

Cost-effective document classification using the Amazon Titan Multimodal Embeddings Model
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats… Manually processing these documents to classify and extract information remains expensive, error prone, and difficult to scale… Advances in generative artificial intellige…
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Manually processing these documents to classify and extract information remains expensive, error prone, and difficult to scale. Advances in generative artificial intelligence (AI) have given rise to intelligent document processing (IDP) solutions that can automate the document classification, and create a cost-effective classification layer capable of handling diverse, unstructured enterprise documents.
Categorizing documents is an important first step in IDP systems. It helps you determine the next set of actions to take depending on the type of document. For example, during the claims adjudication process, the accounts payable team receives the invoice, whereas the claims department manages the contract or policy documents. Traditional rule engines or ML-based classification can classify the documents, but often reach a limit on types of document formats and support for the dynamic addition of a new classes of document. For more information, see Amazon Comprehend document classifier adds layout support for higher accuracy.
In this post, we discuss document classification using the Amazon Titan Multimodal Embeddings model to classify any document types without the need for training.
Amazon Titan Multimodal Embeddings
Amazon recently introduced Titan Multimodal Embeddings in Amazon Bedrock. This model can create embeddings for images and text, enabling the creation of document embeddings to be used in new document classification workflows.
It generates optimized vector representations of documents scanned as images. By encoding both visual and textual components into unified numerical vectors that encapsulate semantic meaning, it enables rapid indexing, powerful contextual search, and accurate classification of documents.
As new document templates and types emerge in business workflows, you can simply invoke the Amazon Bedrock API to dynamically vectorize them and append to their IDP systems to rapidly enhance document classification capabilities.
Solution overview
Let’s examine the following document classification solution with the Amazon Titan Multimodal Embeddings model. For optimal performance, you should customize the solution to your specific use case and existing IDP pipeline setup.
This solution classifies documents using vector embedding semantic search by matching an input document to an already indexed gallery of documents. We use the following key components:
- Embeddings – Embeddings are numerical representations of real-world objects that machine learning (ML) and AI systems use to understand complex knowledge domains like humans do.
- Vector databases – Vector databases are used to store embeddings. Vector databases efficiently index and organize the embeddings, enabling fast retrieval of similar vectors based on distance metrics like Euclidean distance or cosine similarity.
- Semantic search – Semantic search works by considering the context and meaning of the input query and its relevance to the content being searched. Vector embeddings are an effective way to capture and retain the contextual meaning of text and images. In our solution, when an application wants to perform a semantic search, the search document is first converted into an embedding. The vector database with relevant content is then queried to find the most similar embeddings.
In the labeling process, a sample set of business documents like invoices, bank statements, or prescriptions are converted into embeddings using the Amazon Titan Multimodal Embeddings model and stored in a vector database against predefined labels. The Amazon Titan Multimodal Embedding model was trained using the Euclidean L2 algorithm and therefore for best results the vector database used should support this algorithm.
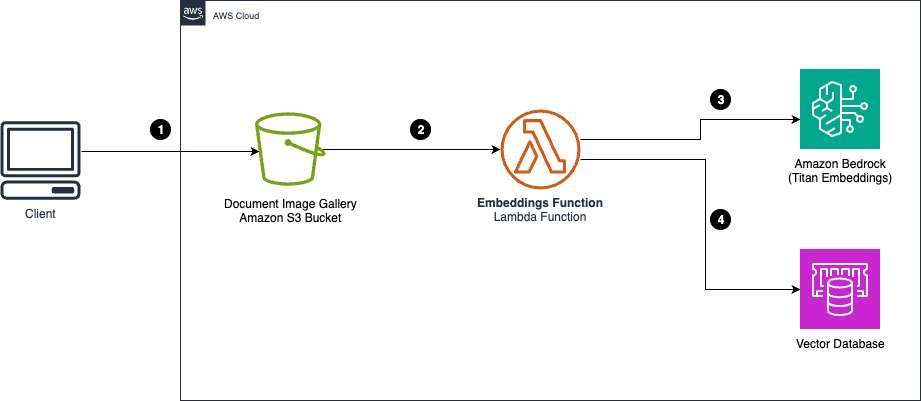
The following architecture diagram illustrates how you can use the Amazon Titan Multimodal Embeddings model with documents in an Amazon Simple Storage Service (Amazon S3) bucket for image gallery creation.
The workflow consists of the following steps:
- A user or application uploads a sample document image with classification metadata to a document image gallery. An S3 prefix or S3 object metadata can be used to classify gallery images.
- An Amazon S3 object notification event invokes the embedding AWS Lambda function.
- The Lambda function reads the document image and translates the image into embeddings by calling Amazon Bedrock and using the Amazon Titan Multimodal Embeddings model.
- Image embeddings, along with document classification, are stored in the vector database.

When a new document needs classification, the same embedding model is used to convert the query document into an embedding. Then, a semantic similarity search is performed on the vector database using the query embedding. The label retrieved against the top embedding match will be the classification label for the query document.
The following architecture diagram illustrates how to use the Amazon Titan Multimodal Embeddings model with documents in an S3 bucket for image classification.
The workflow consists of the following steps:
- Documents that require classification are uploaded to an input S3 bucket.
- The classification Lambda function receives the Amazon S3 object notification.
- The Lambda function translates the image to an embedding by calling the Amazon Bedrock API.
- The vector database is searched for a matching document using semantic search. Classification of the matching document is used to classify the input document.
- The input document is moved to the target S3 directory or prefix using the classification retrieved from the vector database search.

To help you test the solution with your own documents, we have created an example Python Jupyter notebook, which is available on GitHub.
Prerequisites
To run the notebook, you need an AWS account with appropriate AWS Identity and Access Management (IAM) permissions to call Amazon Bedrock. Additionally, on the Model access page of the Amazon Bedrock console, make sure that access is granted for the Amazon Titan Multimodal Embeddings model.
Implementation
In the following steps, replace each user input placeholder with your own information:
- Create the vector database. In this solution, we use an in-memory FAISS database, but you could use an alternative vector database. Amazon Titan’s default dimension size is 1024.
- After the vector database is created, enumerate over the sample documents, creating embeddings of each and store those into the vector database
- Test with your documents. Replace the folders in the following code with your own folders that contain known document types:
- Using the Boto3 library, call Amazon Bedrock. The variable
inputImageB64is a base64 encoded byte array representing your document. The response from Amazon Bedrock contains the embeddings.
- Add the embeddings to the vector database, with a class ID that represents a known document type:
- With the vector database populated with images (representing our gallery), you can uncover similarities with new documents. For example, the following is the syntax used for search. The k=1 tells FAISS to return the top 1 match.
In addition, the Euclidean L2 distance between the image on hand and the found image is also returned. If the image is an exact match, this value would be 0. The larger this value is, the further apart the images are in similarity.
Additional considerations
In this section, we discuss additional considerations for using the solution effectively. This includes data privacy, security, integration with existing systems, and cost estimates.
Data privacy and security
The AWS shared responsibility model applies to data protection in Amazon Bedrock. As described in this model, AWS is responsible for protecting the global infrastructure that runs all of the AWS Cloud. Customers are responsible for maintaining control over their content that is hosted on this infrastructure. As a customer, you are responsible for the security configuration and management tasks for the AWS services that you use.
Data protection in Amazon Bedrock
Amazon Bedrock avoids using customer prompts and continuations to train AWS models or share them with third parties. Amazon Bedrock doesn’t store or log customer data in its service logs. Model providers don’t have access to Amazon Bedrock logs or access to customer prompts and continuations. As a result, the images used for generating embeddings through the Amazon Titan Multimodal Embeddings model are not stored or employed in training AWS models or external distribution. Additionally, other usage data, such as timestamps and logged account IDs, is excluded from model training.
Integration with existing systems
The Amazon Titan Multimodal Embeddings model underwent training with the Euclidean L2 algorithm, so the vector database being used should be compatible with this algorithm.
Cost estimate
At the time of writing this post, as per Amazon Bedrock Pricing for the Amazon Titan Multimodal Embeddings model, the following are the estimated costs using on-demand pricing for this solution:
- One-time indexing cost – $0.06 for a single run of indexing, assuming a 1,000 images gallery
- Classification cost – $6 for 100,000 input images per month
Clean up
To avoid incurring future charges, delete the resources you created, such as the Amazon SageMaker notebook instance, when not in use.
Conclusion
In this post, we explored how you can use the Amazon Titan Multimodal Embeddings model to build an inexpensive solution for document classification in the IDP workflow. We demonstrated how to create an image gallery of known documents and perform similarity searches with new documents to classify them. We also discussed the benefits of using multimodal image embeddings for document classification, including their ability to handle diverse document types, scalability, and low latency.
As new document templates and types emerge in business workflows, developers can invoke the Amazon Bedrock API to vectorize them dynamically and append to their IDP systems to rapidly enhance document classification capabilities. This creates an inexpensive, infinitely scalable classification layer that can handle even the most diverse, unstructured enterprise documents.
Overall, this post provides a roadmap for building an inexpensive solution for document classification in the IDP workflow using Amazon Titan Multimodal Embeddings.
As next steps, check out What is Amazon Bedrock to start using the service. And follow Amazon Bedrock on the AWS Machine Learning Blog to keep up to date with new capabilities and use cases for Amazon Bedrock.
About the Authors
 Sumit Bhati is a Senior Customer Solutions Manager at AWS, specializes in expediting the cloud journey for enterprise customers. Sumit is dedicated to assisting customers through every phase of their cloud adoption, from accelerating migrations to modernizing workloads and facilitating the integration of innovative practices.
Sumit Bhati is a Senior Customer Solutions Manager at AWS, specializes in expediting the cloud journey for enterprise customers. Sumit is dedicated to assisting customers through every phase of their cloud adoption, from accelerating migrations to modernizing workloads and facilitating the integration of innovative practices.
 David Girling is a Senior AI/ML Solutions Architect with over 20 years of experience in designing, leading, and developing enterprise systems. David is part of a specialist team that focuses on helping customers learn, innovate, and utilize these highly capable services with their data for their use cases.
David Girling is a Senior AI/ML Solutions Architect with over 20 years of experience in designing, leading, and developing enterprise systems. David is part of a specialist team that focuses on helping customers learn, innovate, and utilize these highly capable services with their data for their use cases.
 Ravi Avula is a Senior Solutions Architect in AWS focusing on Enterprise Architecture. Ravi has 20 years of experience in software engineering and has held several leadership roles in software engineering and software architecture working in the payments industry.
Ravi Avula is a Senior Solutions Architect in AWS focusing on Enterprise Architecture. Ravi has 20 years of experience in software engineering and has held several leadership roles in software engineering and software architecture working in the payments industry.
 George Belsian is a Senior Cloud Application Architect at AWS. He is passionate about helping customers accelerate their modernization and cloud adoption journey. In his current role, George works alongside customer teams to strategize, architect, and develop innovative, scalable solutions.
George Belsian is a Senior Cloud Application Architect at AWS. He is passionate about helping customers accelerate their modernization and cloud adoption journey. In his current role, George works alongside customer teams to strategize, architect, and develop innovative, scalable solutions.
Author: Sumit Bhati