

A generative AI-powered solution on Amazon SageMaker to help Amazon EU Design and Construction
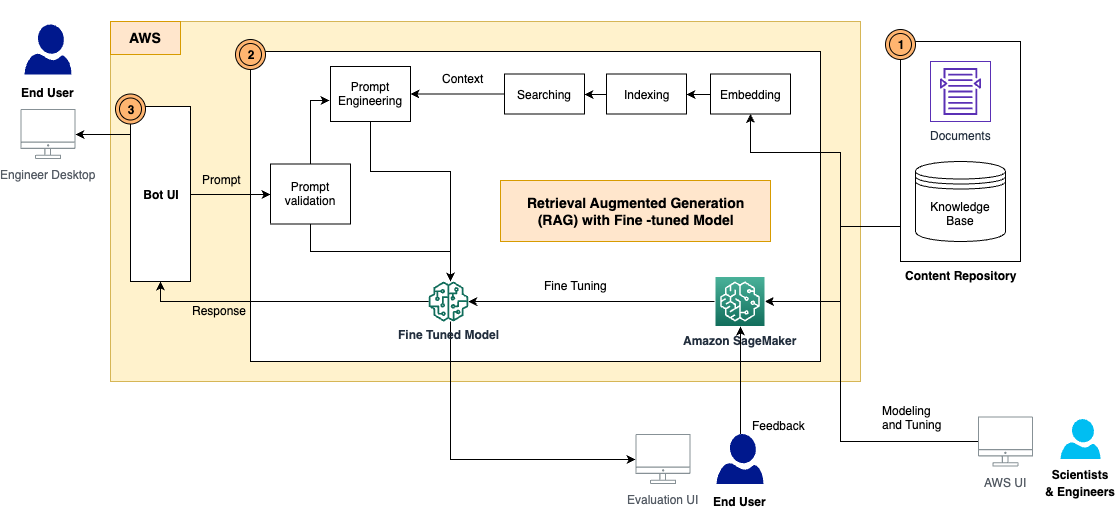
RAG searches documents through large language model (LLM) embedding and vectoring, creates the context from search results through clustering, and uses the context as an augmented prompt to inference a foundation model to get the answer… Fine-tuning adjusts and adapts the weights of the pre-train…
The Amazon EU Design and Construction (Amazon D&C) team is the engineering team designing and constructing Amazon Warehouses across Europe and the MENA region. The design and deployment processes of projects involve many types of Requests for Information (RFIs) about engineering requirements regarding Amazon and project-specific guidelines. These requests range from simple retrieval of baseline design values, to review of value engineering proposals, to analysis of reports and compliance checks. Today, these are addressed by a Central Technical Team, comprised of subject matter experts (SMEs) who can answer such highly technical specialized questions, and provide this service to all stakeholders and teams throughout the project lifecycle. The team is looking for a generative AI question answering solution to quickly get information and proceed with their engineering design. Notably, these use cases are not limited to the Amazon D&C team alone but are applicable to the broader scope of Global Engineering Services involved in project deployment. The entire range of stakeholders and teams engaged in the project lifecycle can benefit from a generative AI question-answering solution, as it will enable quick access to critical information, streamlining the engineering design and project management processes.
The existing generative AI solutions for question answering are mainly based on Retrieval Augmented Generation (RAG). RAG searches documents through large language model (LLM) embedding and vectoring, creates the context from search results through clustering, and uses the context as an augmented prompt to inference a foundation model to get the answer. This method is less efficient for the highly technical documents from Amazon D&C, which contains significant unstructured data such as Excel sheets, tables, lists, figures, and images. In this case, the question answering task works better by fine-tuning the LLM with the documents. Fine-tuning adjusts and adapts the weights of the pre-trained LLM to improve the model quality and accuracy.
To address these challenges, we present a new framework with RAG and fine-tuned LLMs. The solution uses Amazon SageMaker JumpStart as the core service for the model fine-tuning and inference. In this post, we not only provide the solution, but also discuss the lessons learned and best practices when implementing the solution in real-world use cases. We compare and contrast how different methodologies and open-source LLMs performed in our use case and discuss how to find the trade-off between model performance and compute resource costs.
Solution overview
The solution has the following components, as shown in the architecture diagram:
- Content repository – The D&C contents include a wide range of human-readable documents with various formats, such as PDF files, Excel sheets, wiki pages, and more. In this solution, we stored these contents in an Amazon Simple Storage Service (Amazon S3) bucket and used them as a knowledge base for information retrieval as well as inference. In the future, we will build integration adapters to access the contents directly from where they live.
- RAG framework with a fine-tuned LLM – This consists of the following subcomponents:
- RAG framework – This retrieves the relevant data from documents, augments the prompts by adding the retrieved data in context, and passes it to a fine-tuned LLM to generate outputs.
- Fine-tuned LLM – We constructed the training dataset from the documents and contents and conducted fine-tuning on the foundation model. After the tuning, the model learned the knowledge from the D&C contents, and therefore can respond to the questions independently.
- Prompt validation module – This measures the semantic match between the user’s prompt and the dataset for fine-tuning. If the LLM is fine-tuned to answer this question, then you can inference the fine-tuned model for a response. If not, you can use RAG to generate the response.
- LangChain – We use LangChain to build a workflow to respond to the incoming questions.
- End-user UI – This is the chatbot UI to capture users’ questions and queries, and present the answer from the RAG and LLM response.

In the next sections, we demonstrate how to create the RAG workflow and build the fine-tuned models.
RAG with foundation models by SageMaker JumpStart
RAG combines the powers of pre-trained dense retrieval and sequence-to-sequence (seq2seq) foundation models. For question answering from Amazon D&C documents, we need to prepare the following in advance:
- Embedding and indexing the documents using an LLM embedding model – We split the multiple documents into small chunks based on the document chapter and section structure, tested with the Amazon GPT-J-6B model on SageMaker JumpStart to generate the indexes, and stored the indexes in a FAISS vector store
- A pre-trained foundation model to generate responses from prompts – We tested with Flan-T5 XL, Flan-T5 XXL, and Falcon-7B models on SageMaker JumpStart
The question answering process is implemented by LangChain, which is a framework for developing applications powered by language models. The workflow in the chain contains the following steps:
- Get a question from the user.
- Perform semantic search on the indexed documents through FAISS to get the top K most-relevant document chunks.
- Define the prompt template, such as
- Augment the retrieved document chunks as the
{context}and the user question as the{question}in the prompt. - Prompt the foundation model with the constructed zero-shot prompt.
- Return the model output to the user.
We tested 125 questions on Amazon D&C requirements and specifications, and RAG returned a good response for some questions. In the following example, RAG with the Flan-T5-XXL model provided accurate response from the right sections of the documents.
| Question | What are the PLUMBING requirements for Drinking Fountains and Water Coolers? (Section 22 47 00) |
| Expected answer | The Developer shall provide water dispensing bars, floor standing at the Warehouse wall space immediately adjacent to the entrance of each toilet block serving the Warehouse and in the equivalent location adjacent to the Lockers Room toilet block. Units shall be in accordance with Amazon standard. Final numbers and placement to be agreed with Amazon prior to installation. Minimum of two units dispensing cooled and room temperature water to be provided at each location. Water Coolers or Water Bars – The Developer shall provide potable water supplies as required for remote water coolers or water bars throughout the facility. The Developer shall provide water points, drainage and any electrical services required in the Break Rooms for the Water Bars which will be provided by the Catering Contractor. |
| RAG answer (GPT-J-6B embedding with Flan-T5-XXL) | The Developer shall provide water dispensing bars, floor standing at the Warehouse wall space immediately adjacent to the entrance of each toilet block serving the Warehouse and in the equivalent location adjacent to the Lockers Room toilet block. Units shall be in accordance with Amazon standard. Final numbers and placement to be agreed with Amazon prior to installation. Minimum of two units dispensing cooled and room temperature water to be provided at each location. Water Coolers or Water Bars – The Developer shall provide potable water supplies as required for remote water coolers or water bars throughout the facility. The Developer shall provide water points, drainage and any electrical services required in the Break Rooms for the Water Bars which will be provided by the Catering Contractor. |
However, we observed that RAG doesn’t provide clear and crisp answers to the questions that are more specific and highly technical, such as guidelines, numbers, and figures. As shown in the following example, when a technical dimension output is expected, RAG can’t provide the specific answer, mainly because the embedding and searching process can’t return a concise context.
| Question | What is the Floor Heights requirement for P2 First Floor level Concrete? |
| Expected answer | 7,50 m AFFL |
| RAG answer (GPT-J-6B embedding with Flan-T5-XXL) | P2 First Floor level Concrete |
This needs to be improved because hallucination is not tolerated due to the criticality of the consequences in this use case.
Fine-tune LLMs on SageMaker
To address this challenge and improve the response quality, we take a new approach to fine-tune the LLM model using the documents for a question answering task. The model will be trained to learn the corresponding knowledge from the documents directly. Unlike RAG, it’s not dependent on whether the documents are properly embedded and indexed, and whether the semantic search algorithm is effective enough to return the most relevant contents from the vector database.
To prepare the training dataset for fine-tuning, we extract the information from the D&C documents and construct the data in the following format:
- Instruction – Describes the task and provides partial prompt
- Input – Provides further context to be consolidated into the prompt
- Response – The output of the model
During the training process, we add an instruction key, input key, and response key to each part, combine them into the training prompt, and tokenize it. Then the data is fed to a trainer in SageMaker to generate the fine-tuned model.
To accelerate the training process and reduce the cost of compute resources, we employed Parameter Efficient Fine-Tuning (PEFT) with the Low-Rank Adaptation (LoRA) technique. PEFT allows us to only fine-tune a small number of extra model parameters, and LoRA represents the weight updates with two smaller matrices through low-rank decomposition. With PEFT and LoRA on 8-bit quantization (a compression operation that further reduces the memory footprint of the model and accelerates the training and inference performance), we are able to fit the training of 125 question-answer pairs within a g4dn.x instance with a single GPU.
To prove the effectiveness of the fine-tuning, we tested with multiple LLMs on SageMaker. We selected five small-size models: Bloom-7B, Flan-T5-XL, GPT-J-6B, and Falcon-7B on SageMaker JumpStart, and Dolly-3B from Hugging Face on SageMaker.
Through 8-bit LoRA-based training, we are able to reduce the trainable parameters to no more than 5% of the full weights of each model. The training takes 10–20 epochs to converge, as shown in the following figure. For each model, the fine-tuning processes can fit on a single GPU of a g4dn.x instance, which optimized the costs of compute resources.

Inference the fine-tuned model deployed on SageMaker
We deployed the fine-tuned model along with the RAG framework in a single GPU g4dn.x node on SageMaker and compared the inference results for the 125 questions. The model performance is measured by two metrics. One is the ROUGE (Recall-Oriented Understudy for Gisting Evaluation) score, a popular natural language processing (NLP) model evaluation method that calculates the quotient of the matching words under the total count of words in the reference sentence. The other is the semantic (textual) similarity score, which measures how close the meaning of two pieces of text meanings are by using a transformer model to encode sentences to get their embeddings, then using a cosine similarity metric to compute their similarity score. From the experiments, we can see these two metrics are fairly consistent in presenting the quality of answers to the questions.
In the following table and figure, we can see that the fine-tuned Falcon-7B model provides the best quality of answering, and the Flan-T5-XL and Dolly-3B models also generate accurate responses.
| . | RAG_GPT-J-6B_Flan-T5-XL | RAG_GPT-J-6B_Flan-T5-XXL | Fine-tuned Bloom-7B1 | Fine-tuned Flan-T5-XL | Fine-tuned GPT-J-6B | Fine-tuned Dolly-3B | Fine-tuned Falcon-7B |
| ROUGE Score | 0.1938 | 0.2747 | 0.3914 | 0.4977 | 0.3740 | 0.6991 | 0.9459 |
| Semantic Similarity Score | 0.4121 | 0.4786 | 0.5666 | 0.7205 | 0.5414 | 0.8147 | 0.9774 |

The following is one example answer from the models. RAG with the Flan-T5-XL model provided a highly hallucinated response, whereas the response from RAG with the larger Flan-T5-XXL model was more relevant but still not able to cover the full expected message. Comparatively, all the fine-tuned models (Flan-T5-XL, Dolly-3B, and Falcon-7B) were able to provide the most accurate response as the expected answer.
| Question | What are the requirements for Post Grinding Sealer/Hardener? (TS0004 – section 2.8) |
| Expected answer | A Lithium based sealer/hardener will be used post any grinding/sanding procedures undertaken on the AR Floor. Please refer to TGC /0007 AR Floor SCA Procedures. Alternatives will be considered but must be approved by Amazon and the Flooring Consultant. |
| Answer from RAG (GPT-J-6B embedding with Flan-T5-XL) | The Penetrating Concrete Hardener must be discussed at the pre-pour meeting and must be approved by the Flooring Consultant and Amazon |
| Answer from RAG (GPT-J-6B embedding with Flan-T5-XXL) | The proposed compound must be discussed at the pre – pour meeting and must be approved by the Flooring Consultant and Amazon. Alternatives will be considered but must be approved by Amazon and the Flooring Consultant. |
| Answer from fine-tuned Flan-T5-XL | A Lithium based sealer/hardener will be used post any grinding/sanding procedures undertaken on the AR Floor. Please refer to TGC /0007 AR Floor SCA Procedures. Alternatives will be considered but must be approved by Amazon and the Flooring Consultant. |
| Answer from fine-tuned Dolly-3B | A Lithium based sealer/hardener will be used post any grinding/sanding procedures undertaken on the AR Floor. Please refer to TGC /0007 AR Floor SCA Procedures. Alternatives will be considered but must be approved by Amazon and the Flooring Consultant. |
| Answer from fine-tuned Falcon-7B | A Lithium based sealer/hardener will be used post any grinding/sanding procedures undertaken on the AR Floor. Please refer to TGC /0007 AR Floor SCA Procedures. Alternatives will be considered but must be approved by Amazon and the Flooring Consultant. |
Solution prototype and outcome
We developed a prototype based on the presented architecture and conducted a proof of concept to demonstrate the outcome. To take advantage of both the RAG framework and the fine-tuned LLM, and also to reduce the hallucination, we first semantically validate the incoming question. If the question is among the training data for the fine-tuning (the fine-tuned model already has the knowledge to provide a high-quality answer), then we direct the question as a prompt to inference the fine-tuned model. Otherwise, the question goes through LangChain and gets the response from RAG. The following diagram illustrates this workflow.

We tested the architecture with a test dataset of 166 questions, which contains the 125 questions used to fine-tune the model and an additional 41 questions that the fine-tuned model wasn’t trained with. The RAG framework with the embedding model and fine-tuned Falcon-7B model provided high-quality results with a ROUGE score of 0.7898 and a semantic similarity score of 0.8781. As shown in the following examples, the framework is able to generate responses to users’ questions that are well matched with the D&C documents.
The following image is our first example document.

The following screenshot shows the bot output.

The bot is also able to respond with data from a table or list and display figures for the corresponding questions. For example, we use the following document.

The following screenshot shows the bot output.

We can also use a document with a figure, as in the following example.

The following screenshot shows the bot output with text and the figure.

The following screenshot shows the bot output with just the figure.

Lessons learned and best practices
Through the solution design and experiments with multiple LLMs, we learned how to ensure the quality and performance for the question answering task in a generative AI solution. We recommend the following best practices when you apply the solution to your question answering use cases:
- RAG provides reasonable responses to engineering questions. The performance is heavily dependent on document embedding and indexing. For highly unstructured documents, you may need some manual work to properly split and augment the documents before LLM embedding and indexing.
- The index search is important to determine the RAG final output. You should properly tune the search algorithm to achieve a good level of accuracy and ensure RAG generates more relevant responses.
- Fine-tuned LLMs are able to learn additional knowledge from highly technical and unstructured documents, and possess the knowledge within the model with no dependency on the documents after training. This is especially useful for use cases where hallucination is not tolerated.
- To ensure the quality of model response, the training dataset format for fine-tuning should utilize a properly defined, task-specific prompt template. The inference pipeline should follow the same template in order to generate human-like responses.
- LLMs often come with a substantial price tag and demand considerable resources and exorbitant costs. You can use PEFT and LoRA and quantization techniques to reduce the demand of compute power and avoid high training and inference costs.
- SageMaker JumpStart provides easy-to-access pre-trained LLMs for fine-tuning, inference, and deployment. It can significantly accelerate your generative AI solution design and implementation.
Conclusion
With the RAG framework and fine-tuned LLMs on SageMaker, we are able to provide human-like responses to users’ questions and prompts, thereby enabling users to efficiently retrieve accurate information from a large volume of highly unstructured and unorganized documents. We will continue to develop the solution, such as providing a higher level of contextual response from previous interactions, and further fine-tuning the models from human feedback.
Your feedback is always welcome; please leave your thoughts and questions in the comments section.
About the authors
 Yunfei Bai is a Senior Solutions Architect at AWS. With a background in AI/ML, data science, and analytics, Yunfei helps customers adopt AWS services to deliver business results. He designs AI/ML and data analytics solutions that overcome complex technical challenges and drive strategic objectives. Yunfei has a PhD in Electronic and Electrical Engineering. Outside of work, Yunfei enjoys reading and music.
Yunfei Bai is a Senior Solutions Architect at AWS. With a background in AI/ML, data science, and analytics, Yunfei helps customers adopt AWS services to deliver business results. He designs AI/ML and data analytics solutions that overcome complex technical challenges and drive strategic objectives. Yunfei has a PhD in Electronic and Electrical Engineering. Outside of work, Yunfei enjoys reading and music.
 Burak Gozluklu is a Principal ML Specialist Solutions Architect located in Boston, MA. Burak has over 15 years of industry experience in simulation modeling, data science, and ML technology. He helps global customers adopt AWS technologies and specifically AI/ML solutions to achieve their business objectives. Burak has a PhD in Aerospace Engineering from METU, an MS in Systems Engineering, and a post-doc in system dynamics from MIT in Cambridge, MA. Burak is passionate about yoga and meditation.
Burak Gozluklu is a Principal ML Specialist Solutions Architect located in Boston, MA. Burak has over 15 years of industry experience in simulation modeling, data science, and ML technology. He helps global customers adopt AWS technologies and specifically AI/ML solutions to achieve their business objectives. Burak has a PhD in Aerospace Engineering from METU, an MS in Systems Engineering, and a post-doc in system dynamics from MIT in Cambridge, MA. Burak is passionate about yoga and meditation.
![]() Elad Dwek is a Construction Technology Manager at Amazon. With a background in construction and project management, Elad helps teams adopt new technologies and data-based processes to deliver construction projects. He identifies needs and solutions, and facilitates the development of the bespoke attributes. Elad has an MBA and a BSc in Structural Engineering. Outside of work, Elad enjoys yoga, woodworking, and traveling with his family.
Elad Dwek is a Construction Technology Manager at Amazon. With a background in construction and project management, Elad helps teams adopt new technologies and data-based processes to deliver construction projects. He identifies needs and solutions, and facilitates the development of the bespoke attributes. Elad has an MBA and a BSc in Structural Engineering. Outside of work, Elad enjoys yoga, woodworking, and traveling with his family.
Author: Yunfei Bai