

Aggregating, searching, and visualizing log data from distributed sources with Amazon Athena and Amazon QuickSight
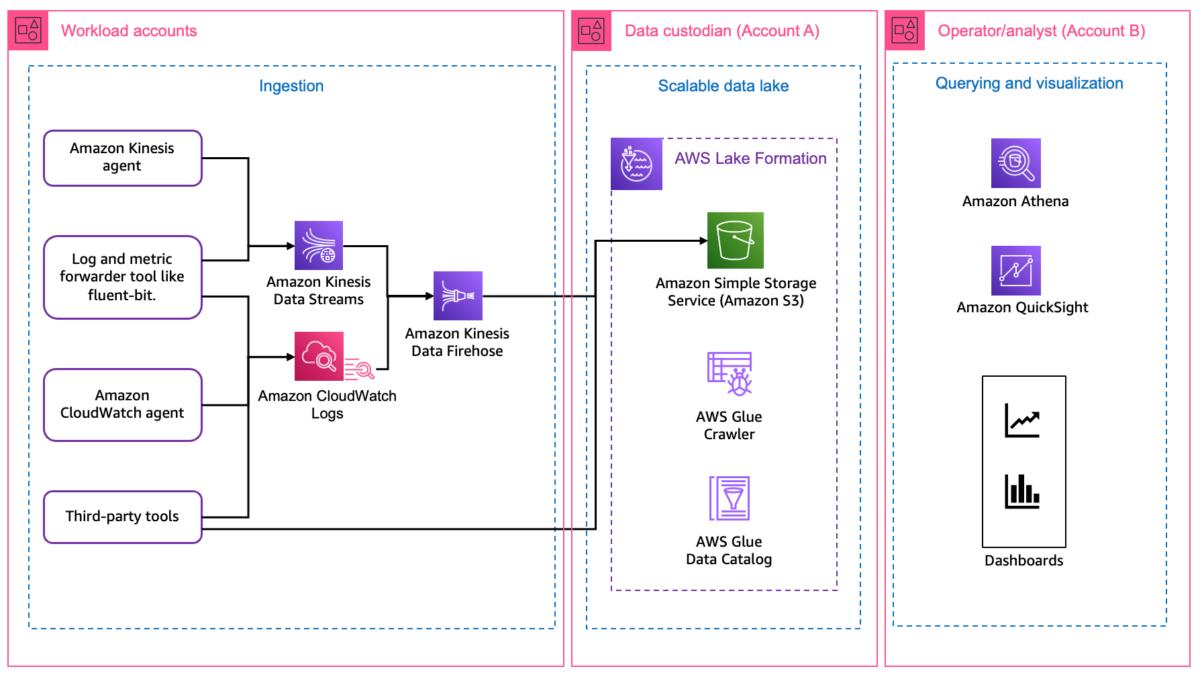
Target architecture This post guides you towards building a target architecture in line with the AWS Well-Architected Framework… The tiered and multi-account target architecture, shown in Figure 1, uses account-level isolation to separate responsibilities across the various roles identified abo…
Customers using Amazon Web Services (AWS) can use a range of native and third-party tools to build workloads based on their specific use cases. Logs and metrics are foundational components in building effective insights into the health of your IT environment. In a distributed and agile AWS environment, customers need a centralized and holistic solution to visualize the health and security posture of their infrastructure.
You can effectively categorize the members of the teams involved using the following roles:
- Executive stakeholder: Owns and operates with their support staff and has total financial and risk accountability.
- Data custodian: Aggregates related data sources while managing cost, access, and compliance.
- Operator or analyst: Uses security tooling to monitor, assess, and respond to related events such as service disruptions.
In this blog post, we focus on the data custodian role. We show you how you can visualize metrics and logs centrally with Amazon QuickSight irrespective of the service or tool generating them. We use Amazon Simple Storage Service (Amazon S3) for storage, AWS Glue for cataloguing, and Amazon Athena for querying the data and creating structured query language (SQL) views for QuickSight to consume.
Target architecture
This post guides you towards building a target architecture in line with the AWS Well-Architected Framework. The tiered and multi-account target architecture, shown in Figure 1, uses account-level isolation to separate responsibilities across the various roles identified above and makes access management more defined and specific to those roles. The workload accounts generate the telemetry around the applications and infrastructure. The data custodian account is where the data lake is deployed and collects the telemetry. The operator account is where the queries and visualizations are created.
Throughout the post, I mention AWS services that reduce the operational overhead in one or more stages of the architecture.

Figure 1: Data visualization architecture
Ingestion
Irrespective of the technology choices, applications and infrastructure configurations should generate metrics and logs that report on resource health and security. The format of the logs depends on which tool and which part of the stack is generating the logs. For example, the format of log data generated by application code can capture bespoke and additional metadata deemed useful from a workload perspective as compared to access logs generated by proxies or load balancers. For more information on types of logs and effective logging strategies, see Logging strategies for security incident response.
Amazon S3 is a scalable, highly available, durable, and secure object storage that you will use as the storage layer. To build a solution that captures events agnostic of the source, you must forward data as a stream to the S3 bucket. Based on the architecture, there are multiple tools you can use to capture and stream data into S3 buckets. Some tools support integration with S3 and directly stream data to S3. Resources like servers and virtual machines need forwarding agents such as Amazon Kinesis Agent, Amazon CloudWatch agent, or Fluent Bit.
Amazon Kinesis Data Streams provides a scalable data streaming environment. Using on-demand capacity mode eliminates the need for capacity provisioning and capacity management for streaming workloads. For log data and metric collection, you should use on-demand capacity mode, because log data generation can be unpredictable depending on the requests that are being handled by the environment. Amazon Kinesis Data Firehose can convert the format of your input data from JSON to Apache Parquet before storing the data in Amazon S3. Parquet is naturally compressed, and using Parquet native partitioning and compression allows for faster queries compared to JSON formatted objects.
Scalable data lake
Use AWS Lake Formation to build, secure, and manage the data lake to store log and metric data in S3 buckets. We recommend using tag-based access control and named resources to share the data in your data store to share data across accounts to build visualizations. Data custodians should configure access for relevant datasets to the operators who can use Athena to perform complex queries and build compelling data visualizations with QuickSight, as shown in Figure 2. For cross-account permissions, see Use Amazon Athena and Amazon QuickSight in a cross-account environment. You can also use Amazon DataZone to build additional governance and share data at scale within your organization. Note that the data lake is different to and separate from the Log Archive bucket and account described in Organizing Your AWS Environment Using Multiple Accounts.

Figure 2: Account structure
Amazon Security Lake
Amazon Security Lake is a fully managed security data lake service. You can use Security Lake to automatically centralize security data from AWS environments, SaaS providers, on-premises, and third-party sources into a purpose-built data lake that’s stored in your AWS account. Using Security Lake reduces the operational effort involved in building a scalable data lake, as the service automates the configuration and orchestration for the data lake with Lake Formation. Security Lake automatically transforms logs into a standard schema—the Open Cybersecurity Schema Framework (OCSF) — and parses them into a standard directory structure, which allows for faster queries. For more information, see How to visualize Amazon Security Lake findings with Amazon QuickSight.
Querying and visualization

Figure 3: Data sharing overview
After you’ve configured cross-account permissions, you can use Athena as the data source to create a dataset in QuickSight, as shown in Figure 3. You start by signing up for a QuickSight subscription. There are multiple ways to sign in to QuickSight; this post uses AWS Identity and Access Management (IAM) for access. To use QuickSight with Athena and Lake Formation, you first must authorize connections through Lake Formation. After permissions are in place, you can add datasets. You should verify that you’re using QuickSight in the same AWS Region as the Region where Lake Formation is sharing the data. You can do this by checking the Region in the QuickSight URL.
You can start with basic queries and visualizations as described in Query logs in S3 with Athena and Create a QuickSight visualization. Depending on the nature and origin of the logs and metrics that you want to query, you can use the examples published in Running SQL queries using Amazon Athena. To build custom analytics, you can create views with Athena. Views in Athena are logical tables that you can use to query a subset of data. Views help you to hide complexity and minimize maintenance when querying large tables. Use views as a source for new datasets to build specific health analytics and dashboards.
You can also use Amazon QuickSight Q to get started on your analytics journey. Powered by machine learning, Q uses natural language processing to provide insights into the datasets. After the dataset is configured, you can use Q to give you suggestions for questions to ask about the data. Q understands business language and generates results based on relevant phrases detected in the questions. For more information, see Working with Amazon QuickSight Q topics.
Conclusion
Logs and metrics offer insights into the health of your applications and infrastructure. It’s essential to build visibility into the health of your IT environment so that you can understand what good health looks like and identify outliers in your data. These outliers can be used to identify thresholds and feed into your incident response workflow to help identify security issues. This post helps you build out a scalable centralized visualization environment irrespective of the source of log and metric data.
This post is part 1 of a series that helps you dive deeper into the security analytics use case. In part 2, How to visualize Amazon Security Lake findings with Amazon QuickSight, you will learn how you can use Security Lake to reduce the operational overhead involved in building a scalable data lake and centralizing log data from SaaS providers, on-premises, AWS, and third-party sources into a purpose-built data lake. You will also learn how you can integrate Athena with Security Lake and create visualizations with QuickSight of the data and events captured by Security Lake.
Part 3, How to share security telemetry per Organizational Unit using Amazon Security Lake and AWS Lake Formation, dives deeper into how you can query security posture using AWS Security Hub findings integrated with Security Lake. You will also use the capabilities of Athena and QuickSight to visualize security posture in a distributed environment.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Author: Pratima Singh