

Accelerate NLP inference with ONNX Runtime on AWS Graviton processors
ONNX Runtime is the runtime engine used for model inference and training with ONNX… Bfloat16 accelerated SGEMM kernels and int8 MMLA accelerated Quantized GEMM (QGEMM) kernels in ONNX have improved inference performance by up to 65% for fp32 inference and up to 30% for int8 quantized inference fo…
ONNX is an open source machine learning (ML) framework that provides interoperability across a wide range of frameworks, operating systems, and hardware platforms. ONNX Runtime is the runtime engine used for model inference and training with ONNX.
AWS Graviton3 processors are optimized for ML workloads, including support for bfloat16, Scalable Vector Extension (SVE), and Matrix Multiplication (MMLA) instructions. Bfloat16 accelerated SGEMM kernels and int8 MMLA accelerated Quantized GEMM (QGEMM) kernels in ONNX have improved inference performance by up to 65% for fp32 inference and up to 30% for int8 quantized inference for several natural language processing (NLP) models on AWS Graviton3-based Amazon Elastic Compute Cloud (Amazon EC2) instances. Starting version v1.17.0, the ONNX Runtime supports these optimized kernels.
In this post, we show how to run ONNX Runtime inference on AWS Graviton3-based EC2 instances and how to configure them to use optimized GEMM kernels. We also demonstrate the resulting speedup through benchmarking.
Optimized GEMM kernels
ONNX Runtime supports the Microsoft Linear Algebra Subroutine (MLAS) backend as the default Execution Provider (EP) for deep learning operators. AWS Graviton3-based EC2 instances (c7g, m7g, r7g, c7gn, and Hpc7g instances) support bfloat16 format and MMLA instructions for the deep learning operator acceleration. These instructions improve the SIMD hardware utilization and reduce the end-to-end inference latency by up to 1.65 times compared to the armv8 DOT product instruction-based kernels.
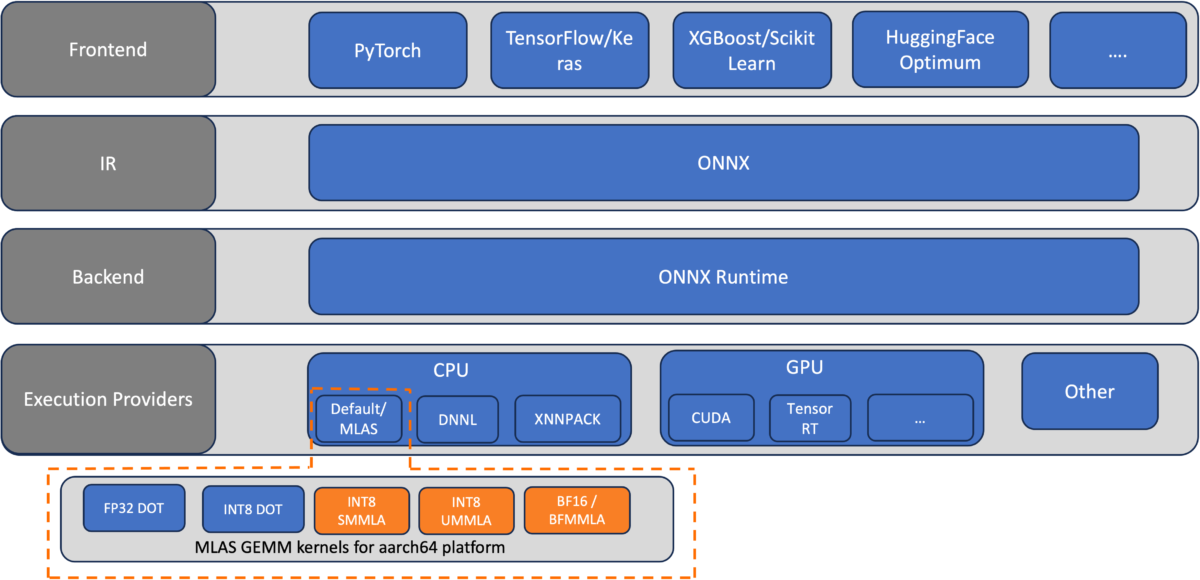
The AWS team implemented MLAS kernels for bfloat16 fast math and int8 quantized General Matrix Multiply (GEMM) using BFMMLA, SMMLA, and UMMLA instructions, which have higher matrix multiplication throughput compared to DOT instructions. The bfloat16 support allows efficient deployment of models trained using bfloat16, fp32, and automatic mixed precision (AMP) without the need for quantization. As shown in the following diagrams, the optimized GEMM kernels are integrated into the ONNX Runtime CPU EP as MLAS kernels.
The first figure illustrates the ONNX software stack, highlighting (in orange) the components optimized for inference performance improvement on the AWS Graviton3 platform.

The following diagram illustrates the ONNX Runtime EP flow, highlighting (in orange) the components optimized for inference performance improvement on the AWS Graviton3 platform.

Enable the optimizations
The optimizations are part of the ONNX Runtime 1.17.0 release, and are available starting with onnxruntime-1.17.0 python wheels and conda-1.17.0 packages. Optimized int8 kernels are enabled by default, and will be picked up automatically for AWS Graviton3 Processors. Bfloat16 fast math kernels, on the other hand, are not enabled by default and need the following session options in ONNX Runtime to enable them:
# For C++ applications
# For Python applications
Benchmark results
We started with measuring the inference throughput, in queries per second, for the fp32 model without any of our optimizations (using ONNX Runtime 1.16.0), which is marked at 1.0 with the red dotted line in the following graph. Then we compared the improvements from bfloat16 fast math kernels from ONNX Runtime 1.17.1 for the same fp32 model inference. The normalized results are plotted in the graph. You can see that for the BERT, RoBERTa, and GPT2 models, the throughput improvement is up to 65%. Similar improvements are observed for the inference latency.

Similar to the preceding fp32 inference comparison graph, we started with measuring the inference throughput, in queries per second, for the int8 quantized model without any of our optimizations (using ONNX Runtime 1.16.0), which is marked at 1.0 with the red dotted line in the following graph. Then we compared the improvements from the optimized MMLA kernels from ONNX Runtime 1.17.1 for the same model inference. The normalized results are plotted in the graph. You can see that for the BERT, RoBERTa, and GPT2 models, the throughput improvement is up to 30%. Similar improvements are observed for the inference latency.

Benchmark setup
We used an AWS Graviton3-based c7g.4xl EC2 instance with Ubuntu 22.04 based AMI to demonstrate the performance improvements with the optimized GEMM kernels from ONNX Runtime. The instance and the AMI details are mentioned in the following snippet:
The ONNX Runtime repo provides inference benchmarking scripts for transformers-based language models. The scripts support a wide range of models, frameworks, and formats. We picked PyTorch-based BERT, RoBERTa, and GPT models to cover the common language tasks like text classification, sentiment analysis, and predicting the masked word. The models cover both encoder and decoder transformers architecture.
The following code lists the steps to run inference for the fp32 model with bfloat16 fast math mode and int8 quantized mode using the ONNX Runtime benchmarking script. The script downloads the models, exports them to ONNX format, quantizes them into int8 for int8 inference, and runs inference for different sequence lengths and batch sizes. Upon successful completion of the script, it will print the inference throughput in queries/sec (QPS) and latency in msec along with the system configuration. Refer to the ONNX Runtime Benchmarking script for more details.
Conclusion
In this post, we discussed how to run ONNX Runtime inference on an AWS Graviton3-based EC2 instance and how to configure the instance to use optimized GEMM kernels. We also demonstrated the resulting speedups. We hope that you will give it a try!
If you find use cases where similar performance gains are not observed on AWS Graviton, please open an issue on the AWS Graviton Technical Guide GitHub to let us know about it.
About the Author
 Sunita Nadampalli is a Software Development Manager at AWS. She leads Graviton software performance optimizations for Machine Learning and HPC workloads. She is passionate about open source software development and delivering high-performance and sustainable software solutions with Arm SoCs.
Sunita Nadampalli is a Software Development Manager at AWS. She leads Graviton software performance optimizations for Machine Learning and HPC workloads. She is passionate about open source software development and delivering high-performance and sustainable software solutions with Arm SoCs.
Author: Sunita Nadampalli