

Network perimeter security protections for generative AI
Generative AI–based applications have grown in popularity in the last couple of years… In this blog post, we dive deep into network perimeter protection for generative AI applications… We’ll walk through the different areas of network perimeter protection you should consider, discuss how tho…
Generative AI–based applications have grown in popularity in the last couple of years. Applications built with large language models (LLMs) have the potential to increase the value companies bring to their customers. In this blog post, we dive deep into network perimeter protection for generative AI applications. We’ll walk through the different areas of network perimeter protection you should consider, discuss how those apply to generative AI–based applications, and provide architecture patterns. By implementing network perimeter protection for your generative AI–based applications, you gain controls to help protect from unauthorized use, cost overruns, distributed denial of service (DDoS), and other threat actors or curious users.
Perimeter protection for LLMs
Network perimeter protection for web applications helps answer important questions, for example:
- Who can access the app?
- What kind of data is sent to the app?
- How much data is the app is allowed to use?
For the most part, the same network protection methods used for other web apps also work for generative AI apps. The main focus of these methods is controlling network traffic that is trying to access the app, not the specific requests and responses the app creates. We’ll focus on three key areas of network perimeter protection:
- Authentication and authorization for the app’s frontend
- Using a web application firewall
- Protection against DDoS attacks
The security concerns of using LLMs in these apps, including issues with prompt injections, sensitive information leaks, or excess agency, is beyond the scope of this post.
Frontend authentication and authorization
When designing network perimeter protection, you first need to decide whether you will allow certain users to access the application, based on whether they are authenticated (AuthN) and whether they are authorized (AuthZ) to ask certain questions of the generative AI–based applications. Many generative AI–based applications sit behind an authentication layer so that a user must sign in to their identity provider before accessing the application. For public applications that are not behind any authentication (a chatbot, for example), additional considerations are required with regard to AWS WAF and DDoS protection, which we discuss in the next two sections.
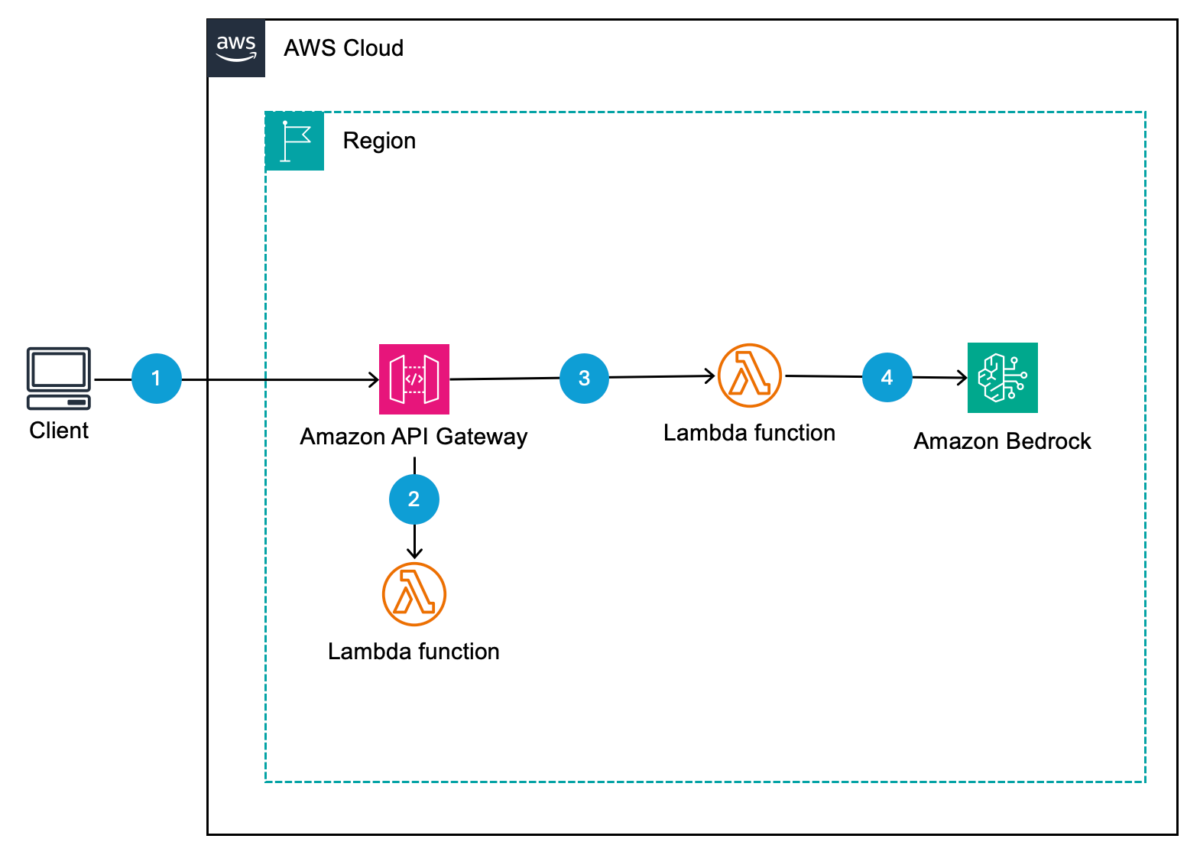
Let’s look at an example. Amazon API Gateway is an option for customers for the application frontend, providing metering of users or APIs with authentication and authorization. It’s a fully managed service that makes it convenient for developers to publish, maintain, monitor, and secure APIs at scale. With API Gateway, you create AWS Lambda authorizers to control access to APIs within your application. Figure 1 shows how access works for this example.

Figure 1: An API Gateway, Lambda authorizer, and basic filter in the signal path between client and LLM
The workflow in Figure 1 is as follows:
- A client makes a request to your API that is fronted by the API Gateway.
- When the API Gateway receives the request, it sends the request to a Lambda authorizer that authenticates the request through OAuth, SAML, or another mechanism. The Lambda authorizer returns an AWS Identity and Access Management (IAM) policy to the API Gateway, which will permit or deny the request.
- If permitted, the API Gateway sends the API request to the backend application. In Figure 1, this is a Lambda function that provides additional capabilities in the area of LLM security, standing in for more complex filtering. In addition to the Lambda authorizer, you can configure throttling on the API Gateway on a per-client basis or on the application methods clients are accessing before traffic makes it to the backend application. Throttling can provide some mitigation against not only DDoS attacks but also model cloning and inversion attacks.
- Finally, the application sends requests to your LLM that is deployed on AWS. In this example, the LLM is deployed on Amazon Bedrock.
The combination of Lambda authorizers and throttling helps support a number of perimeter protection mechanisms. First, only authorized users gain access to the application, helping to prevent bots and the public from accessing the application. Second, for authorized users, you limit the rate at which they can invoke the LLM to prevent excessive costs related to requests and responses to the LLM. Third, after users have been authenticated and authorized by the application, the application can pass identity information to the backend data access layer in order to restrict the data available to the LLM, aligning with what the user is authorized to access.
Besides API Gateway, AWS provides other options you can use to provide frontend authentication and authorization. AWS Application Load Balancer (ALB) supports OpenID Connect (OIDC) capabilities to require authentication to your OIDC provider prior to access. For internal applications, AWS Verified Access combines both identity and device trust signals to permit or deny access to your generative AI application.
AWS WAF
Once the authentication or authorization decision is made, the next consideration for network perimeter protection is on the application side. New security risks are being identified for generative AI–based applications, as described in the OWASP Top 10 for Large Language Model Applications. These risks include insecure output handling, insecure plugin design, and other mechanisms that cause the application to provide responses that are outside the desired norm. For example, a threat actor could craft a direct prompt injection to the LLM, which causes the LLM behave improperly. Some of these risks (insecure plugin design) can be addressed by passing identity information to the plugins and data sources. However, many of those protections fall outside the network perimeter protection and into the realm of security within the application. For network perimeter protection, the focus is on validating the users who have access to the application and supporting rules that allow, block, or monitor web requests based on network rules and patterns at the application level prior to application access.
In addition, bot traffic is an important consideration for web-based applications. According to Security Today, 47% of all internet traffic originates from bots. Bots that send requests to public applications drive up the cost of using generative AI–based applications by causing higher request loads.
To protect against bot traffic before the user gains access to the application, you can implement AWS WAF as part of the perimeter protection. Using AWS WAF, you can deploy a firewall to monitor and block the HTTP(S) requests that are forwarded to your protected web application resources. These resources exist behind Amazon API Gateway, ALB, AWS Verified Access, and other resources. From a web application point of view, AWS WAF is used to prevent or limit access to your application before invocation of your LLM takes place. This is an important area to consider because, in addition to protecting the prompts and completions going to and from the LLM itself, you want to make sure only legitimate traffic can access your application. AWS Managed Rules or AWS Marketplace managed rule groups provide you with predefined rules as part of a rule group.
Let’s expand the previous example. As your application shown in Figure 1 begins to scale, you decide to move it behind Amazon CloudFront. CloudFront is a web service that gives you a distributed ingress into AWS by using a global network of edge locations. Besides providing distributed ingress, CloudFront gives you the option to deploy AWS WAF in a distributed fashion to help protect against SQL injections, bot control, and other options as part of your AWS WAF rules. Let’s walk through the new architecture in Figure 2.

Figure 2: Adding AWS WAF and CloudFront to the client-to-model signal path
The workflow shown in Figure 2 is as follows:
- A client makes a request to your API. DNS directs the client to a CloudFront location, where AWS WAF is deployed.
- CloudFront sends the request through an AWS WAF rule to determine whether to block, monitor, or allow the traffic. If AWS WAF does not block the traffic, AWS WAF sends it to the CloudFront routing rules.
Note: It is recommended that you restrict access to the API Gateway so users cannot bypass the CloudFront distribution to access the API Gateway. An example of how to accomplish this goal can be found in the Restricting access on HTTP API Gateway Endpoint with Lambda Authorizer blog post.
- CloudFront sends the traffic to the API Gateway, where it runs through the same traffic path as discussed in Figure 1.
To dive into more detail, let’s focus on bot traffic. With AWS WAF Bot Control, you can monitor, block, or rate limit bots such as scrapers, scanners, crawlers, status monitors, and search engines. Bot Control provides multiple options in terms of configured rules and inspection levels. For example, if you use the targeted inspection level of the rule group, you can challenge bots that don’t self-identify, making it harder and more expensive for malicious bots to operate against your generative AI–based application. You can use the Bot Control managed rule group alone or in combination with other AWS Managed Rules rule groups and your own custom AWS WAF rules. Bot Control also provides granular visibility on the number of bots that are targeting your application, as shown in Figure 3.

Figure 3: Bot control dashboard for bot requests and non-bot requests
How does this functionality help you? For your generative AI–based application, you gain visibility into how bots and other traffic are targeting your application. AWS WAF provides options to monitor and customize the web request handling of bot traffic, including allowing specific bots or blocking bot traffic to your application. In addition to bot control, AWS WAF provides a number of different managed rule groups, including baseline rule groups, use-case specific rule groups, IP reputation rules groups, and others. For more information, take a look at the documentation on both AWS Managed Rules rule groups and AWS Marketplace managed rule groups.
DDoS protection
The last topic we’ll cover in this post is DDoS with LLMs. Similar to threats against other Layer 7 applications, threat actors can send requests that consume an exceptionally high amount of resources, which results in a decline in the service’s responsiveness or an increase in the cost to run the LLMs that are handling the high number of requests. Although throttling can help support a per-user or per-method rate limit, DDoS attacks use more advanced threat vectors that are difficult to protect against with throttling.
AWS Shield helps to provide protection against DDoS for your internet-facing applications, both at Layer 3/4 with Shield standard or Layer 7 with Shield Advanced. For example, Shield Advanced responds automatically to mitigate application threats by counting or blocking web requests that are part of the exploit by using web access control lists (ACLs) that are part of your already deployed AWS WAF. Depending on your requirements, Shield can provide multiple layers of protection against DDoS attacks.
Figure 4 shows how your deployment might look after Shield is added to the architecture.

Figure 4: Adding Shield Advanced to the client-to-model signal path
The workflow in Figure 4 is as follows:
- A client makes a request to your API. DNS directs the client to a CloudFront location, where AWS WAF and Shield are deployed.
- CloudFront sends the request through an AWS WAF rule to determine whether to block, monitor, or allow the traffic. AWS Shield can mitigate a wide range of known DDoS attack vectors and zero-day attack vectors. Depending on the configuration, Shield Advanced and AWS WAF work together to rate-limit traffic coming from individual IP addresses. If AWS WAF or Shield Advanced don’t block the traffic, the services will send it to the CloudFront routing rules.
- CloudFront sends the traffic to the API Gateway, where it will run through the same traffic path as discussed in Figure 1.
When you implement AWS Shield and Shield Advanced, you gain protection against security events and visibility into both global and account-level events. For example, at the account level, you get information on the total number of events seen on your account, the largest bit rate and packet rate for each resource, and the largest request rate for CloudFront. With Shield Advanced, you also get access to notifications of events that are detected by Shield Advanced and additional information about detected events and mitigations. These metrics and data, along with AWS WAF, provide you with visibility into the traffic that is trying to access your generative AI–based applications. This provides mitigation capabilities before the traffic accesses your application and before invocation of the LLM.
Considerations
When deploying network perimeter protection with generative AI applications, consider the following:
- AWS provides multiple options, on both the frontend authentication and authorization side and the AWS WAF side, for how to configure perimeter protections. Depending on your application architecture and traffic patterns, multiple resources can provide the perimeter protection with AWS WAF and integrate with identity providers for authentication and authorization decisions.
- You can also deploy more advanced LLM-specific prompt and completion filters by using Lambda functions and other AWS services as part of your deployment architecture. Perimeter protection capabilities are focused on preventing undesired traffic from reaching the end application.
- Most of the network perimeter protections used for LLMs are similar to network perimeter protection mechanisms for other web applications. The difference is that additional threat vectors come into play compared to regular web applications. For more information on the threat vectors, see OWASP Top 10 for Large Language Model Applications and Mitre ATLAS.
Conclusion
In this blog post, we discussed how traditional network perimeter protection strategies can provide defense in depth for generative AI–based applications. We discussed the similarities and differences between LLM workloads and other web applications. We walked through why authentication and authorization protection is important, showing how you can use Amazon API Gateway to throttle through usage plans and to provide authentication through Lambda authorizers. Then, we discussed how you can use AWS WAF to help protect applications from bots. Lastly, we talked about how AWS Shield can provide advanced protection against different types of DDoS attacks at scale. For additional information on network perimeter protection and generative AI security, take a look at other blogs posts in the AWS Security Blog Channel.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Author: Riggs Goodman III