

Enhance conversational AI with advanced routing techniques with Amazon Bedrock
With AWS generative AI services like Amazon Bedrock, developers can create systems that expertly manage and respond to user requests… Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohe…
Conversational artificial intelligence (AI) assistants are engineered to provide precise, real-time responses through intelligent routing of queries to the most suitable AI functions. With AWS generative AI services like Amazon Bedrock, developers can create systems that expertly manage and respond to user requests. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon using a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
This post assesses two primary approaches for developing AI assistants: using managed services such as Agents for Amazon Bedrock, and employing open source technologies like LangChain. We explore the advantages and challenges of each, so you can choose the most suitable path for your needs.
What is an AI assistant?
An AI assistant is an intelligent system that understands natural language queries and interacts with various tools, data sources, and APIs to perform tasks or retrieve information on behalf of the user. Effective AI assistants possess the following key capabilities:
- Natural language processing (NLP) and conversational flow
- Knowledge base integration and semantic searches to understand and retrieve relevant information based on the nuances of conversation context
- Running tasks, such as database queries and custom AWS Lambda functions
- Handling specialized conversations and user requests
We demonstrate the benefits of AI assistants using Internet of Things (IoT) device management as an example. In this use case, AI can help technicians manage machinery efficiently with commands that fetch data or automate tasks, streamlining operations in manufacturing.
Agents for Amazon Bedrock approach
Agents for Amazon Bedrock allows you to build generative AI applications that can run multi-step tasks across a company’s systems and data sources. It offers the following key capabilities:
- Automatic prompt creation from instructions, API details, and data source information, saving weeks of prompt engineering effort
- Retrieval Augmented Generation (RAG) to securely connect agents to a company’s data sources and provide relevant responses
- Orchestration and running of multi-step tasks by breaking down requests into logical sequences and calling necessary APIs
- Visibility into the agent’s reasoning through a chain-of-thought (CoT) trace, allowing troubleshooting and steering of model behavior
- Prompt engineering abilities to modify the automatically generated prompt template for enhanced control over agents
You can use Agents for Amazon Bedrock and Knowledge Bases for Amazon Bedrock to build and deploy AI assistants for complex routing use cases. They provide a strategic advantage for developers and organizations by simplifying infrastructure management, enhancing scalability, improving security, and reducing undifferentiated heavy lifting. They also allow for simpler application layer code because the routing logic, vectorization, and memory is fully managed.
Solution overview
This solution introduces a conversational AI assistant tailored for IoT device management and operations when using Anthropic’s Claude v2.1 on Amazon Bedrock. The AI assistant’s core functionality is governed by a comprehensive set of instructions, known as a system prompt, which delineates its capabilities and areas of expertise. This guidance makes sure the AI assistant can handle a wide range of tasks, from managing device information to running operational commands.
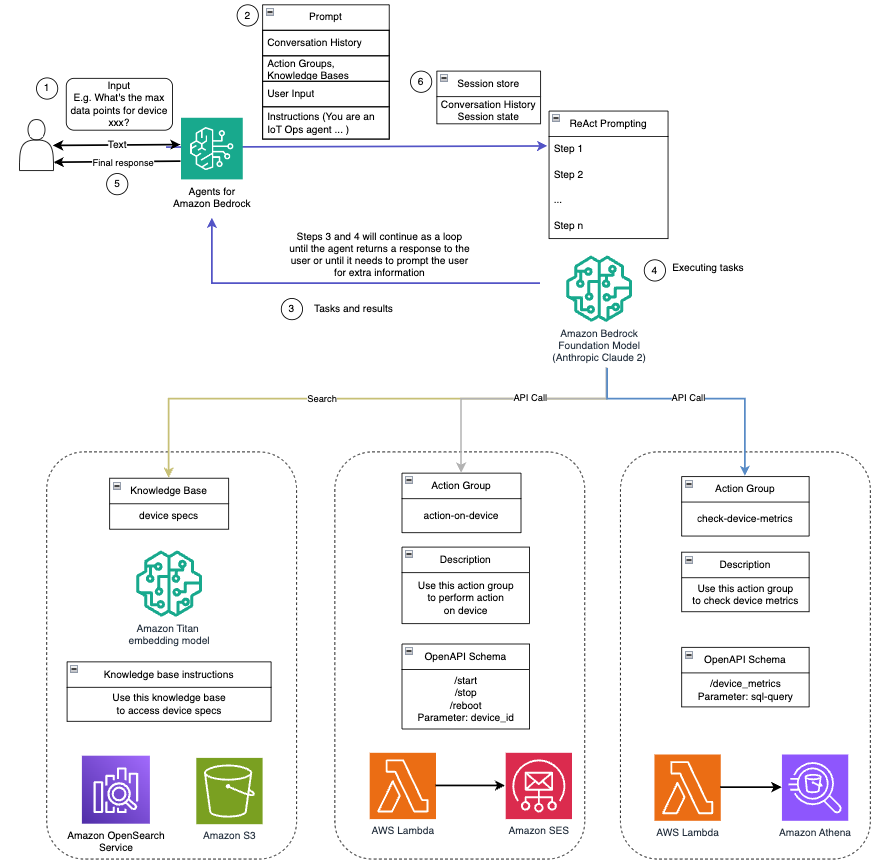
Equipped with these capabilities, as detailed in the system prompt, the AI assistant follows a structured workflow to address user questions. The following figure provides a visual representation of this workflow, illustrating each step from initial user interaction to the final response.

The workflow is composed of the following steps:
- The process begins when a user requests the assistant to perform a task; for example, asking for the maximum data points for a specific IoT device
device_xxx. This text input is captured and sent to the AI assistant. - The AI assistant interprets the user’s text input. It uses the provided conversation history, action groups, and knowledge bases to understand the context and determine the necessary tasks.
- After the user’s intent is parsed and understood, the AI assistant defines tasks. This is based on the instructions that are interpreted by the assistant as per the system prompt and user’s input.
- The tasks are then run through a series of API calls. This is done using ReAct prompting, which breaks down the task into a series of steps that are processed sequentially:
- For device metrics checks, we use the
check-device-metricsaction group, which involves an API call to Lambda functions that then query Amazon Athena for the requested data. - For direct device actions like start, stop, or reboot, we use the
action-on-deviceaction group, which invokes a Lambda function. This function initiates a process that sends commands to the IoT device. For this post, the Lambda function sends notifications using Amazon Simple Email Service (Amazon SES). - We use Knowledge Bases for Amazon Bedrock to fetch from historical data stored as embeddings in the Amazon OpenSearch Service vector database.
- For device metrics checks, we use the
- After the tasks are complete, the final response is generated by the Amazon Bedrock FM and conveyed back to the user.
- Agents for Amazon Bedrock automatically stores information using a stateful session to maintain the same conversation. The state is deleted after a configurable idle timeout elapses.
Technical overview
The following diagram illustrates the architecture to deploy an AI assistant with Agents for Amazon Bedrock.

It consists of the following key components:
- Conversational interface – The conversational interface uses Streamlit, an open source Python library that simplifies the creation of custom, visually appealing web apps for machine learning (ML) and data science. It is hosted on Amazon Elastic Container Service (Amazon ECS) with AWS Fargate, and it is accessed using an Application Load Balancer. You can use Fargate with Amazon ECS to run containers without having to manage servers, clusters, or virtual machines.
- Agents for Amazon Bedrock – Agents for Amazon Bedrock completes the user queries through a series of reasoning steps and corresponding actions based on ReAct prompting:
- Knowledge Bases for Amazon Bedrock – Knowledge Bases for Amazon Bedrock provides fully managed RAG to supply the AI assistant with access to your data. In our use case, we uploaded device specifications into an Amazon Simple Storage Service (Amazon S3) bucket. It serves as the data source to the knowledge base.
- Action groups – These are defined API schemas that invoke specific Lambda functions to interact with IoT devices and other AWS services.
- Anthropic Claude v2.1 on Amazon Bedrock – This model interprets user queries and orchestrates the flow of tasks.
- Amazon Titan Embeddings – This model serves as a text embeddings model, transforming natural language text—from single words to complex documents—into numerical vectors. This enables vector search capabilities, allowing the system to semantically match user queries with the most relevant knowledge base entries for effective search.
The solution is integrated with AWS services such as Lambda for running code in response to API calls, Athena for querying datasets, OpenSearch Service for searching through knowledge bases, and Amazon S3 for storage. These services work together to provide a seamless experience for IoT device operations management through natural language commands.
Benefits
This solution offers the following benefits:
- Implementation complexity:
- Fewer lines of code are required, because Agents for Amazon Bedrock abstracts away much of the underlying complexity, reducing development effort
- Managing vector databases like OpenSearch Service is simplified, because Knowledge Bases for Amazon Bedrock handles vectorization and storage
- Integration with various AWS services is more streamlined through pre-defined action groups
- Developer experience:
- The Amazon Bedrock console provides a user-friendly interface for prompt development, testing, and root cause analysis (RCA), enhancing the overall developer experience
- Agility and flexibility:
- Agents for Amazon Bedrock allows for seamless upgrades to newer FMs (such as Claude 3.0) when they become available, so your solution stays up to date with the latest advancements
- Service quotas and limitations are managed by AWS, reducing the overhead of monitoring and scaling infrastructure
- Security:
- Amazon Bedrock is a fully managed service, adhering to AWS’s stringent security and compliance standards, potentially simplifying organizational security reviews
Although Agents for Amazon Bedrock offers a streamlined and managed solution for building conversational AI applications, some organizations may prefer an open source approach. In such cases, you can use frameworks like LangChain, which we discuss in the next section.
LangChain dynamic routing approach
LangChain is an open source framework that simplifies building conversational AI by allowing the integration of large language models (LLMs) and dynamic routing capabilities. With LangChain Expression Language (LCEL), developers can define the routing, which allows you to create non-deterministic chains where the output of a previous step defines the next step. Routing helps provide structure and consistency in interactions with LLMs.
For this post, we use the same example as the AI assistant for IoT device management. However, the main difference is that we need to handle the system prompts separately and treat each chain as a separate entity. The routing chain decides the destination chain based on the user’s input. The decision is made with the support of an LLM by passing the system prompt, chat history, and user’s question.
Solution overview
The following diagram illustrates the dynamic routing solution workflow.

The workflow consists of the following steps:
- The user presents a question to the AI assistant. For example, “What are the max metrics for device 1009?”
- An LLM evaluates each question along with the chat history from the same session to determine its nature and which subject area it falls under (such as SQL, action, search, or SME). The LLM classifies the input and the LCEL routing chain takes that input.
- The router chain selects the destination chain based on the input, and the LLM is provided with the following system prompt:
The LLM evaluates the user’s question along with the chat history to determine the nature of the query and which subject area it falls under. The LLM then classifies the input and outputs a JSON response in the following format:
The router chain uses this JSON response to invoke the corresponding destination chain. There are four subject-specific destination chains, each with its own system prompt:
- SQL-related queries are sent to the SQL destination chain for database interactions. You can use LCEL to build the SQL chain.
- Action-oriented questions invoke the custom Lambda destination chain for running operations. With LCEL, you can define your own custom function; in our case, it’s a function to run a predefined Lambda function to send an email with a device ID parsed. Example user input might be “Shut down device 1009.”
- Search-focused inquiries proceed to the RAG destination chain for information retrieval.
- SME-related questions go to the SME/expert destination chain for specialized insights.
- Each destination chain takes the input and runs the necessary models or functions:
- The SQL chain uses Athena for running queries.
- The RAG chain uses OpenSearch Service for semantic search.
- The custom Lambda chain runs Lambda functions for actions.
- The SME/expert chain provides insights using the Amazon Bedrock model.
- Responses from each destination chain are formulated into coherent insights by the LLM. These insights are then delivered to the user, completing the query cycle.
- User input and responses are stored in Amazon DynamoDB to provide context to the LLM for the current session and from past interactions. The duration of persisted information in DynamoDB is controlled by the application.
Technical overview
The following diagram illustrates the architecture of the LangChain dynamic routing solution.

The web application is built on Streamlit hosted on Amazon ECS with Fargate, and it is accessed using an Application Load Balancer. We use Anthropic’s Claude v2.1 on Amazon Bedrock as our LLM. The web application interacts with the model using LangChain libraries. It also interacts with variety of other AWS services, such as OpenSearch Service, Athena, and DynamoDB to fulfill end-users’ needs.
Benefits
This solution offers the following benefits:
- Implementation complexity:
- Although it requires more code and custom development, LangChain provides greater flexibility and control over the routing logic and integration with various components.
- Managing vector databases like OpenSearch Service requires additional setup and configuration efforts. The vectorization process is implemented in code.
- Integrating with AWS services may involve more custom code and configuration.
- Developer experience:
- LangChain’s Python-based approach and extensive documentation can be appealing to developers already familiar with Python and open source tools.
- Prompt development and debugging may require more manual effort compared to using the Amazon Bedrock console.
- Agility and flexibility:
- LangChain supports a wide range of LLMs, allowing you to switch between different models or providers, fostering flexibility.
- The open source nature of LangChain enables community-driven improvements and customizations.
- Security:
- As an open source framework, LangChain may require more rigorous security reviews and vetting within organizations, potentially adding overhead.
Conclusion
Conversational AI assistants are transformative tools for streamlining operations and enhancing user experiences. This post explored two powerful approaches using AWS services: the managed Agents for Amazon Bedrock and the flexible, open source LangChain dynamic routing. The choice between these approaches hinges on your organization’s requirements, development preferences, and desired level of customization. Regardless of the path taken, AWS empowers you to create intelligent AI assistants that revolutionize business and customer interactions
Find the solution code and deployment assets in our GitHub repository, where you can follow the detailed steps for each conversational AI approach.
About the Authors
 Ameer Hakme is an AWS Solutions Architect based in Pennsylvania. He collaborates with Independent Software Vendors (ISVs) in the Northeast region, assisting them in designing and building scalable and modern platforms on the AWS Cloud. An expert in AI/ML and generative AI, Ameer helps customers unlock the potential of these cutting-edge technologies. In his leisure time, he enjoys riding his motorcycle and spending quality time with his family.
Ameer Hakme is an AWS Solutions Architect based in Pennsylvania. He collaborates with Independent Software Vendors (ISVs) in the Northeast region, assisting them in designing and building scalable and modern platforms on the AWS Cloud. An expert in AI/ML and generative AI, Ameer helps customers unlock the potential of these cutting-edge technologies. In his leisure time, he enjoys riding his motorcycle and spending quality time with his family.
 Sharon Li is an AI/ML Solutions Architect at Amazon Web Services based in Boston, with a passion for designing and building Generative AI applications on AWS. She collaborates with customers to leverage AWS AI/ML services for innovative solutions.
Sharon Li is an AI/ML Solutions Architect at Amazon Web Services based in Boston, with a passion for designing and building Generative AI applications on AWS. She collaborates with customers to leverage AWS AI/ML services for innovative solutions.
 Kawsar Kamal is a senior solutions architect at Amazon Web Services with over 15 years of experience in the infrastructure automation and security space. He helps clients design and build scalable DevSecOps and AI/ML solutions in the Cloud.
Kawsar Kamal is a senior solutions architect at Amazon Web Services with over 15 years of experience in the infrastructure automation and security space. He helps clients design and build scalable DevSecOps and AI/ML solutions in the Cloud.
Author: Ameer Hakme