

Cohere Command R and R+ are now available in Amazon SageMaker JumpStart
Today, we are excited to announce that Cohere Command R and R+ foundation models are available through Amazon SageMaker JumpStart to deploy and run inference… Command R/R+ are the state-of-the-art retrieval augmented generation (RAG)-optimized models designed to tackle enterprise-grade workl…
This blog post is co-written with Pradeep Prabhakaran from Cohere.
Today, we are excited to announce that Cohere Command R and R+ foundation models are available through Amazon SageMaker JumpStart to deploy and run inference. Command R/R+ are the state-of-the-art retrieval augmented generation (RAG)-optimized models designed to tackle enterprise-grade workloads.
In this post, we walk through how to discover and deploy Cohere Command R/R+ via SageMaker JumpStart.
What are Cohere Command R and Command R+?
Cohere Command R is a family of highly scalable language models that balance high performance with strong accuracy. Command R family – include Command R and Command R+ models – are optimized for RAG based workflows such as conversational interaction and long context tasks, enabling companies to move beyond proof of concept and into production. These powerful models are designed to handle complex tasks with high performance and strong accuracy, making them suitable for real-world applications.
Command R boasts high precision on RAG and tool use tasks, low latency and high throughput, a long 128,000-token context length, and strong capabilities across 10 key languages: English, French, Spanish, Italian, German, Portuguese, Japanese, Korean, Arabic, and Chinese.
Command R+ is the newest model, optimized for extremely performant conversational interaction and long-context tasks. It is recommended for workflows that lean on complex RAG functionality and multi-step tool use (agents), while Cohere R is well-suited for simpler RAG and single-step tool use tasks, as well as applications where price is a major consideration.
What is SageMaker JumpStart
With SageMaker JumpStart, you can choose from a broad selection of publicly available foundation models. ML practitioners can deploy foundation models to dedicated SageMaker instances from a network-isolated environment and customize models using SageMaker for model training and deployment. You can now discover and deploy Cohere Command R/R+ models with a few choices in Amazon SageMaker Studio or programmatically through the SageMaker Python SDK. Doing so enables you to derive model performance and machine learning operations (MLOps) controls with SageMaker features such as SageMaker Pipelines, SageMaker Debugger, or container logs.
The model is deployed in an AWS secure environment and under your virtual private cloud (VPC) controls, helping provide data security. Cohere Command R/R+ models are available today for deployment and inferencing in Amazon SageMaker Studio in us-east-1 (N. Virginia), us-east-2 (Ohio), us-west-1 (N. California), us-west-2 (Oregon), Canada (Central), eu-central-1 (Frankfurt), eu-west-1 (Ireland), eu-west-2 (London), eu-west-3 (Paris), eu-north-1 (Stockholm), ap-southeast-1 (Singapore), ap-southeast-2 (Sydney), ap-northeast-1 (Tokyo) , ap-northeast-2 (Seoul), ap-south-1 (Mumbai), and sa-east-1 (Sao Paulo).
Discover models
You can access the foundation models through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. In this section, we go over how to discover the models in SageMaker Studio.
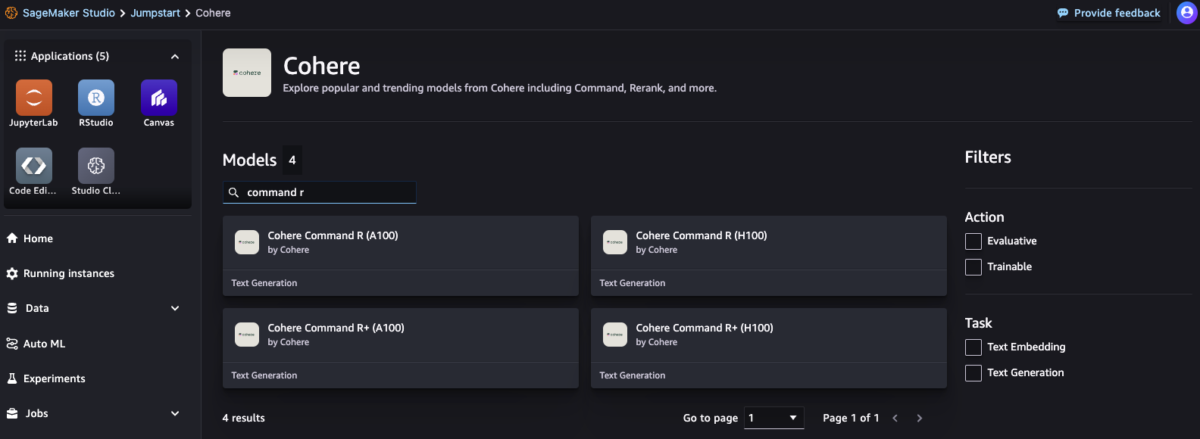
From the SageMaker JumpStart landing page, you can easily discover various models by browsing through different hubs, which are named after model providers. The Cohere Command R and R+ models are available in the Cohere hub. If you don’t see these models, ensure you have the latest SageMaker Studio version by shutting down and restarting Studio Classic Apps.
To find the Command R and R+ models, search for “Command R” in the search box located at the top left of the SageMaker JumpStart landing page. Each model can be deployed on Amazon Elastic Compute Cloud (EC2) P5 instances powered by NVIDIA H100 Tensor Core GPUs (p5.48xlarge) and Amazon EC2 P4de instances powered by NVIDIA A100 Tensor Core GPUs (ml.p4de.24xlarge).

Deploy a model
To illustrate model deployment, we’ll deploy Cohere Command R+ on NVIDIA H100. Choose the model card to open the corresponding model detail page.
When you choose Deploy, a window appears prompting you to subscribe to the model on AWS Marketplace. Choose Subscribe, which redirects you to the AWS Marketplace listing for Cohere Command R+ (H100). Follow the on-screen instructions to complete the subscription process.

Once subscribed, return to the model detail page and choose Deploy in the window. The deployment process initiates.

Alternatively, you can choose Notebooks on the model card and open the example notebook in JupyterLab. This notebook provides end-to-end guidance on deploying the model for inference and cleaning up resources. You can also find this example notebook in the Cohere SageMaker GitHub repository. To ensure the security of the endpoint, you can configure AWS Key Management Service (KMS) key for a SageMaker endpoint configuration.
If an endpoint has already been created, you can simply connect to it:
Real-time inference
Once your endpoint has been connected, you can perform real-time inference using the co.chat endpoint.
Multilingual capabilities
Command R/R+ is optimized to perform well in 10 key languages, as listed in the introduction. Additionally, pre-training data have been included for the following 13 languages: Russian, Polish, Turkish, Vietnamese, Dutch, Czech, Indonesian, Ukrainian, Romanian, Greek, Hindi, Hebrew, Persian.
The model has been trained to respond in the language of the user. Here’s an example in Spanish:
Here’s what the response might look like:
Command R/R+ can also perform cross-lingual tasks, such as translation or answering questions about content in other languages.
Chat with documents (RAG)
Command R/R+ can ground its generations. This means that it can generate responses based on a list of supplied document snippets, and it includes citations in its response indicating the source of the information.
For example, the code snippet that follows produces an answer to “How deep is the Mariana Trench” along with inline citations based on the provided on-line documents.
Request:
Response:
Single-Step & Multi-Step Tool Use
Command R/R+, comes with a Tool Use API that enables the language model to interact with user-defined tools to automate highly sophisticated tasks. Command R/R+ in Tool Use mode creates API payloads (JSONs with specific parameters) based on user interactions and conversational history. These can be used to instruct any other application or tool.
For example, an application can be instructed to automatically categorize and route support tickets to the appropriate individual, change a status in customer relationship management software (CRM), or retrieve relevant snippets from a vector database. It comes in two variants; single-step and multi-step:
- Single-step tool use enables a richer set of behaviors by leveraging data stored in tools, taking actions through APIs, interacting with a vector database, querying a search engine, etc.
- Multi-step tool use is an extension of this basic idea and allows the model to call more than one tool in a sequence of steps, using the results from one tool call in a subsequent step. This process allows the language model to reason, perform dynamic actions, and quickly adapt based on information coming from external sources.
To explore these capabilities further, you can refer to the provided Jupyter notebook and Cohere’s AWS GitHub repository, which offer additional examples showcasing various use cases and applications.
Clean Up
After you’ve finished running the notebook and exploring the Cohere Command R and R+ models, it’s essential to clean up the resources you’ve created to avoid incurring unnecessary charges. Follow these steps to delete the resources and stop the billing:
Conclusion
In this post, we explored how to leverage the powerful capabilities of Cohere’s Command R and R+ models on Amazon SageMaker JumpStart. These state-of-the-art large language models are specifically designed to excel at real-world enterprise use cases, offering unparalleled performance and scalability. With their availability on SageMaker JumpStart and AWS Marketplace, you now have seamless access to these cutting-edge models, enabling you to unlock new levels of productivity and innovation in your natural language processing projects.
About the authors
 Pradeep Prabhakaran is a Customer Solutions Architect at Cohere. In his current role at Cohere, Pradeep acts as a trusted technical advisor to customers and partners, providing guidance and strategies to help them realize the full potential of Cohere’s cutting-edge Generative AI platform. Prior to joining Cohere, Pradeep was a Principal Customer Solutions Manager at Amazon Web Services, where he led Enterprise Cloud transformation programs for large enterprises. Prior to AWS, Pradeep has held various leadership positions at consulting companies such as Slalom, Deloitte, and Wipro. Pradeep holds a Bachelor’s degree in Engineering and is based in Dallas, TX.
Pradeep Prabhakaran is a Customer Solutions Architect at Cohere. In his current role at Cohere, Pradeep acts as a trusted technical advisor to customers and partners, providing guidance and strategies to help them realize the full potential of Cohere’s cutting-edge Generative AI platform. Prior to joining Cohere, Pradeep was a Principal Customer Solutions Manager at Amazon Web Services, where he led Enterprise Cloud transformation programs for large enterprises. Prior to AWS, Pradeep has held various leadership positions at consulting companies such as Slalom, Deloitte, and Wipro. Pradeep holds a Bachelor’s degree in Engineering and is based in Dallas, TX.  James Yi is a Senior AI/ML Partner Solutions Architect at Amazon Web Services. He spearheads AWS’s strategic partnerships in Emerging Technologies, guiding engineering teams to design and develop cutting-edge joint solutions in GenAI. He enables field and technical teams to seamlessly deploy, operate, secure, and integrate partner solutions on AWS. James collaborates closely with business leaders to define and execute joint Go-To-Market strategies, driving cloud-based business growth. Outside of work, he enjoys playing soccer, traveling, and spending time with his family.
James Yi is a Senior AI/ML Partner Solutions Architect at Amazon Web Services. He spearheads AWS’s strategic partnerships in Emerging Technologies, guiding engineering teams to design and develop cutting-edge joint solutions in GenAI. He enables field and technical teams to seamlessly deploy, operate, secure, and integrate partner solutions on AWS. James collaborates closely with business leaders to define and execute joint Go-To-Market strategies, driving cloud-based business growth. Outside of work, he enjoys playing soccer, traveling, and spending time with his family.Author: Pradeep Prabhakaran