Blog post, provide the ARN of the OpenSearch Serverless collection, specify the vector index name, and the vector field and metadata field mapping.
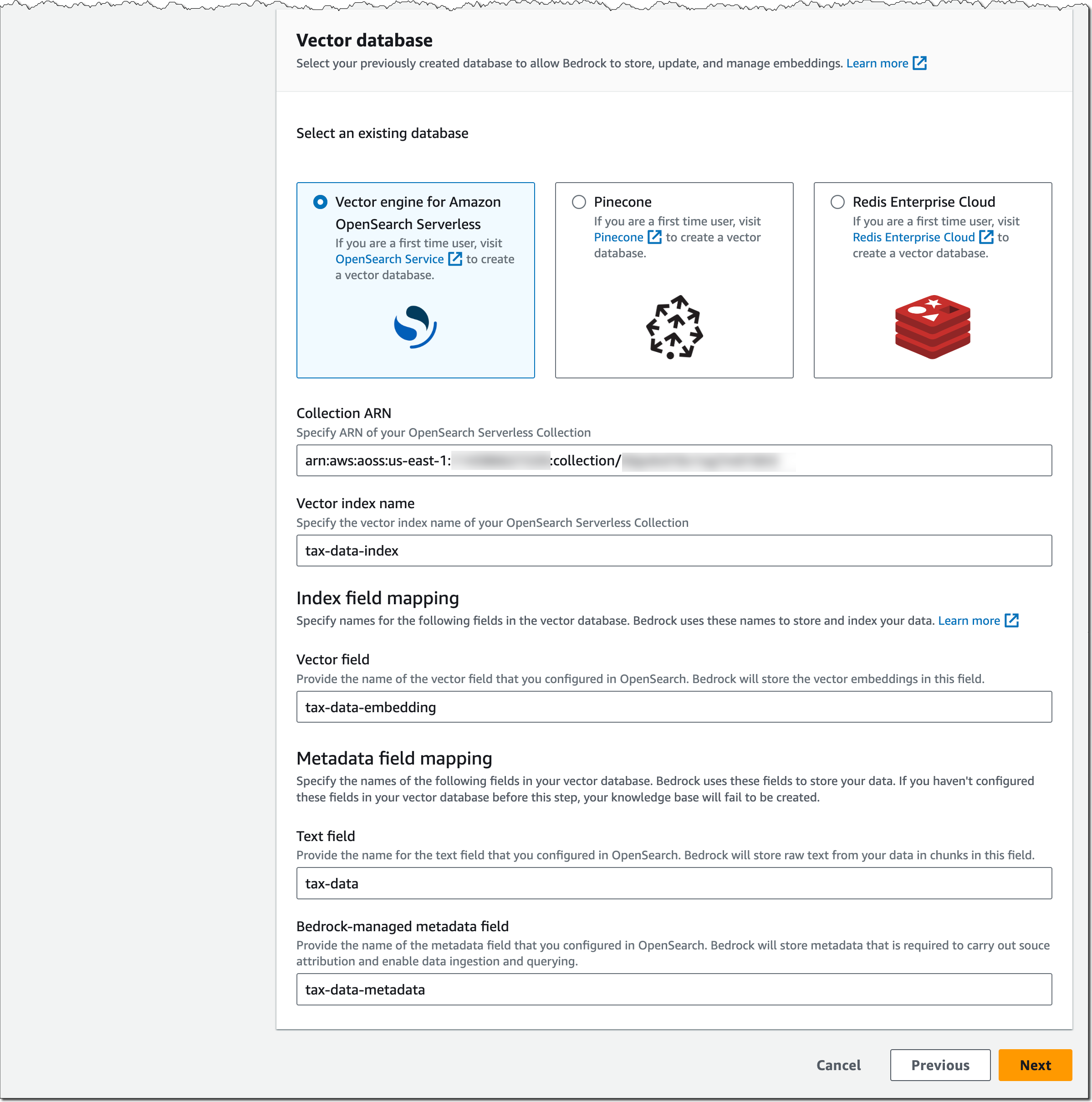
The configuration for Pinecone and Redis Enterprise Cloud is similar. Check out this Pinecone blog post and this Redis Inc. blog post for more details on how to set up and prepare their vector database for Bedrock.
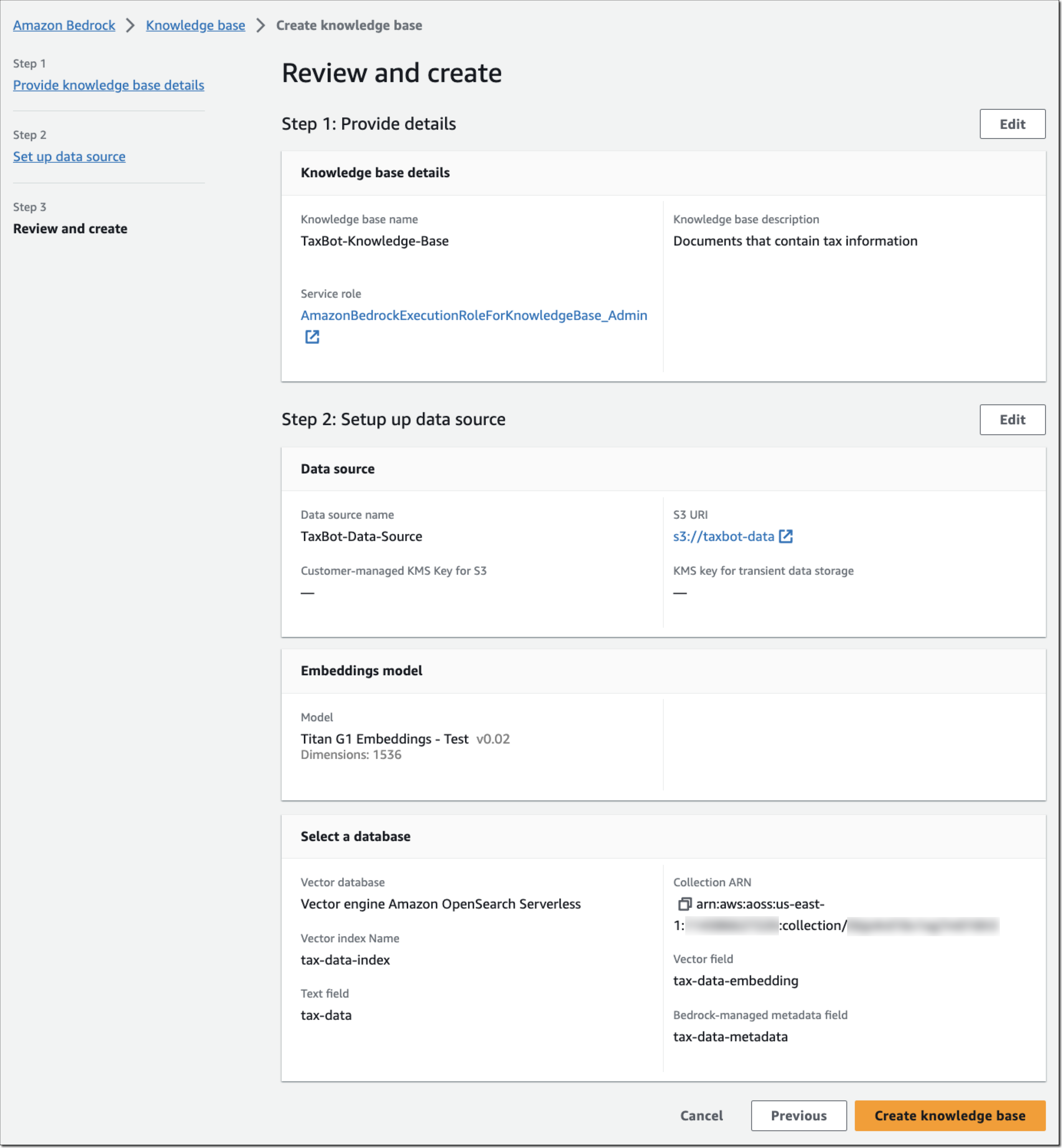
Step 3 – Review and create. Review your knowledge base configuration and choose Create knowledge base.
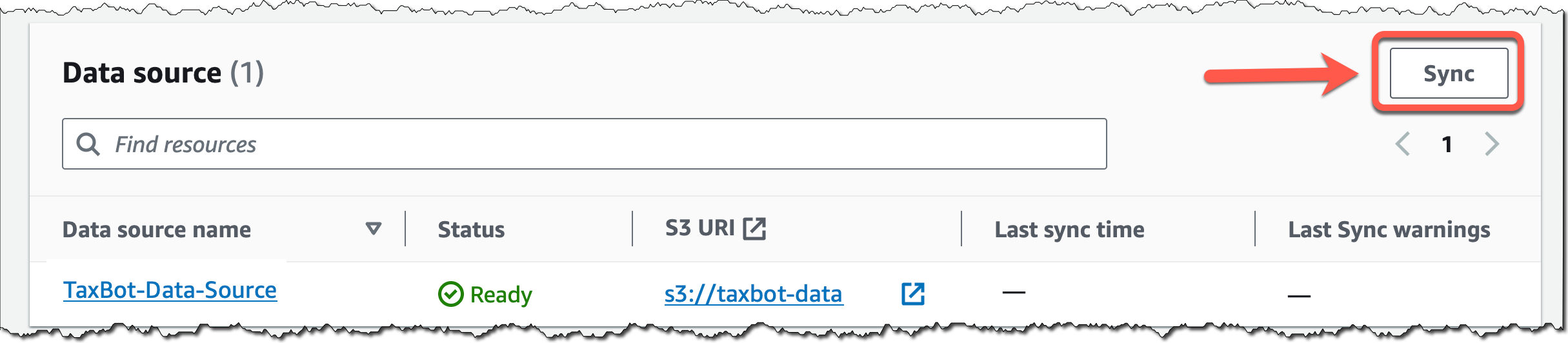
Back in the knowledge base details page, choose Sync for the newly created data source, and whenever you add new data to the data source, to start the ingestion workflow of converting your Amazon S3 data into vector embeddings and upserting the embeddings into the vector database. Depending on the amount of data, this whole workflow can take some time.
Next, I’ll show you how to add the knowledge base to an agent configuration.
Add a Knowledge Base to Agents for Amazon Bedrock
You can add a knowledge base when creating or updating an agent for Amazon Bedrock. Create an agent as described in this AWS News Blog post on agents for Amazon Bedrock.
For my tax bot example, I’ve created an agent called “TaxBot,” selected a foundation model, and provided these instructions for the agent in step 2: “You are a helpful and friendly agent that answers US tax filing questions for users.” In step 4, you can now select a previously created knowledge base and provide instructions for the agent describing when to use this knowledge base.

These instructions are very important as they help the agent decide whether or not a particular knowledge base should be used for retrieval. The agent will identify the appropriate knowledge base based on user input and available knowledge base instructions.
For my tax bot example, I added the knowledge base “TaxBot-Knowledge-Base” together with these instructions: “Use this knowledge base to answer tax filing questions.”
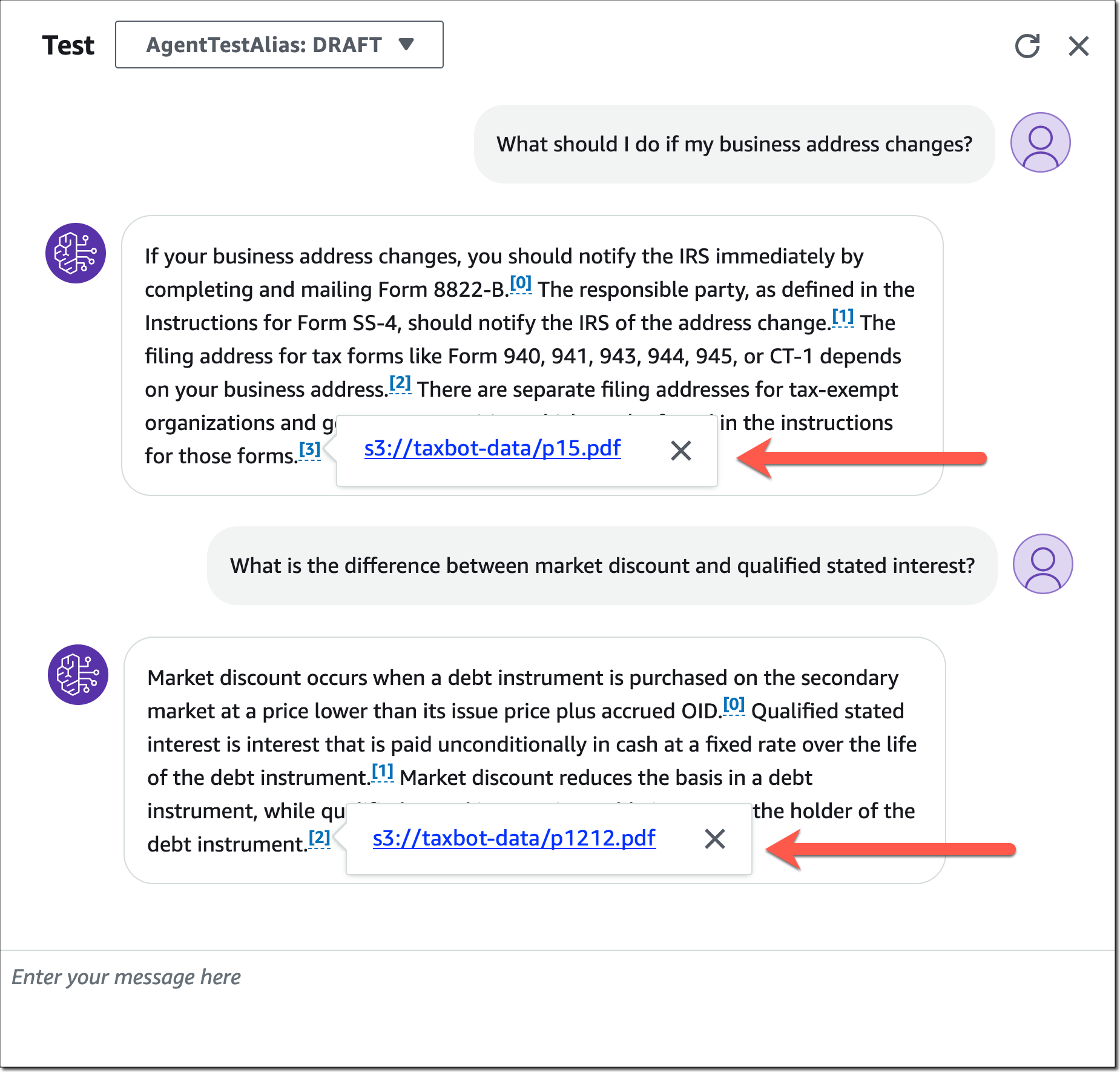
Once you’ve finished the agent configuration, you can test your agent and how it’s using the added knowledge base. Note how the agent provides a source attribution for information pulled from knowledge bases.
 Learn the Fundamentals of Generative AI
Learn the Fundamentals of Generative AI
Generative AI with large language models (LLMs) is an on-demand, three-week course for data scientists and engineers who want to learn how to build generative AI applications with LLMs, including RAG. It’s the perfect foundation to start building with Amazon Bedrock. Enroll for generative AI with LLMs today.
Sign up to Learn More about Amazon Bedrock (Preview)
Amazon Bedrock is currently available in preview. Reach out through your usual AWS support contacts if you’d like access to knowledge bases for Amazon Bedrock as part of the preview. We’re regularly providing access to new customers. To learn more, visit the Amazon Bedrock Features page and sign up to learn more about Amazon Bedrock.
— Antje
Author: Antje Barth