

Large language model inference over confidential data using AWS Nitro Enclaves
With Nitro Enclaves, you create an isolated environment from your EC2 instance, permitting you to allocate CPU and memory resources to the enclave… This enclave is a highly restrictive virtual machine… By running code that handles sensitive data within the enclave, none of the parent’s proces…
This post is co-written with Justin Miles, Liv d’Aliberti, and Joe Kovba from Leidos.
Leidos is a Fortune 500 science and technology solutions leader working to address some of the world’s toughest challenges in the defense, intelligence, homeland security, civil, and healthcare markets. In this post, we discuss how Leidos worked with AWS to develop an approach to privacy-preserving large language model (LLM) inference using AWS Nitro Enclaves.
LLMs are designed to understand and generate human-like language, and are used in many industries, including government, healthcare, financial, and intellectual property. LLMs have broad applicability, including chatbots, content generation, language translation, sentiment analysis, question answering systems, search engines, and code generation. Introducing LLM-based inference into a system also has the potential to introduce privacy threats, including model exfiltration, data privacy violations, and unintended LLM-based service manipulation. Technical architectures need to be implemented in order to make sure that LLMs don’t expose sensitive information during inference.
This post discusses how Nitro Enclaves can help protect LLM model deployments, specifically those that use personally identifiable information (PII) or protected health information (PHI). This post is for educational purposes only and should not be used in production environments without additional controls.
Overview of LLMs and Nitro Enclaves
A potential use case is an LLM-based sensitive query chatbot designed to carry out a question and answering service containing PII and PHI. Most current LLM chatbot solutions explicitly inform users that they should not include PII or PHI when inputting questions due to security concerns. To mitigate these concerns and protect customer data, service owners rely primarily on user protections such as the following:
- Redaction – The process of identifying and obscuring sensitive information like PII in documents, texts, or other forms of content. This can be accomplished with input data before being sent to a model or an LLM trained to redact their responses automatically.
- Multi-factor authentication – A security process that requires users to provide multiple authentication methods to verify their identity to gain access to the LLM.
- Transport Layer Security (TLS) – A cryptographic protocol that provides secure communication that enhances data privacy in transit between users and the LLM service.
Although these practices enhance the security posture of the service, they are not sufficient to safeguard all sensitive user information and other sensitive information that can persist without the user’s knowledge.
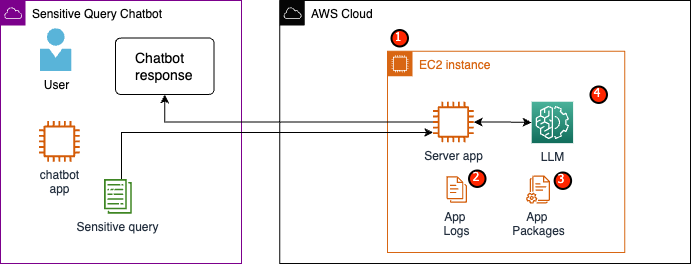
In our example use case, an LLM service is designed to answer employee healthcare benefit questions or provide a personal retirement plan. Let’s analyze the following sample architecture and identify data privacy risk areas.

Figure 1 – Data Privacy Risk Areas Diagram
The potential risk areas are as follows:
- Privileged users have access to the instance that houses the server. Unintentional or unauthorized changes to the service could result in sensitive data being exposed in unintended ways.
- Users must trust the service will not expose or retain sensitive information in application logs.
- Changes to application packages can cause changes to the service, resulting in the exposure of sensitive data.
- Privileged users with access to the instance have unrestricted access to the LLM used by the service. Changes may cause incorrect or inaccurate information being returned to users.
Nitro Enclaves provides additional isolation to your Amazon Elastic Compute Cloud (Amazon EC2) instance, safeguarding data in use from unauthorized access, including admin-level users. In the preceding architecture, it’s possible for an unintentional change to result in sensitive data to persist in plaintext and accidentally get revealed to a user who may not need to access that data. With Nitro Enclaves, you create an isolated environment from your EC2 instance, permitting you to allocate CPU and memory resources to the enclave. This enclave is a highly restrictive virtual machine. By running code that handles sensitive data within the enclave, none of the parent’s processes will be able to view enclave data.
Nitro Enclaves offers the following benefits:
- Memory and CPU Isolation – It relies on the Nitro Hypervisor to isolate the CPU and memory of the enclave from users, applications, and libraries on the parent instance. This feature helps isolate the enclave and your software, and significantly reduces the surface area for unintended events.
- Separate virtual machine – Enclaves are separated virtual machines attached to an EC2 instance to further protect and securely process highly sensitive data.
- No interactive access – Enclaves provide only secure local socket connectivity with their parent instance. They have no persistent storage, interactive access, or external networking.
- Cryptographic attestation – Nitro Enclaves offers cryptographic attestation, a process used to prove the identity of an enclave and verify that only authorized code is running in your enclave.
- AWS integration – Nitro Enclaves is integrated with AWS Key Management Service (AWS KMS), allowing you to decrypt files that have been encrypted using AWS KMS inside the enclave. AWS Certificate Manager (ACM) for Nitro Enclaves allows you to use public and private SSL/TLS certificates with your web applications and servers running on EC2 instances with Nitro Enclaves.
You can use these features provided by Nitro Enclaves to help mitigate risks associated with PII and PHI data. We recommend including Nitro Enclaves in an LLM service when handling sensitive user data.
Solution overview
Let’s examine the architecture of the example service, now including Nitro Enclaves. By incorporating Nitro Enclaves, as shown in the following figure, the LLM becomes a more secure chatbot for handling PHI or PII data.

Figure 2 – Solution Overview Diagram
User data, including PII, PHI, and questions, remains encrypted throughout the request-response process when the application is hosted within an enclave. The steps carried out during the inference are as follows:
- The chatbot app generates temporary AWS credentials and asks the user to input a question. The question, which may contain PII or PHI, is then encrypted via AWS KMS. The encrypted user input is combined with the temporary credentials to create the encrypted request.
- The encrypted data is sent to an HTTP server hosted by Flask as a POST request. Before accepting sensitive data, this endpoint should be configured for HTTPs.
- The client app receives the POST request and forwards it through a secure local channel (for example, vsock) to the server app running inside Nitro Enclaves.
- The Nitro Enclaves server app uses the temporary credentials to decrypt the request, queries the LLM, and generates the response. The model-specific settings are stored within the enclaves and are protected with cryptographic attestation.
- The server app uses the same temporary credentials to encrypt the response.
- The encrypted response is returned back to the chatbot app through the client app as a response from the POST request.
- The chatbot app decrypts the response using their KMS key and displays the plaintext to the user.
Prerequisites
Before we get started, you need the following prerequisites to deploy the solution:
Configure an EC2 instance
Complete the following steps to configure an EC2 instance:
- Launch an r5.8xlarge EC2 instance using the amzn2-ami-kernel-5.10-hvm-2.0.20230628.0-x86_64-gp2 AMI with Nitro Enclaves enabled.
- Install the Nitro Enclaves CLI to build and run Nitro Enclaves applications:
sudo amazon-linux-extras install aws-nitro-enclaves-cli -ysudo yum install aws-nitro-enclaves-cli-devel -y
- Verify the installation of the Nitro Enclaves CLI:
nitro-cli –version- The version used in this post is 1.2.2
- Install Git and Docker to build Docker images and download the application from GitHub. Add your instance user to the Docker group (<USER> is your IAM instance user):
sudo yum install git -ysudo usermod -aG ne <USER>sudo usermod -aG docker <USER>sudo systemctl start docker && sudo systemctl enable docker
- Start and enable the Nitro Enclaves allocator and vsock proxy services:
sudo systemctl start nitro-enclaves-allocator.service && sudo systemctl enable nitro-enclaves-allocator.servicesudo systemctl start nitro-enclaves-vsock-proxy.service && sudo systemctl enable nitro-enclaves-vsock-proxy.service
Nitro Enclaves uses a local socket connection called vsock to create a secure channel between the parent instance and the enclave.
After all the services are started and enabled, restart the instance to verify that all of the user groups and services are running correctly:
sudo shutdown -r now
Configure the Nitro Enclaves allocator service
Nitro Enclaves is an isolated environment that designates a portion of the instance CPU and memory to run the enclave. With the Nitro Enclaves allocator service, you can indicate how many CPUs and how much memory will be taken from the parent instance to run the enclave.
Modify the enclave’s reserved resources using a text editor (for our solution, we allocate 8 CPU and 70,000 MiB memory to provide enough resources):
vi /etc/nitro_enclaves/allocatory.yaml

Figure 3 – AWS Nitro Enclaves Allocator Service Configuration
Clone the project
After you configure the EC2 instance, you can download the code to run the sensitive chatbot with an LLM inside of Nitro Enclaves.
You need to update the server.py file with the appropriate KMS key ID that you created in the beginning to encrypt the LLM response.
- Clone the GitHub project:
cd ~/ && git clone https://<THE_REPO.git>
- Navigate to the project folder to build the
enclave_baseDocker image that contains the Nitro Enclaves Software Development Kit (SDK) for cryptographic attestation documents from the Nitro Hypervisor (this step can take up to 15 minutes):cd /nitro_llm/enclave_basedocker build ./ -t “enclave_base”
Save the LLM in the EC2 Instance
We are using the open-source Bloom 560m LLM for natural language processing to generate responses. This model is not fine-tuned to PII and PHI, but demonstrates how an LLM can live inside of an enclave. The model also needs to be saved on the parent instance so that it can be copied into the enclave via the Dockerfile.
- Navigate to the project:
cd /nitro_llm
- Install the necessary requirements to save the model locally:
pip3 install requirements.txt
- Run the
save_model.pyapp to save the model within the/nitro_llm/enclave/bloomdirectory:python3 save_model.py
Build and run the Nitro Enclaves image
To run Nitro Enclaves, you need to create an enclave image file (EIF) from a Docker image of your application. The Dockerfile located in the enclave directory contains the files, code, and LLM that will run inside of the enclave.
Building and running the enclave will take multiple minutes to complete.
- Navigate to the root of the project:
cd /nitro_llm
- Build the enclave image file as
enclave.eif:nitro-cli build-enclave --docker-uri enclave:latest --output-file enclave.eif

Figure 4 – AWS Nitro Enclaves Build Result
When the enclave is built, a series of unique hashes and platform configuration registers (PCRs) will be created. The PCRs are a contiguous measurement to prove the identity of the hardware and application. These PCRs will be required for cryptographic attestation and used during the KMS key policy update step.
- Run the enclave with the resources from the
allocator.service(adding the--attach-consoleargument at the end will run the enclave in debug mode):nitro-cli run-enclave --cpu-count 8 --memory 70000 --enclave-cid 16 --eif-path enclave.eif
You need to allocate at least four times the EIF file size. This can be modified in the allocator.service from previous steps.
- Verify the enclave is running with the following command:
nitro-cli describe-enclaves

Figure 5 – AWS Nitro Enclave Describe Command
Update the KMS key policy
Complete the following steps to update your KMS key policy:
- On the AWS KMS console, choose Customer managed keys in the navigation pane.
- Search for the key that you generated as a prerequisite.
- Choose Edit on the key policy.
- Update the key policy with the following information:
- Your account ID
- Your IAM user name
- The updated Cloud9 environment instance role
- Actions
kms:Encryptandkms:Decrypt - Enclave PCRs (for example, PCR0, PCR1, PCR2) to your key policy with a condition statement
See the following key policy code:
Save the chatbot app
To mimic a sensitive query chatbot application that lives outside of the AWS account, you need to save the chatbot.py app and run it inside the Cloud9 environment. Your Cloud9 environment will use its instance role for temporary credentials to disassociate permissions from the EC2 running the enclave. Complete the following steps:
- On the Cloud9 console, open the environment you created.
- Copy the following code into a new file like
chatbot.pyinto the main directory. - Install the required modules:
pip install boto3Pip install requests
- On the Amazon EC2 console, note the IP associated with your Nitro Enclaves instance.
- Update the URL variable in
http://<ec2instanceIP>:5001.
- Run the chatbot application:
python3 chat.py
When it’s running, the terminal will ask for the user input and follow the architectural diagram from earlier to generate a secure response.
Run the private question and answer chatbot
Now that Nitro Enclaves is up and running on the EC2 instance, you can more securely ask your chatbot PHI and PII questions. Let’s look at an example.
Within the Cloud9 environment, we ask our chatbot a question and provide our user name.
Figure 6 – Asking the Chat Bot a Question
AWS KMS encrypts the question, which looks like the following screenshot.

Figure 7 – Encrypted Question
It is then sent to the enclave and asked of the secured LLM. The question and response of the LLM will look like the following screenshot (the result and encrypted response are visible inside the enclave only in debug mode).

Figure 8 – Response from LLM
The result is then encrypted using AWS KMS and returned to the Cloud9 environment to be decrypted.
Figure 9 – Final Decrypted Response
Clean up
Complete the following steps to clean up your resources:
- Stop the EC2 instance created to house your enclave.
- Delete the Cloud9 environment.
- Delete the KMS key.
- Remove the EC2 instance role and IAM user permissions.
Conclusion
In this post, we showcased how to use Nitro Enclaves to deploy an LLM question and answering service that more securely sends and receives PII and PHI information. This was deployed on Amazon EC2, and the enclaves are integrated with AWS KMS restricting access to a KMS key, so only Nitro Enclaves and the end-user are allowed to use the key and decrypt the question.
If you’re planning to scale this architecture to support larger workloads, make sure the model selection process matches your model requirements with EC2 resources. Additionally, you must consider the maximum request size and what impact that will have on the HTTP server and inference time against the model. Many of these parameters are customizable through the model and HTTP server settings.
The best way to determine the specific settings and requirements for your workload is through testing with a fine-tuned LLM. Although this post only included natural language processing of sensitive data, you can modify this architecture to support alternate LLMs supporting audio, computer vision, or multi-modalities. The same security principles highlighted here can be applied to data in any format. The resources used to build this post are available on the GitHub repo.
Share how you are going to adapt this solution for your environment in the comments section.
About the Authors
Justin Miles is a cloud engineer within the Leidos Digital Modernization Sector under the Office of Technology. In his spare time, he enjoys golfing and traveling.
Liv d’Aliberti is a researcher within the Leidos AI/ML Accelerator under the Office of Technology. Their research focuses on privacy-preserving machine learning.
Chris Renzo is a Sr. Solution Architect within the AWS Defense and Aerospace organization. Outside of work, he enjoys a balance of warm weather and traveling.
Joe Kovba is a Vice President within the Leidos Digital Modernization Sector. In his free time, he enjoys refereeing football games and playing softball.
Author: Chris Renzo