

From text to dream job: Building an NLP-based job recommender at Talent.com with Amazon SageMaker
com and AWS joined forces to create a job recommendation engine using state-of-the-art natural language processing (NLP) and deep learning model training techniques with Amazon SageMaker to provide an unrivaled experience for job seekers… This post shows our joint approach to designing a job recom…
This post is co-authored by Anatoly Khomenko, Machine Learning Engineer, and Abdenour Bezzouh, Chief Technology Officer at Talent.com.
Founded in 2011, Talent.com is one of the world’s largest sources of employment. The company combines paid job listings from their clients with public job listings into a single searchable platform. With over 30 million jobs listed in more than 75 countries, Talent.com serves jobs across many languages, industries, and distribution channels. The result is a platform that matches millions of job seekers with available jobs.
Talent.com’s mission is to centralize all jobs available on the web to help job seekers find their best match while providing them with the best search experience. Its focus is on relevancy, because the order of the recommended jobs is vitally important to show the jobs most pertinent to users’ interests. The performance of Talent.com’s matching algorithm is paramount to the success of the business and a key contributor to their users’ experience. It’s challenging to predict which jobs are pertinent to a job seeker based on the limited amount of information provided, usually contained to a few keywords and a location.
Given this mission, Talent.com and AWS joined forces to create a job recommendation engine using state-of-the-art natural language processing (NLP) and deep learning model training techniques with Amazon SageMaker to provide an unrivaled experience for job seekers. This post shows our joint approach to designing a job recommendation system, including feature engineering, deep learning model architecture design, hyperparameter optimization, and model evaluation that ensures the reliability and effectiveness of our solution for both job seekers and employers. The system is developed by a team of dedicated applied machine learning (ML) scientists, ML engineers, and subject matter experts in collaboration between AWS and Talent.com.
The recommendation system has driven an 8.6% increase in clickthrough rate (CTR) in online A/B testing against a previous XGBoost-based solution, helping connect millions of Talent.com’s users to better jobs.
Overview of solution
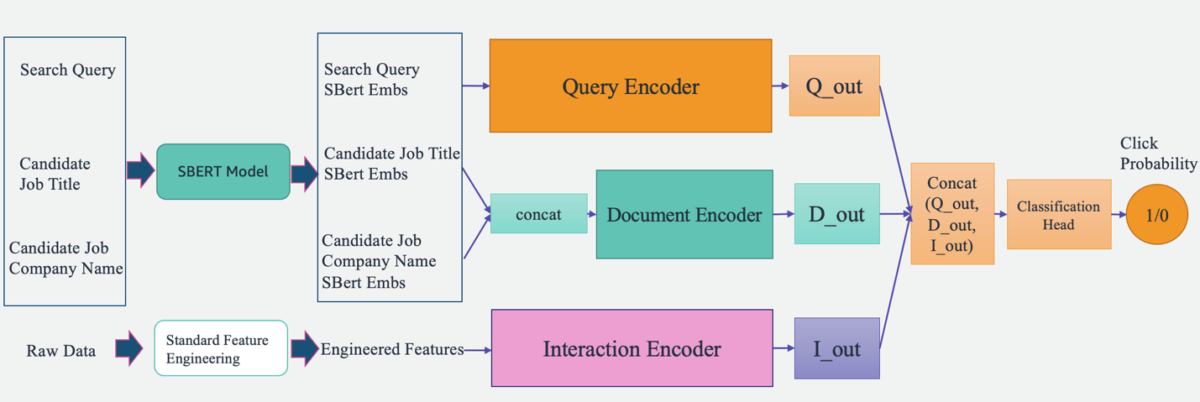
An overview of the system is illustrated in the following figure. The system takes a user’s search query as input and outputs a ranked list of jobs in order of pertinence. Job pertinence is measured by the click probability (the probability of a job seeker clicking on a job for more information).

The system includes four main components:
- Model architecture – The core of this job recommendation engine is a deep learning-based Triple Tower Pointwise model, which includes a query encoder that encodes user search queries, a document encoder that encodes the job descriptions, and an interaction encoder that processes the past user-job interaction features. The outputs of the three towers are concatenated and passed through a classification head to predict the job’s click probabilities. By training this model on search queries, job specifics, and historical user interaction data from Talent.com, this system provides personalized and highly relevant job recommendations to job seekers.
- Feature engineering – We perform two sets of feature engineering to extract valuable information from input data and feed it into the corresponding towers in the model. The two sets are standard feature engineering and fine-tuned Sentence-BERT (SBERT) embeddings. We use the standard engineered features as input into the interaction encoder and feed the SBERT derived embedding into the query encoder and document encoder.
- Model optimization and tuning – We utilize advanced training methodologies to train, test, and deploy the system with SageMaker. This includes SageMaker Distributed Data Parallel (DDP) training, SageMaker Automatic Model Tuning (AMT), learning rate scheduling, and early stopping to improve model performance and training speed. Using the DDP training framework helped speed up our model training to approximately eight times faster.
- Model evaluation – We conduct both offline and online evaluation. We evaluate the model performance with Area Under the Curve (AUC) and Mean Average Precision at K (mAP@K) in offline evaluation. During online A/B testing, we evaluate the CTR improvements.
In the following sections, we present the details of these four components.
Deep learning model architecture design
We design a Triple Tower Deep Pointwise (TTDP) model using a triple-tower deep learning architecture and the pointwise pair modeling approach. The triple-tower architecture provides three parallel deep neural networks, with each tower processing a set of features independently. This design pattern allows the model to learn distinct representations from different sources of information. After the representations from all three towers are obtained, they are concatenated and passed through a classification head to make the final prediction (0–1) on the click probability (a pointwise modeling setup).
The three towers are named based on the information they process: the query encoder processes the user search query, the document encoder processes the candidate job’s documentational contents including the job title and company name, and the interaction encoder uses relevant features extracted from past user interactions and history (discussed more in the next section).
Each of these towers plays a crucial role in learning how to recommend jobs:
- Query encoder – The query encoder takes in the SBERT embeddings derived from the user’s job search query. We enhance the embeddings through an SBERT model we fine-tuned. This encoder processes and understands the user’s job search intent, including details and nuances captured by our domain-specific embeddings.
- Document encoder – The document encoder processes the information of each job listing. Specifically, it takes the SBERT embeddings of the concatenated text from the job title and company. The intuition is that users will be more interested in candidate jobs that are more relevant to the search query. By mapping the jobs and the search queries to the same vector space (defined by SBERT), the model can learn to predict the probability of the potential jobs a job seeker will click.
- Interaction encoder – The interaction encoder deals with the user’s past interactions with job listings. The features are produced via a standard feature engineering step, which includes calculating popularity metrics for job roles and companies, establishing context similarity scores, and extracting interaction parameters from previous user engagements. It also processes the named entities identified in the job title and search queries with a pre-trained named entity recognition (NER) model.
Each tower generates an independent output in parallel, all of which are then concatenated together. This combined feature vector is then passed to predict the click probability of a job listing for a user query. The triple-tower architecture provides flexibility in capturing complex relationships between different inputs or features, allowing the model to take advantage of the strengths of each tower while learning more expressive representations for the given task.
Candidate jobs’ predicted click probabilities are ranked from high to low, generating personalized job recommendations. Through this process, we ensure that each piece of information—whether it’s the user’s search intent, job listing details, or past interactions—is fully captured by a specific tower dedicated to it. The complex relationships between them are also captured through the combination of the tower outputs.
Feature engineering
We perform two sets of feature engineering processes to extract valuable information from the raw data and feed it into the corresponding towers in the model: standard feature engineering and fine-tuned SBERT embeddings.
Standard feature engineering
Our data preparation process begins with standard feature engineering. Overall, we define four types of features:
- Popularity – We calculate popularity scores at the individual job level, occupation level, and company level. This provides a metric of how attractive a particular job or company might be.
- Textual similarity – To understand the contextual relationship between different textual elements, we compute similarity scores, including string similarity between the search query and the job title. This helps us gauge the relevance of a job opening to a job seeker’s search or application history.
- Interaction – In addition, we extract interaction features from past user engagements with job listings. A prime example of this is the embedding similarity between past clicked job titles and candidate job titles. This measure helps us understand the similarity between previous jobs a user has shown interest in vs. upcoming job opportunities. This enhances the precision of our job recommendation engine.
- Profile – Lastly, we extract user-defined job interest information from the user profile and compare it with new job candidates. This helps us understand if a job candidate matches a user’s interest.
A crucial step in our data preparation is the application of a pre-trained NER model. By implementing an NER model, we can identify and label named entities within job titles and search queries. Consequently, this allows us to compute similarity scores between these identified entities, providing a more focused and context-aware measure of relatedness. This methodology reduces the noise in our data and gives us a more nuanced, context-sensitive method of comparing jobs.
Fine-tuned SBERT embeddings
To enhance the relevance and accuracy of our job recommendation system, we use the power of SBERT, a powerful transformer-based model, known for its proficiency in capturing semantic meanings and contexts from text. However, generic embeddings like SBERT, although effective, may not fully capture the unique nuances and terminologies inherent in a specific domain such as ours, which centers around employment and job searches. To overcome this, we fine-tune the SBERT embeddings using our domain-specific data. This fine-tuning process optimizes the model to better understand and process the industry-specific language, jargon, and context, making the embeddings more reflective of our specific domain. As a result, the refined embeddings offer improved performance in capturing both semantic and contextual information within our sphere, leading to more accurate and meaningful job recommendations for our users.
The following figure illustrates the SBERT fine-tuning step.
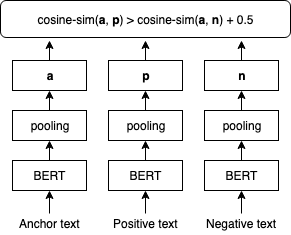
We fine-tune SBERT embeddings using TripletLoss with a cosine distance metric that learns text embedding where anchor and positive texts have a higher cosine similarity than anchor and negative texts. We use users’ search queries as anchor texts. We combine job titles and employer names as inputs to the positive and negative texts. The positive texts are sampled from job postings that the corresponding user clicked on, whereas the negative texts are sampled from job postings that the user did not click on. The following is sample implementation of the fine-tuning procedure:
Model training with SageMaker Distributed Data Parallel
We use SageMaker Distributed Data Parallel (SMDDP), a feature of the SageMaker ML platform that is built on top of PyTorch DDP. It provides an optimized environment for running PyTorch DDP training jobs on the SageMaker platform. It’s designed to significantly speed up deep learning model training. It accomplishes this by splitting a large dataset into smaller chunks and distributing them across multiple GPUs. The model is replicated on every GPU. Each GPU processes its assigned data independently, and the results are collated and synchronized across all GPUs. DDP takes care of gradient communication to keep model replicas synchronized and overlaps them with gradient computations to speed up training. SMDDP utilizes an optimized AllReduce algorithm to minimize communication between GPUs, reducing synchronization time and improving overall training speed. The algorithm adapts to different network conditions, making it highly efficient for both on-premises and cloud-based environments. In the SMDDP architecture (as shown in the following figure), distributed training is also scaled using a cluster of many nodes. This means not just multiple GPUs in a computing instance, but many instances with multiple GPUs, which further speeds up training.

For more information about this architecture, refer to Introduction to SageMaker’s Distributed Data Parallel Library.
With SMDDP, we have been able to substantially reduce the training time for our TTDP model, making it eight times faster. Faster training times mean we can iterate and improve our models more quickly, leading to better job recommendations for our users in a shorter amount of time. This efficiency gain is instrumental in maintaining the competitiveness of our job recommendation engine in a fast-evolving job market.
You can adapt your training script with the SMDDP with only three lines of code, as shown in the following code block. Using PyTorch as an example, the only thing you need to do is import the SMDDP library’s PyTorch client (smdistributed.dataparallel.torch.torch_smddp). The client registers smddp as a backend for PyTorch.
After you have a working PyTorch script that is adapted to use the distributed data parallel library, you can launch a distributed training job using the SageMaker Python SDK.
Evaluating model performance
When evaluating the performance of a recommendation system, it’s crucial to choose metrics that align closely with business goals and provide a clear understanding of the model’s effectiveness. In our case, we use the AUC to evaluate our TTDP model’s job click prediction performance and the mAP@K to assess the quality of the final ranked jobs list.
The AUC refers to the area under the receiver operating characteristic (ROC) curve. It represents the probability that a randomly chosen positive example will be ranked higher than a randomly chosen negative example. It ranges from 0–1, where 1 indicates an ideal classifier and 0.5 represents a random guess. mAP@K is a metric commonly used to assess the quality of information retrieval systems, such as our job recommender engine. It measures the average precision of retrieving the top K relevant items for a given query or user. It ranges from 0–1, with 1 indicating optimal ranking and 0 indicating the lowest possible precision at the given K value. We evaluate the AUC, mAP@1, and mAP@3. Collectively, these metrics allow us to gauge the model’s ability to distinguish between positive and negative classes (AUC) and its success at ranking the most relevant items at the top (mAP@K).
Based on our offline evaluation, the TTDP model outperformed the baseline model—the existing XGBoost-based production model—by 16.65% for AUC, 20% for mAP@1, and 11.82% for mAP@3.

Furthermore, we designed an online A/B test to evaluate the proposed system and ran the test on a percentage of the US email population for 6 weeks. In total, approximately 22 million emails were sent using the job recommended by the new system. The resulting uplift in clicks compared to the previous production model was 8.6%. Talent.com is gradually increasing the percentage to roll out the new system to its complete population and channels.
Conclusion
Creating a job recommendation system is a complex endeavor. Each job seeker has unique needs, preferences, and professional experiences that can’t be inferred from a short search query. In this post, Talent.com collaborated with AWS to develop an end-to-end deep learning-based job recommender solution that ranks lists of jobs to recommend to users. The Talent.com team truly enjoyed collaborating with the AWS team throughout the process of solving this problem. This marks a significant milestone in Talent.com’s transformative journey, as the team takes advantage of the power of deep learning to empower its business.
This project was fine-tuned using SBERT to generate text embeddings. At the time of writing, AWS introduced Amazon Titan Embeddings as part of their foundational models (FMs) offered through Amazon Bedrock, which is a fully managed service providing a selection of high-performing foundational models from leading AI companies. We encourage readers to explore the machine learning techniques presented in this blog post and leverage the capabilities provided by AWS, such as SMDDP, while making use of AWS Bedrock’s foundational models to create their own search functionalities.
References
- SBERT Training Overview
- PyTorch Distributed Overview
- The SageMaker Distributed Data Parallel Library Overview
- Introduction to SageMaker’s Distributed Data Parallel Library
About the authors
 Yi Xiang is a Applied Scientist II at the Amazon Machine Learning Solutions Lab, where she helps AWS customers across different industries accelerate their AI and cloud adoption.
Yi Xiang is a Applied Scientist II at the Amazon Machine Learning Solutions Lab, where she helps AWS customers across different industries accelerate their AI and cloud adoption.
 Tong Wang is a Senior Applied Scientist at the Amazon Machine Learning Solutions Lab, where he helps AWS customers across different industries accelerate their AI and cloud adoption.
Tong Wang is a Senior Applied Scientist at the Amazon Machine Learning Solutions Lab, where he helps AWS customers across different industries accelerate their AI and cloud adoption.
 Dmitriy Bespalov is a Senior Applied Scientist at the Amazon Machine Learning Solutions Lab, where he helps AWS customers across different industries accelerate their AI and cloud adoption.
Dmitriy Bespalov is a Senior Applied Scientist at the Amazon Machine Learning Solutions Lab, where he helps AWS customers across different industries accelerate their AI and cloud adoption.
 Anatoly Khomenko is a Senior Machine Learning Engineer at Talent.com with a passion for natural language processing matching good people to good jobs.
Anatoly Khomenko is a Senior Machine Learning Engineer at Talent.com with a passion for natural language processing matching good people to good jobs.
 Abdenour Bezzouh is an executive with more than 25 years experience building and delivering technology solutions that scale to millions of customers. Abdenour held the position of Chief Technology Officer (CTO) at Talent.com when the AWS team designed and executed this particular solution for Talent.com.
Abdenour Bezzouh is an executive with more than 25 years experience building and delivering technology solutions that scale to millions of customers. Abdenour held the position of Chief Technology Officer (CTO) at Talent.com when the AWS team designed and executed this particular solution for Talent.com.
 Dale Jacques is a Senior AI Strategist within the Generative AI Innovation Center where he helps AWS customers translate business problems into AI solutions.
Dale Jacques is a Senior AI Strategist within the Generative AI Innovation Center where he helps AWS customers translate business problems into AI solutions.
 Yanjun Qi is a Senior Applied Science Manager at the Amazon Machine Learning Solution Lab. She innovates and applies machine learning to help AWS customers speed up their AI and cloud adoption.
Yanjun Qi is a Senior Applied Science Manager at the Amazon Machine Learning Solution Lab. She innovates and applies machine learning to help AWS customers speed up their AI and cloud adoption.
Author: Yi Xiang