

Vitech uses Amazon Bedrock to revolutionize information access with AI-powered chatbot
This post is co-written with Murthy Palla and Madesh Subbanna from Vitech… Vitech is a global provider of cloud-centered benefit and investment administration software… Vitech helps group insurance, pension fund administration, and investment clients expand their offerings and capabilities, str…
This post is co-written with Murthy Palla and Madesh Subbanna from Vitech.
Vitech is a global provider of cloud-centered benefit and investment administration software. Vitech helps group insurance, pension fund administration, and investment clients expand their offerings and capabilities, streamline their operations, and gain analytical insights. To serve their customers, Vitech maintains a repository of information that includes product documentation (user guides, standard operating procedures, runbooks), which is currently scattered across multiple internal platforms (for example, Confluence sites and SharePoint folders). The lack of a centralized and easily navigable knowledge system led to several issues, including:
- Low productivity due to lack of an efficient retrieval system and often leads to information overload
- Inconsistent information access because there was no singular, unified source of truth
To address these challenges, Vitech used generative artificial intelligence (AI) with Amazon Bedrock to build VitechIQ, an AI-powered chatbot for Vitech employees to access an internal repository of documentation.
For customers that are looking to build an AI-driven chatbot that interacts with internal repository of documents, AWS offers a fully managed capability Knowledge Bases for Amazon Bedrock, that can implement the entire Retrieval Augment Generation (RAG) workflow from ingestion to retrieval, and prompt augmentation without having to build any custom integrations to data sources or manage data flows. Alternatively, open-source technologies like Langchain can be used to orchestrate the end-to-end flow.
In this blog, we walkthrough the architectural components, evaluation criteria for the components selected by Vitech and the process flow of user interaction within VitechIQ.
Technical components and evaluation criteria
In this section, we discuss the key technical components and evaluation criteria for the components involved in building the solution.
Hosting large language models
Vitech explored the option of hosting Large Language Models (LLMs) models using Amazon Sagemaker. Vitech needed a fully managed and secure experience to host LLMs and eliminate the undifferentiated heavy lifting associated with hosting 3P models. Amazon Bedrock is a fully managed service that makes FMs from leading AI startups and Amazon available via an API, so one can choose from a wide range of FMs to find the model that is best suited for their use case. With Bedrock’s serverless experience, one can get started quickly, privately customize FMs with their own data, and easily integrate and deploy them into applications using the AWS tools without having to manage any infrastructure. Vitech thereby selected Amazon Bedrock to host LLMs and integrate seamlessly with their existing infrastructure.
Retrieval Augmented Generation vs. fine tuning
Traditional LLMs don’t have an understanding of Vitech’s processes and flow, making it imperative to augment the power of LLMs with Vitech’s knowledge base. Fine-tuning would allow Vitech to train the model on a small sample set, thereby allowing the model to provide response using Vitech’s vocabulary. However, for this use case, the complexity associated with fine-tuning and the costs were not warranted. Instead, Vitech opted for Retrieval Augmented Generation (RAG), in which the LLM can use vector embeddings to perform a semantic search and provide a more relevant answer to users when interacting with the chatbot.
Data store
Vitech’s product documentation is largely available in .pdf format, making it the standard format used by VitechIQ. In cases where document is in available in other formats, users preprocess this data and convert it into .pdf format. These documents are uploaded and stored in Amazon Simple Storage Service (Amazon S3), making it the centralized data store.
Data chunking
Chunking is the process of breaking down large text documents into smaller, more manageable segments (such as paragraphs or sections). Vitech chose a recursive chunking method that involves dynamically dividing text based on its inherent structure like chapters and sections, offering a more natural division of text. A chunk size of 1,000 tokens with a 200-token overlap provided the most optimal results.
Large language models
VitechIQ uses two key LLM models to address the business challenge of providing efficient and accurate information retrieval:
- Vector embedding – This process converts the documents into a numerical representation, making sure semantic relationships are captured (similar documents are represented numerically closer to each other), allowing for an efficient search. Vitech explored multiple vector embeddings models and selected the Amazon Titan Embeddings text model offered by Amazon Bedrock.
- Question answering – The core functionality of VitechIQ is to provide concise and trustworthy answers to user queries based on the retrieved context. Vitech chose the Anthropic Claude model, available from Amazon Bedrock, for this purpose. The high token limit of 200,000 (approximately 150,000 words) allows the model to process extensive context and maintain awareness of the ongoing conversation, enabling it to provide more accurate and relevant responses. Additionally, VitechIQ includes metadata from the vector database (for example, document URLs) in the model’s output, providing users with source attribution and enhancing trust in the generated answers.
Prompt engineering
Prompt engineering is crucial for the knowledge retrieval system. The prompt guides the LLM on how to respond and interact based on the user question. Prompts also help ground the model. As part of prompt engineering, VitechIQ configured the prompt with a set of instructions for the LLM to keep the conversations relevant and eliminate discriminatory remarks, and guided it on how to respond to open-ended conversations. The following is an example of a prompt used in VitechIQ:
Vector store
Vitech explored vector stores like OpenSearch and Redis. However, Vitech has expertise in handling and managing Amazon Aurora PostgreSQL-Compatible Edition databases for their enterprise applications. Amazon Aurora PostgreSQL provides support for the open source pgvector extension to process vector embeddings, and Amazon Aurora Optimized Reads offers a cost-effective and performant option. These factors led to the selection of Amazon Aurora PostgreSQL as the store for vector embeddings.
Processing framework
LangChain offered seamless machine learning (ML) model integration, allowing Vitech to build custom automated AI components and be model agnostic. LangChain’s out-of-the-box chain and agents libraries have empowered Vitech to adopt features like prompt templates and memory management, accelerating the overall development process. Vitech used Python virtual environments to freeze a stable version of the LangChain dependencies and seamlessly move it from development to production environments. With support of Langchain ConversationBufferMemory library, VitechIQ stores conversation information using a stateful session to maintain the relevance in conversation. The state is deleted after a configurable idle timeout elapses.
Multiple LangChain libraries were used across VitechIQ; the following are a few notable libraries and their usage:
- langchain.llms (Bedrock) – Interact with LLMs provided by Amazon Bedrock
- langchain.embeddings (BedrockEmbeddings) – Create embeddings
- langchain.chains.question_answering (load_qa_chain) – Perform Q&A
- langchain.prompts (PromptTemplate) – Create prompt templates
- langchain.vectorstores.pgvector (PGVector) – Create vector embeddings and perform semantic search
- langchain.text_splitter (RecursiveCharacterTextSplitter) – Split documents into chunks
- langchain.memory (ConversationBufferMemory) – Manage conversational memory
They used the following versions:
- langchain==0.0.306
- langchain-experimental==0.0.24
- langsmith==0.0.43
- pgvector==0.2.3
- streamlit==1.28.0
- streamlit-extras==0.3.4
User interface
The VitechIQ user interface is built using Streamlit. Streamlit offers a user-friendly experience to quickly build interactive and easily deployable solutions using the Python library (used widely at Vitech). The Streamlit app is hosted on an Amazon Elastic Cloud Compute (Amazon EC2) fronted with Elastic Load Balancing (ELB), allowing Vitech to scale as traffic increases.
Optimizing search results
To reduce hallucination and optimize the token size and search results, VitechIQ performs semantic search using the value k in the search function (similarity_search_with_score). VitechIQ filters embedding responses to the top 10 results and then limits the dataset to records that have a score less than 0.48 (indicating close co-relation), thereby identifying the most relevant response and eliminating noise.
Amazon Bedrock VPC interface endpoints
Vitech wanted to make sure all communication is kept private and doesn’t traverse the public internet. VitechIQ uses an Amazon Bedrock VPC interface endpoint to make sure the connectivity is secured end to end.
Monitoring
VitechIQ application logs are sent to Amazon CloudWatch. This helps Vitech management get insights on current usage and trends on topics. Additionally, Vitech uses Amazon Bedrock runtime metrics to measure latency, performance, and number of tokens.
“We noted that the combination of Amazon Bedrock and Claude not only matched, but in some cases surpassed, in performance and quality and it conforms to Vitech security standards compared to what we saw with a competing generative AI solution.”
– Madesh Subbanna, VP Databases & Analytics at Vitech
Solution overview
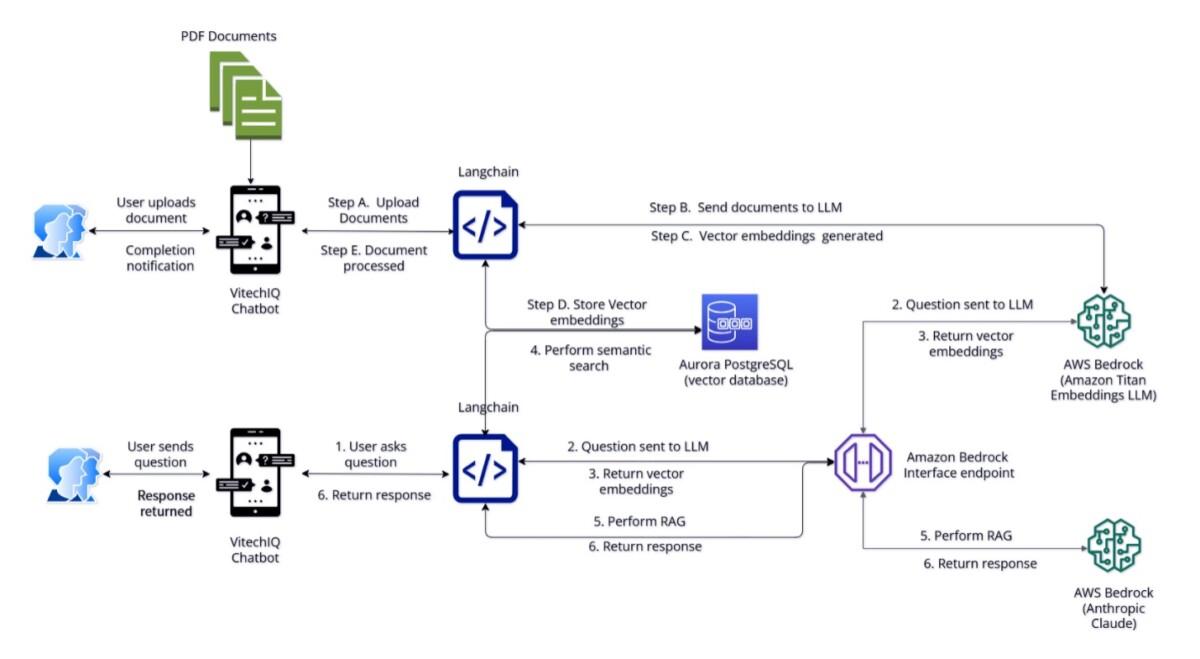
Let’s look on how all these components come together to illustrate the end-user experience. The following diagram shows the solution architecture.

The VitechIQ user experience can be split into two process flows: document repository, and knowledge retrieval.
Document repository flow
This step involves the curation and collection of documents that will comprise the knowledge base. Internally, Vitech stakeholders conduct due diligence to review and approve a document before it is uploaded to VitechIQ. For each document uploaded to VitechIQ, the user provides an internal reference link (Confluence or SharePoint), to make sure any future revisions can be tracked and the most up-to-date information is available on VitechIQ. As new document versions are available, VitechIQ updates the embeddings to so the recommendations remain relevant and up to date.
Vitech stakeholders conduct a manual review on a weekly basis of the documents and revisions that are being requested to be uploaded. As a result, the documents have a 1-week turnaround to be available in VitechIQ for user consumption.
The following screenshot illustrates the VitechIQ interface to upload documents.

The upload procedure includes the following steps:
- The domain stakeholder uploads the documents to VitechIQ.
- LangChain uses recursive chunking to parse the document and send it to the Amazon Titan Embeddings model.
- The Amazon Titan Embeddings model generates vector embeddings.
- These vector embeddings are stored in an Aurora PostgreSQL database.
- The user receives notification of the success (or failure) of the upload.
Knowledge retrieval flow
In this flow, the user interacts with the VitechIQ chatbot, which provides a summarized and accurate response to their question. VitechIQ also provides source document attribution in response to the user question (it uses the URL of the document uploaded in the previous process flow).
The following screenshot illustrates a user interaction with VitechIQ.

The process includes the following steps:
- The user interacts with VitechIQ by asking a question in natural language.
- The question is sent by the Amazon Bedrock interface endpoint to the Amazon Titan Embeddings model.
- The Amazon Titan Embeddings model converts the question and generates vector embeddings.
- The vector embeddings are sent to Amazon Aurora PostgreSQL to perform a semantic search on the knowledge base documents.
- Using RAG, the prompt is enhanced with context and relevant documents, and then sent to Amazon Bedrock (Anthropic Claude) for summarization.
- Amazon Bedrock generates a summarized response according to the prompt instructions and sends the response back to the user.
As additional questions are asked by user, the context is passed back into the prompt, making it aware of the ongoing conversation.
Benefits offered by VitechIQ
By using the power of generative AI, VitechIQ has successfully addressed the critical challenges of information fragmentation and inaccessibility. The following are the key achievements and innovative impact of VitechIQ:
- Centralized knowledge hub – This helps streamline the process of information retrieval, resulting in over 50% reduction in inquiries to product teams.
- Enhanced productivity and efficiency – Users are provided quick and accurate access. VitechIQ is used on average by 50 users daily, which accounts to approximately 2,000 queries on a monthly basis.
- Continuous evolution and learning – Vitech is able to expand its knowledge base on new domains. Vitech’s API documentation (spanning 35,000 documents with a document size up to 3 GB) was uploaded to VitechIQ, enabling development teams to seamlessly search for documentation.
Conclusion
VitechIQ stands as a testament to the company’s commitment to harnessing the power of AI for operational excellence and the capabilities offered by Amazon Bedrock. As Vitech iterates through the solution, few of the top priority roadmap items include using the LangChain Expression Language (LCEL), modernizing the Streamlit application to host on Docker, and automating the document upload process. Additionally, Vitech is exploring opportunities to build similar capability for their external customers. The success of VitechIQ is a stepping stone for further technological advancements, setting a new standard for how technology can augment human capabilities in the corporate world. Vitech continues to innovate by partnering with AWS on programs like the Generative AI Innovation Center and identify additional customer-facing implementations. To learn more, visit Amazon Bedrock.
About the Authors
 Samit Kumbhani is an AWS Senior Solutions Architect in the New York City area with over 18 years of experience. He currently collaborates with Independent Software Vendors (ISVs) to build highly scalable, innovative, and secure cloud solutions. Outside of work, Samit enjoys playing cricket, traveling, and biking.
Samit Kumbhani is an AWS Senior Solutions Architect in the New York City area with over 18 years of experience. He currently collaborates with Independent Software Vendors (ISVs) to build highly scalable, innovative, and secure cloud solutions. Outside of work, Samit enjoys playing cricket, traveling, and biking.
 Murthy Palla is a Technical Manager at Vitech with 9 years of extensive experience in data architecture and engineering. Holding certifications as an AWS Solutions Architect and AI/ML Engineer from the University of Texas at Austin, he specializes in advanced Python, databases like Oracle and PostgreSQL, and Snowflake. In his current role, Murthy leads R&D initiatives to develop innovative data lake and warehousing solutions. His expertise extends to applying generative AI in business applications, driving technological advancement and operational excellence within Vitech.
Murthy Palla is a Technical Manager at Vitech with 9 years of extensive experience in data architecture and engineering. Holding certifications as an AWS Solutions Architect and AI/ML Engineer from the University of Texas at Austin, he specializes in advanced Python, databases like Oracle and PostgreSQL, and Snowflake. In his current role, Murthy leads R&D initiatives to develop innovative data lake and warehousing solutions. His expertise extends to applying generative AI in business applications, driving technological advancement and operational excellence within Vitech.
 Madesh Subbanna is the Vice President at Vitech, where he leads the database team and has been a foundational figure since the early stages of the company. With two decades of technical and leadership experience, he has significantly contributed to the evolution of Vitech’s architecture, performance, and product design. Madesh has been instrumental in integrating advanced database solutions, DataInsight, AI, and ML technologies into the V3locity platform. His role transcends technical contributions, encompassing project management and strategic planning with senior management to ensure seamless project delivery and innovation. Madesh’s career at Vitech, marked by a series of progressive leadership positions, reflects his deep commitment to technological excellence and client success.
Madesh Subbanna is the Vice President at Vitech, where he leads the database team and has been a foundational figure since the early stages of the company. With two decades of technical and leadership experience, he has significantly contributed to the evolution of Vitech’s architecture, performance, and product design. Madesh has been instrumental in integrating advanced database solutions, DataInsight, AI, and ML technologies into the V3locity platform. His role transcends technical contributions, encompassing project management and strategic planning with senior management to ensure seamless project delivery and innovation. Madesh’s career at Vitech, marked by a series of progressive leadership positions, reflects his deep commitment to technological excellence and client success.
 Ameer Hakme is an AWS Solutions Architect based in Pennsylvania. He collaborates with Independent Software Vendors (ISVs) in the Northeast region, assisting them in designing and building scalable and modern platforms on the AWS Cloud. An expert in AI/ML and generative AI, Ameer helps customers unlock the potential of these cutting-edge technologies. In his leisure time, he enjoys riding his motorcycle and spending quality time with his family.
Ameer Hakme is an AWS Solutions Architect based in Pennsylvania. He collaborates with Independent Software Vendors (ISVs) in the Northeast region, assisting them in designing and building scalable and modern platforms on the AWS Cloud. An expert in AI/ML and generative AI, Ameer helps customers unlock the potential of these cutting-edge technologies. In his leisure time, he enjoys riding his motorcycle and spending quality time with his family.
Author: Samit Kumbhani