

Building Generative AI prompt chaining workflows with human in the loop
In this blog post, you will learn about prompt chaining, how to break a complex task into multiple tasks to use prompt chaining with an LLM in a specific order, and how to involve a human to review the response generated by the LLM… Example overview To illustrate this example, consider a retai…
Generative AI is a type of artificial intelligence (AI) that can be used to create new content, including conversations, stories, images, videos, and music. Like all AI, generative AI works by using machine learning models—very large models that are pretrained on vast amounts of data called foundation models (FMs). FMs are trained on a broad spectrum of generalized and unlabeled data. They’re capable of performing a wide variety of general tasks with a high degree of accuracy based on input prompts. Large language models (LLMs) are one class of FMs. LLMs are specifically focused on language-based tasks such as summarization, text generation, classification, open-ended conversation, and information extraction.
FMs and LLMs, even though they’re pre-trained, can continue to learn from data inputs or prompts during inference. This means that you can develop comprehensive outputs through carefully curated prompts. A prompt is the information you pass into an LLM to elicit a response. This includes task context, data that you pass to the model, conversation and action history, instructions, and even examples. The process of designing and refining prompts to get specific responses from these models is called prompt engineering.
While LLMs are good at following instructions in the prompt, as a task gets complex, they’re known to drop tasks or perform a task not at the desired accuracy. LLMs can handle complex tasks better when you break them down into smaller subtasks. This technique of breaking down a complex task into subtasks is called prompt chaining. With prompt chaining, you construct a set of smaller subtasks as individual prompts. Together, these subtasks make up the overall complex task. To accomplish the overall task, your application feeds each subtask prompt to the LLM in a pre-defined order or according to a set of rules.
While Generative AI can create highly realistic content, including text, images, and videos, it can also generate outputs that appear plausible but are verifiably incorrect. Incorporating human judgment is crucial, especially in complex and high-risk decision-making scenarios. This involves building a human-in-the-loop process where humans play an active role in decision making alongside the AI system.
In this blog post, you will learn about prompt chaining, how to break a complex task into multiple tasks to use prompt chaining with an LLM in a specific order, and how to involve a human to review the response generated by the LLM.
Example overview
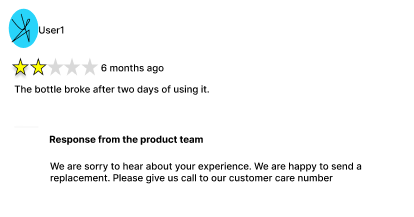
To illustrate this example, consider a retail company that allows purchasers to post product reviews on their website. By responding promptly to those reviews, the company demonstrates its commitments to customers and strengthens customer relationships.

Figure 1: Customer review and response
The example application in this post automates the process of responding to customer reviews. For most reviews, the system auto-generates a reply using an LLM. However, if the review or LLM-generated response contains uncertainty around toxicity or tone, the system flags it for a human reviewer. The human reviewer then assesses the flagged content to make the final decision about the toxicity or tone.
The application uses event-driven architecture (EDA), a powerful software design pattern that you can use to build decoupled systems by communicating through events. As soon as the product review is created, the review receiving system uses Amazon EventBridge to send an event that a product review is posted, along with the actual review content. The event starts an AWS Step Functions workflow. The workflow runs through a series of steps including generating content using an LLM and involving human decision making.

Figure 2: Review workflow
The process of generating a review response includes evaluating the toxicity of the review content, identifying sentiment, generating a response, and involving a human approver. This naturally fits into a workflow type of application because it’s a single process containing multiple sequential steps along with the need to manage state between steps. Hence the example uses Step Functions for workflow orchestration. Here are the steps in the review response workflow.
- Detect if the review content has any harmful information using the Amazon Comprehend DetectToxicContent API. The API responds with the toxicity score that represents the overall confidence score of detection between 0 and 1 with score closer to 1 indicating high toxicity.
- If toxicity of the review is in the range of 0.4 – 0.6, send the review to a human reviewer to make the decision.
- If the toxicity of the review is greater than 0.6 or the reviewer finds the review harmful, publish
HARMFUL_CONTENT_DETECTEDmessage. - If the toxicity of the review is less than 0.4 or reviewer approves the review, find the sentiment of the review first and then generate the response to the review comment. Both tasks are achieved using a generative AI model.
- Repeat the toxicity detection through the Comprehend API for the LLM generated response.
- If the toxicity of the LLM generated response is in the range of 0.4 – 0.6, send the LLM generated response to a human reviewer.
- If the LLM generated response is found to be non-toxic, publish
NEW_REVIEW_RESPONSE_CREATEDevent. - If the LLM generated response is found to be toxic, publish
RESPONSE_GENERATION_FAILEDevent.

Figure 3: product review evaluation and response workflow
Getting started
Use the instructions in the GitHub repository to deploy and run the application.
Prompt chaining
Prompt chaining simplifies the problem for the LLM by dividing single, detailed, and monolithic tasks into smaller, more manageable tasks. Some, but not all, LLMs are good at following all the instructions in a single prompt. The simplification results in writing focused prompts for the LLM, leading to a more consistent and accurate response. The following is a sample ineffective single prompt.
Read the below customer review, filter for harmful content and provide your thoughts on the overall sentiment in JSON format. Then construct an email response based on the sentiment you determine and enclose the email in JSON format. Based on the sentiment, write a report on how the product can be improved.
To make it more effective, you can split the prompt into multiple subtasks:
- Filter for harmful content
- Get the sentiment
- Generate the email response
- Write a report
You can even run some of the tasks in parallel. By breaking down to focused prompts, you achieve the following benefits:
- You speed up the entire process. You can handle tasks in parallel, use different models for different tasks, and send response back to the user rather than waiting for the model to process a larger prompt for considerably longer time.
- Better prompts provide better output. With focused prompts, you can engineer the prompts by adding additional relevant context thus improving the overall reliability of the output.
- You spend less time developing. Prompt engineering is an iterative process. Both debugging LLM calls for detailed prompt and refining the larger prompt for accuracy require significant time and effort. Smaller tasks enable you to experiment and refine through successive iterations.
Step Functions is a natural fit to build prompt chaining because it offers multiple different ways to chain prompts: sequentially, in parallel, and iteratively by passing the state data from one state to another. Consider the situation where you have built the product review response prompt chaining workflow and now want to evaluate the responses from different LLMs to find the best fit using an evaluation test suite. The evaluation test suite consists of hundreds of test product reviews, a reference response to the review, and a set of rules to evaluate the LLM response against the reference response. You can automate the evaluation activity using a Step Functions workflow. The first task in the workflow asks the LLM to generate a review response for the product review. The second task then asks the LLM to compare the generated response to the reference response using the rules and generate an evaluation score. Based on the evaluation score for each review, you can decide if the LLM passes your evaluation criteria or not. You can use the map state in Step Functions to run the evaluations for each review in your evaluation test suite in parallel. See this repository for more prompt chaining examples.
Human in the loop
Involving human decision making in the example allows you to improve the accuracy of the system when the toxicity of the content cannot be determined to be either safe or harmful. You can implement human review within the Step Functions workflow using Wait for a Callback with the Task Token integration. When you use this integration with any supported AWS SDK API, the workflow task generates a unique token and then pauses until the token is returned. You can use this integration to include human decision making, call a legacy on-premises system, wait for completion of long running tasks, and so on.
In the sample application, the send email for approval task includes a wait for the callback token. It invokes an AWS Lambda function with a token and waits for the token. The Lambda function builds an email message along with the link to an Amazon API Gateway URL. Lambda then uses Amazon Simple Notification Service (Amazon SNS) to send an email to a human reviewer. The reviewer reviews the content and either accepts or rejects the message by selecting the appropriate link in the email. This action invokes the Step Functions SendTaskSuccess API. The API sends back the task token and a status message of whether to accept or reject the review. Step Functions receives the token, resumes the send email for approval task and then passes control to the choice state. The choice state decides whether to go through acceptance or rejection of the review based on the status message.

Figure 4: Human-in-the-loop workflow
Event-driven architecture
EDA enables building extensible architectures. You can add consumers at any time by subscribing to the event. For example, consider moderating images and videos attached to a product review in addition to the text content. You also need to write code to delete the images and videos if they are found harmful. You can add a consumer, the image moderation system, to the NEW_REVIEW_POSTED event without making any code changes to the existing event consumers or producers. Development of the image moderation system and the review response system to delete harmful images can proceed in parallel which in turn improves development velocity.
When the image moderation workflow finds toxic content, it publishes a HARMFULL_CONTENT_DETECTED event. The event can be processed by a review response system that decides what to do with the event. By decoupling systems through events, you gain many advantages including improved development velocity, variable scaling, and fault tolerance.

Figure 5: Event-driven workflow
Cleanup
Use the instructions in the GitHub repository to delete the sample application.
Conclusion
In this blog post, you learned how to build a generative AI application with prompt chaining and a human-review process. You learned how both techniques improve the accuracy and safety of a generative AI application. You also learned how event-driven architectures along with workflows can integrate existing applications with generative AI applications.
Visit Serverless Land for more Step Functions workflows.
About the authors
 Veda Raman is a Senior Specialist Solutions Architect for Generative AI and machine learning based at AWS. Veda works with customers to help them architect efficient, secure and scalable machine learning applications. Veda specializes in generative AI services like Amazon Bedrock and Amazon Sagemaker.
Veda Raman is a Senior Specialist Solutions Architect for Generative AI and machine learning based at AWS. Veda works with customers to help them architect efficient, secure and scalable machine learning applications. Veda specializes in generative AI services like Amazon Bedrock and Amazon Sagemaker.
 Uma Ramadoss is a Principal Solutions Architect at Amazon Web Services, focused on the Serverless and Integration Services. She is responsible for helping customers design and operate event-driven cloud-native applications using services like Lambda, API Gateway, EventBridge, Step Functions, and SQS. Uma has a hands on experience leading enterprise-scale serverless delivery projects and possesses strong working knowledge of event-driven, micro service and cloud architecture.
Uma Ramadoss is a Principal Solutions Architect at Amazon Web Services, focused on the Serverless and Integration Services. She is responsible for helping customers design and operate event-driven cloud-native applications using services like Lambda, API Gateway, EventBridge, Step Functions, and SQS. Uma has a hands on experience leading enterprise-scale serverless delivery projects and possesses strong working knowledge of event-driven, micro service and cloud architecture.
Author: Veda Raman