

How Deloitte Italy built a digital payments fraud detection solution using quantum machine learning and Amazon Braket
This post demonstrates the potential for quantum computing algorithms paired with ML models to revolutionize fraud detection within digital payment platforms… We share how Deloitte built a hybrid quantum neural network solution with Amazon Braket to demonstrate the possible gains coming from thi…
As digital commerce expands, fraud detection has become critical in protecting businesses and consumers engaging in online transactions. Implementing machine learning (ML) algorithms enables real-time analysis of high-volume transactional data to rapidly identify fraudulent activity. This advanced capability helps mitigate financial risks and safeguard customer privacy within expanding digital markets.
Deloitte is a strategic global systems integrator with over 19,000 certified AWS practitioners across the globe. It continues to raise the bar through participation in the AWS Competency Program with 29 competencies, including Machine Learning.
This post demonstrates the potential for quantum computing algorithms paired with ML models to revolutionize fraud detection within digital payment platforms. We share how Deloitte built a hybrid quantum neural network solution with Amazon Braket to demonstrate the possible gains coming from this emerging technology.
The promise of quantum computing
Quantum computers harbor the potential to radically overhaul financial systems, enabling much faster and more precise solutions. Compared to classical computers, quantum computers are expected in the long run to have to advantages in the areas of simulation, optimization, and ML. Whether quantum computers can provide a meaningful speedup to ML is an active topic of research.
Quantum computing can perform efficient near real-time simulations in critical areas such as pricing and risk management. Optimization models are key activities in financial institutions, aimed at determining the best investment strategy for a portfolio of assets, allocating capital, or achieving productivity improvements. Some of these optimization problems are nearly impossible for traditional computers to tackle, so approximations are used to solve the problems in a reasonable amount of time. Quantum computers could perform faster and more accurate optimizations without using any approximations.
Despite the long-term horizon, the potentially disruptive nature of this technology means that financial institutions are looking to get an early foothold in this technology by building in-house quantum research teams, expanding their existing ML COEs to include quantum computing, or engaging with partners such as Deloitte.
At this early stage, customers seek access to a choice of different quantum hardware and simulation capabilities in order to run experiments and build expertise. Braket is a fully managed quantum computing service that lets you explore quantum computing. It provides access to quantum hardware from IonQ, OQC, Quera, Rigetti, IQM, a variety of local and on-demand simulators including GPU-enabled simulations, and infrastructure for running hybrid quantum-classical algorithms such as quantum ML. Braket is fully integrated with AWS services such as Amazon Simple Storage Service (Amazon S3) for data storage and AWS Identity and Access Management (IAM) for identity management, and customers only pay for what you use.
In this post, we demonstrate how to implement a quantum neural network-based fraud detection solution using Braket and AWS native services. Although quantum computers can’t be used in production today, our solution provides a workflow that will seamlessly adapt and function as a plug-and-play system in the future, when commercially viable quantum devices become available.
Solution overview
The goal of this post is to explore the potential of quantum ML and present a conceptual workflow that could serve as a plug-and-play system when the technology matures. Quantum ML is still in its early stages, and this post aims to showcase the art of the possible without delving into specific security considerations. As quantum ML technology advances and becomes ready for production deployments, robust security measures will be essential. However, for now, the focus is on outlining a high-level conceptual architecture that can seamlessly adapt and function in the future when the technology is ready.
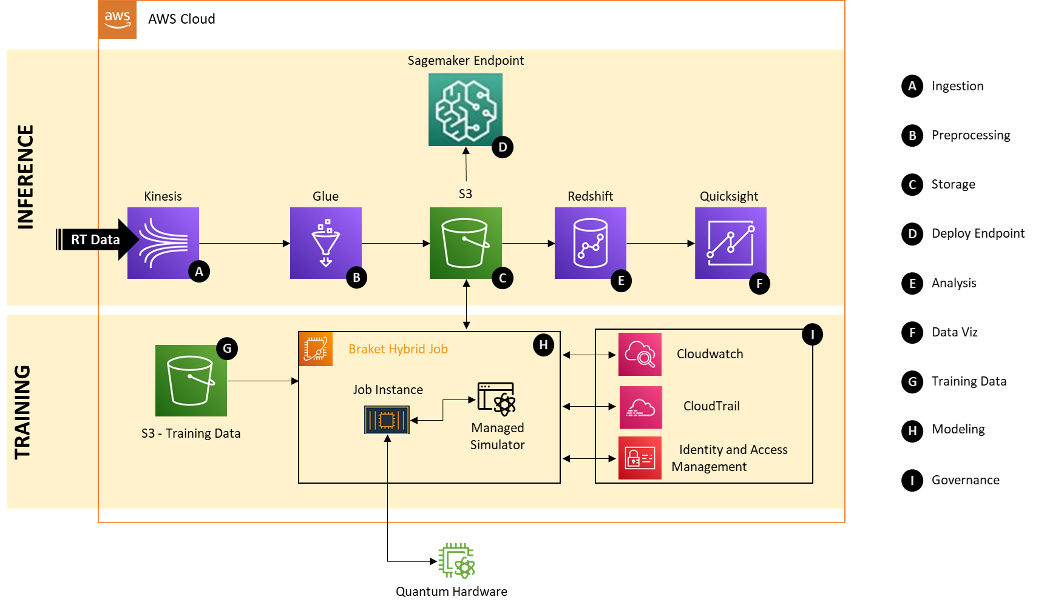
The following diagram shows the solution architecture for the implementation of a neural network-based fraud detection solution using AWS services. The solution is implemented using a hybrid quantum neural network. The neural network is built using the Keras library; the quantum component is implemented using PennyLane.

The workflow includes the following key components for inference (A–F) and training (G–I):
- Ingestion – Real-time financial transactions are ingested through Amazon Kinesis Data Streams
- Preprocessing – AWS Glue streaming extract, transform, and load (ETL) jobs consume the stream to do preprocessing and light transforms
- Storage – Amazon S3 is used to store output artifacts
- Endpoint deployment – We use an Amazon SageMaker endpoint to deploy the models
- Analysis – Transactions along with the model inferences are stored in Amazon Redshift
- Data visualization – Amazon QuickSight is used to visualize the results of fraud detection
- Training data – Amazon S3 is used to store the training data
- Modeling – A Braket environment produces a model for inference
- Governance – Amazon CloudWatch, IAM, and AWS CloudTrail are used for observability, governance, and auditability, respectively
Dataset
For training the model, we used open source data available on Kaggle. The dataset contains transactions made by credit cards in September 2013 by European cardholders. This dataset records transactions that occurred over a span of 2 days, during which there were 492 instances of fraud detected out of a total of 284,807 transactions. The dataset exhibits a significant class imbalance, with fraudulent transactions accounting for just 0.172% of the entire dataset. Because the data is highly imbalanced, various measures have been taken during data preparation and model development.
The dataset exclusively comprises numerical input variables, which have undergone a Principal Component Analysis (PCA) transformation because of confidentiality reasons.
The data only includes numerical input features (PCA-transformed due to confidentiality) and three key fields:
- Time – Time between each transaction and first transaction
- Amount – Transaction amount
- Class – Target variable, 1 for fraud or 0 for non-fraud
Data preparation
We split the data into training, validation, and test sets, and we define the target and the features sets, where Class is the target variable:
The Class field assumes values 0 and 1. To make the neural network deal with data imbalance, we perform a label encoding on the y sets:
The encoding applies to all the values the mapping: 0 to [1,0], and 1 to [0,1].
Finally, we apply scaling that standardizes the features by removing the mean and scaling to unit variance:
The functions LabelEncoder and StandardScaler are available in the scikit-learn Python library.
After all the transformations are applied, the dataset is ready to be the input of the neural network.
Neural network architecture
We composed the neural network architecture with the following layers based on several tests empirically:
- A first dense layer with 32 nodes
- A second dense layer with 9 nodes
- A quantum layer as neural network output
- Dropout layers with rate equals to 0.3
We apply an L2 regularization on the first layer and both L1 and L2 regularization on the second one, to avoid overfitting. We initialize all the kernels using the he_normal function. The dropout layers are meant to reduce overfitting as well.
Quantum circuit
The first step to obtain the layer is to build the quantum circuit (or the quantum node). To accomplish this task, we used the Python library PennyLane.
PennyLane is an open source library that seamlessly integrates quantum computing with ML. It allows you to create and train quantum-classical hybrid models, where quantum circuits act as layers within classical neural networks. By harnessing the power of quantum mechanics and merging it with classical ML frameworks like PyTorch, TensorFlow, and Keras, PennyLane empowers you to explore the exciting frontier of quantum ML. You can unlock new realms of possibility and push the boundaries of what’s achievable with this cutting-edge technology.
The design of the circuit is the most important part of the overall solution. The predictive power of the model depends entirely on how the circuit is built.
Qubits, the fundamental units of information in quantum computing, are entities that behave quite differently from classical bits. Unlike classical bits that can only represent 0 or 1, qubits can exist in a superposition of both states simultaneously, enabling quantum parallelism and faster calculations for certain problems.
We decide to use only three qubits, a small number but sufficient for our case.
We instantiate the qubits as follows:
‘default.qubit’ is the PennyLane qubits simulator. To access qubits on a real quantum computer, you can replace the second line with the following code:
device_ARN could be the ARN of the devices supported by Braket (for a list of supported devices, refer to Amazon Braket supported devices).
We defined the quantum node as follows:
The inputs are the values yielded as output from the previous layer of the neural network, and the weights are the actual weights of the quantum circuit.
RY and Rot are rotation functions performed on qubits; CNOT is a controlled bitflip gate allowing us to embed the qubits.
qml.expval(qml.PauliZ(0)), qml.expval(qml.PauliZ(2)) are the measurements applied respectively to the qubits 0 and the qubits 1, and these values will be the neural network output.
Diagrammatically, the circuit can be displayed as:
The transformations applied to qubit 0 are fewer than the transformations applied to qbit 2. This choice is because we want to separate the states of the qubits in order to obtain different values when the measures are performed. Applying different transformations to qubits allows them to enter distinct states, resulting in varied outcomes when measurements are performed. This phenomenon stems from the principles of superposition and entanglement inherent in quantum mechanics.
After we define the quantum circuit, we define the quantum hybrid neural network:
KerasLayer is the PennyLane function that turns the quantum circuit into a Keras layer.
Model training
After we have preprocessed the data and defined the model, it’s time to train the network.
A preliminary step is needed in order to deal with the unbalanced dataset. We define a weight for each class according to the inverse root rule:
The weights are given by the inverse of the root of occurrences for each of the two possible target values.
We compile the model next:
custom_metric is a modified version of the metric precision, which is a custom subroutine to postprocess the quantum data into a form compatible with the optimizer.
For evaluating model performance on imbalanced data, precision is a more reliable metric than accuracy, so we optimize for precision. Also, in fraud detection, incorrectly predicting a fraudulent transaction as valid (false negative) can have serious financial consequences and risks. Precision evaluates the proportion of fraud alerts that are true positives, minimizing costly false negatives.
Finally, we fit the model:
At each epoch, the weights of both the classic and quantum layer are updated in order to reach higher accuracy. At the end of the training, the network showed a loss of 0.0353 on the training set and 0.0119 on the validation set. When the fit is complete, the trained model is saved in .h5 format.
Model results and analysis
Evaluating the model is vital to gauge its capabilities and limitations, providing insights into the predictive quality and value derived from the quantum techniques.
To test the model, we make predictions on the test set:
Because the neural network is a regression model, it yields for each record of x_test a 2-D array, where each component can assume values between 0 and 1. Because we’re essentially dealing with a binary classification problem, the outputs should be as follows:
- [1,0] – No fraud
- [0,1] – Fraud
To convert the continuous values into binary classification, a threshold is necessary. Predictions that are equal to or above the threshold are assigned 1, and those below the threshold are assigned 0.
To align with our goal of optimizing precision, we chose the threshold value that results in the highest precision.
The following table summarizes the mapping between various threshold values and the precision.
| Class | Threshold = 0.65 | Threshold = 0.70 | Threshold = 0.75 |
| No Fraud | 1.00 | 1.00 | 1.00 |
| Fraud | 0.87 | 0.89 | 0.92 |
The model demonstrates almost flawless performance on the predominant non-fraud class, with precision and recall scores close to a perfect 1. Despite far less data, the model achieves precision of 0.87 for detecting the minority fraud class at a 0.65 threshold, underscoring performance even on sparse data. To efficiently identify fraud while minimizing incorrect fraud reports, we decide to prioritize precision over recall.
We also wanted to compare this model with a classic neural network only model to see if we are exploiting the gains coming from the quantum application. We built and trained an identical model in which the quantum layer is replaced by the following:
In the last epoch, the loss was 0.0119 and the validation loss was 0.0051.
The following table summarizes the mapping between various threshold values and the precision for the classic neural network model.
| Class | Threshold=0.65 | Threshold = 0.70 | Threshold = 0.75 |
| No Fraud | 1.0 | 1.00 | 1.00 |
| Fraud | 0.83 | 0.84 | 0. 86 |
Like the quantum hybrid model, the model performance is almost perfect for the majority class and very good for the minority class.
The hybrid neural network has 1,296 parameters, whereas the classic one has 1,329. When comparing precision values, we can observe how the quantum solution provides better results. The hybrid model, inheriting the properties of high-dimensional spaces exploration and a non-linearity from the quantum layer, is able to generalize the problem better using fewer parameters, resulting in better performance.
Challenges of a quantum solution
Although the adoption of quantum technology shows promise in providing organizations numerous benefits, practical implementation on large-scale, fault-tolerant quantum computers is a complex task and is an active area of research. Therefore, we should be mindful of the challenges that it poses:
- Sensitivity to noise – Quantum computers are extremely sensitive to external factors (such as atmospheric temperature) and require more attention and maintenance than traditional computers, and this can drift over time. One way to minimize the effects of drift is by taking advantage of parametric compilation—the ability to compile a parametric circuit such as the one used here only one time, and feed it fresh parameters at runtime, avoiding repeated compilation steps. Braket automatically does this for you.
- Dimensional complexity – The inherent nature of qubits, the fundamental units of quantum computing, introduces a higher level of intricacy compared to traditional binary bits employed in conventional computers. By harnessing the principles of superposition and entanglement, qubits possess an elevated degree of complexity in their design. This intricate architecture renders the evaluation of computational capacity a formidable challenge, because the multidimensional aspects of qubits demand a more nuanced approach to assessing their computational prowess.
- Computational errors – Increased calculation errors are intrinsic to quantum computing’s probabilistic nature during the sampling phase. These errors could impact accuracy and reliability of the results obtained through quantum sampling. Techniques such as error mitigation and error suppression are actively being developed in order to minimize the effects of errors resulting from noisy qubits. To learn more about error mitigation, see Enabling state-of-the-art quantum algorithms with Qedma’s error mitigation and IonQ, using Braket Direct.
Conclusion
The results discussed in this post suggest that quantum computing holds substantial promise for fraud detection in the financial services industry. The hybrid quantum neural network demonstrated superior performance in accurately identifying fraudulent transactions, highlighting the potential gains offered by quantum technology. As quantum computing continues to advance, its role in revolutionizing fraud detection and other critical financial processes will become increasingly evident. You can extend the results of the simulation by using real qubits and testing various outcomes on real hardware available on Braket, such as those from IQM, IonQ, and Rigetti, all on demand, with pay-as-you-go pricing and no upfront commitments.
To prepare for the future of quantum computing, organizations must stay informed on the latest advancements in quantum technology. Adopting quantum-ready cloud solutions now is a strategic priority, allowing a smooth transition to quantum when hardware reaches commercial viability. This forward-thinking approach will provide both a technological edge and rapid adaptation to quantum computing’s transformative potential across industries. With an integrated cloud strategy, businesses can proactively get quantum-ready, primed to capitalize on quantum capabilities at the right moment. To accelerate your learning journey and earn a digital badge in quantum computing fundamentals, see Introducing the Amazon Braket Learning Plan and Digital Badge.
Connect with Deloitte to pilot this solution for your enterprise on AWS.
About the authors
 Federica Marini is a Manager in Deloitte Italy AI & Data practice with a strong experience as a business advisor and technical expert in the field of AI, Gen AI, ML and Data. She addresses research and customer business needs with tailored data-driven solutions providing meaningful results. She is passionate about innovation and believes digital disruption will require a human centered approach to achieve full potential.
Federica Marini is a Manager in Deloitte Italy AI & Data practice with a strong experience as a business advisor and technical expert in the field of AI, Gen AI, ML and Data. She addresses research and customer business needs with tailored data-driven solutions providing meaningful results. She is passionate about innovation and believes digital disruption will require a human centered approach to achieve full potential.
 Matteo Capozi is a Data and AI expert in Deloitte Italy, specializing in the design and implementation of advanced AI and GenAI models and quantum computing solutions. With a strong background on cutting-edge technologies, Matteo excels in helping organizations harness the power of AI to drive innovation and solve complex problems. His expertise spans across industries, where he collaborates closely with executive stakeholders to achieve strategic goals and performance improvements.
Matteo Capozi is a Data and AI expert in Deloitte Italy, specializing in the design and implementation of advanced AI and GenAI models and quantum computing solutions. With a strong background on cutting-edge technologies, Matteo excels in helping organizations harness the power of AI to drive innovation and solve complex problems. His expertise spans across industries, where he collaborates closely with executive stakeholders to achieve strategic goals and performance improvements.
 Kasi Muthu is a senior partner solutions architect focusing on generative AI and data at AWS based out of Dallas, TX. He is passionate about helping partners and customers accelerate their cloud journey. He is a trusted advisor in this field and has plenty of experience architecting and building scalable, resilient, and performant workloads in the cloud. Outside of work, he enjoys spending time with his family.
Kasi Muthu is a senior partner solutions architect focusing on generative AI and data at AWS based out of Dallas, TX. He is passionate about helping partners and customers accelerate their cloud journey. He is a trusted advisor in this field and has plenty of experience architecting and building scalable, resilient, and performant workloads in the cloud. Outside of work, he enjoys spending time with his family.
 Kuldeep Singh is a Principal Global AI/ML leader at AWS with over 20 years in tech. He skillfully combines his sales and entrepreneurship expertise with a deep understanding of AI, ML, and cybersecurity. He excels in forging strategic global partnerships, driving transformative solutions and strategies across various industries with a focus on generative AI and GSIs.
Kuldeep Singh is a Principal Global AI/ML leader at AWS with over 20 years in tech. He skillfully combines his sales and entrepreneurship expertise with a deep understanding of AI, ML, and cybersecurity. He excels in forging strategic global partnerships, driving transformative solutions and strategies across various industries with a focus on generative AI and GSIs.
Author: Federica Marini