

Cohere Rerank 3 Nimble now generally available on Amazon SageMaker JumpStart
The Cohere Rerank 3 Nimble foundation model (FM) is now generally available in Amazon SageMaker JumpStart… This model is the newest FM in Cohere’s Rerank model series, built to enhance enterprise search and Retrieval Augmented Generation (RAG) systems… In this post, we discuss the benefits an…
The Cohere Rerank 3 Nimble foundation model (FM) is now generally available in Amazon SageMaker JumpStart. This model is the newest FM in Cohere’s Rerank model series, built to enhance enterprise search and Retrieval Augmented Generation (RAG) systems.
In this post, we discuss the benefits and capabilities of this new model with some examples.
Overview of Cohere Rerank models
Cohere’s Rerank family of models are designed to enhance existing enterprise search systems and RAG systems. Rerank models improve search accuracy over both keyword-based and embedding-based search systems. Cohere Rerank 3 is designed to reorder documents retrieved by initial search algorithms based on their relevance to a given query. A reranking model, also known as a cross-encoder, is a type of model that, given a query and document pair, will output a similarity score. For FMs, words, sentences, or entire documents are often encoded as dense vectors in a semantic space. By calculating the cosine of the angle between these vectors, you can quantify their semantic similarity and output as a single similarity score. You can use this score to reorder the documents by relevance to your query.
Cohere Rerank 3 Nimble is the newest model from Cohere’s Rerank family of models, designed to improve speed and efficiency from its predecessor Cohere Rerank 3. According to Cohere’s benchmark tests including BEIR (Benchmarking IR) for accuracy and internal benchmarking datasets, Cohere Rerank 3 Nimble maintains high accuracy while being approximately 3–5 times faster than Cohere Rerank 3. The speed improvement is designed for enterprises looking to enhance their search capabilities without sacrificing performance.
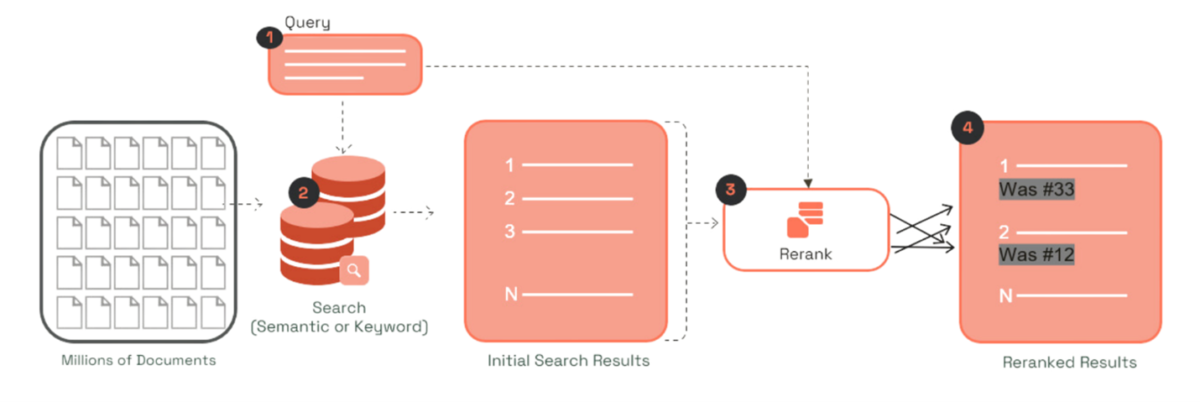
The following diagram represents the two-stage retrieval of a RAG pipeline and illustrates where Cohere Rerank 3 Nimble is incorporated into the search pipeline.

In the first stage of retrieval in the RAG architecture, a set of candidate documents are returned based on the knowledge base that’s relevant to the query. In the second stage, Cohere Rerank 3 Nimble analyzes the semantic relevance between the query and each retrieved document, reordering them from most to least relevant. The top-ranked documents augment the original query with additional context. This process improves search result quality by identifying the most pertinent documents. Integrating Cohere Rerank 3 Nimble into a RAG system enables users to send fewer but higher-quality documents to the language model for grounded generation. This results in improved accuracy and relevance of search results without adding latency.
Overview of SageMaker JumpStart
SageMaker JumpStart offers access to a broad selection of publicly available FMs. These pre-trained models serve as powerful starting points that can be deeply customized to address specific use cases. You can now use state-of-the-art model architectures, such as language models, computer vision models, and more, without having to build them from scratch.
Amazon SageMaker is a comprehensive, fully managed machine learning (ML) platform that revolutionizes the entire ML workflow. It offers an unparalleled suite of tools that cater to every stage of the ML lifecycle, from data preparation to model deployment and monitoring. Data scientists and developers can use the SageMaker integrated development environment (IDE) to access a vast array of pre-built algorithms, customize their own models, and seamlessly scale their solutions. The platform’s strength lies in its ability to abstract away the complexities of infrastructure management, allowing you to focus on innovation rather than operational overhead. The automated ML capabilities of SageMaker, including automated machine learning (AutoML) features, democratize ML by enabling even non-experts to build sophisticated models. Furthermore, its robust governance features help organizations maintain control and transparency over their ML projects, addressing critical concerns around regulatory compliance.
Prerequisites
Make sure your SageMaker AWS Identity and Access Management (IAM) service role has the AmazonSageMakerFullAccess permission policy attached.
To deploy Cohere Rerank 3 Nimble successfully, confirm one of the following:
- Make sure your IAM role has the following permissions and you have the authority to make AWS Marketplace subscriptions in the AWS account used:
aws-marketplace:ViewSubscriptionsaws-marketplace:Unsubscribeaws-marketplace:Subscribe
- Alternatively, confirm your AWS account has a subscription to the model. If so, you can skip the following deployment instructions and start with subscribing to the model package.
Deploy Cohere Rerank 3 Nimble on SageMaker JumpStart
You can access the Cohere Rerank 3 family of models using SageMaker JumpStart in Amazon SageMaker Studio, as shown in the following screenshot.

Deployment starts when you choose Deploy, and you may be prompted to subscribe to this model through AWS Marketplace. If you are already subscribed, you can choose Deploy again to deploy the model. After deployment finishes, you will see that an endpoint is created. You can test the endpoint by passing a sample inference request payload or by selecting the testing option using the SDK.

Subscribe to the model package
To subscribe to the model package, complete the following steps:
- Depending on the model you want to deploy, open the model package listing page for cohere-rerank-nimble-english or cohere-rerank-nimble-multilingual.
- On the AWS Marketplace listing, choose Continue to subscribe.
- On the Subscribe to this software page, review and choose Accept Offer if you and your organization agree with EULA, pricing, and support terms.
- Choose Continue to configuration and then choose an AWS Region.
A product ARN will be displayed. This is the model package ARN that you need to specify while creating a deployable model using Boto3.
Deploy Cohere Rerank 3 Nimble using the SDK
To deploy the model using the SDK, copy the product ARN from the previous step and specify it in the model_package_arn in the following code:
After you specify the model package ARN, you can create the endpoint, as shown in the following code. Specify the name of the endpoint, the instance type, and the number of instances being used. Make sure you have the account-level service limit for using ml.g5.xlarge for endpoint usage as one or more instances. To request a service quota increase, refer to AWS service quotas.
If the endpoint is already created, you just need to connect to it with the following code:
Follow a similar process as detailed earlier to deploy Cohere Rerank 3 on SageMaker JumpStart.
Inference example with Cohere Rerank 3 Nimble
Cohere Rerank 3 Nimble offers robust multilingual support. The model is available in both English and multilingual versions supporting over 100 languages.
The following code example illustrates how to perform real-time inference using Cohere Rerank 3 Nimble-English:
In the following code, the top_n inference parameter for Cohere Rerank 3 and Rerank 3 Nimble specifies the number of top-ranked results to return after reranking the input documents. It allows you to control how many of the most relevant documents are included in the final output. To determine an optimal value for top_n, consider factors such as the diversity of your document set, the complexity of your queries, and the desired balance between precision and latency for enterprise search or RAG.
The following is the output from Cohere Rerank 3 Nimble-English:
Cohere Rerank 3 Nimble multilingual support
The multilingual capabilities of Cohere Rerank 3 Nimble-Multilingual enable global organizations to provide consistent, improved search experiences to users across different Regions and language preferences.
In the following example, we create an input payload for a list of emails in multiple languages. We can take the same set of emails from earlier and translate them to different languages. These examples are available under the SageMaker JumpStart model card and are randomly generated for this example.
Use the following code to perform real-time inference using Cohere Rerank 3 Nimble-Multilingual:
The following is the output from Cohere Rerank 3 Nimble-Multilingual:
The output translated to English is as follows:
In both examples, the relevance scores are normalized to be in the range [0, 1]. Scores close to 1 indicate a high relevance to the query, and scores closer to 0 indicate low relevance.
Use cases suitable for Cohere Rerank 3 Nimble
The Cohere Rerank 3 Nimble model provides an option that prioritizes efficiency. The model is ideal for enterprises looking to enable their customers to accurately search complex documentation, build applications that understand over 100 languages, and retrieve the most relevant information from various data stores. In industries such as retail, where website drop-off increases with every 100 milliseconds added to search response time, having a faster AI model like Cohere Rerank 3 Nimble powering the enterprise search system translates to higher conversion rates.
Conclusion
Cohere Rerank 3 and Rerank 3 Nimble are now available on SageMaker JumpStart. To get started, refer to Train, deploy, and evaluate pretrained models with SageMaker JumpStart.
Interested in diving deeper? Check out the Cohere on AWS GitHub repo.
About the Authors
Breanne Warner  is an Enterprise Solutions Architect at Amazon Web Services supporting healthcare and life science (HCLS) customers. She is passionate about supporting customers to use generative AI on AWS and evangelizing model adoption. Breanne is also on the Women@Amazon board as co-director of Allyship with the goal of fostering inclusive and diverse culture at Amazon. Breanne holds a Bachelor’s of Science in Computer Engineering from University of Illinois at Urbana Champaign (UIUC)
is an Enterprise Solutions Architect at Amazon Web Services supporting healthcare and life science (HCLS) customers. She is passionate about supporting customers to use generative AI on AWS and evangelizing model adoption. Breanne is also on the Women@Amazon board as co-director of Allyship with the goal of fostering inclusive and diverse culture at Amazon. Breanne holds a Bachelor’s of Science in Computer Engineering from University of Illinois at Urbana Champaign (UIUC)
 Nithin Vijeaswaran is a Solutions Architect at AWS. His area of focus is generative AI and AWS AI Accelerators. He holds a Bachelor’s degree in Computer Science and Bioinformatics. Niithiyn works closely with the Generative AI GTM team to enable AWS customers on multiple fronts and accelerate their adoption of generative AI. He’s an avid fan of the Dallas Mavericks and enjoys collecting sneakers.
Nithin Vijeaswaran is a Solutions Architect at AWS. His area of focus is generative AI and AWS AI Accelerators. He holds a Bachelor’s degree in Computer Science and Bioinformatics. Niithiyn works closely with the Generative AI GTM team to enable AWS customers on multiple fronts and accelerate their adoption of generative AI. He’s an avid fan of the Dallas Mavericks and enjoys collecting sneakers.
 Karan Singh is a Generative AI Specialist for third-party models at AWS, where he works with top-tier third-party foundational model providers to define and run join GTM motions that help customers train, deploy, and scale foundational models. Karan holds a Bachelor’s of Science in Electrical and Instrumentation Engineering from Manipal University and a Master’s in Science in Electrical Engineering from Northwestern University, and is currently an MBA Candidate at the Haas School of Business at University of California, Berkeley.
Karan Singh is a Generative AI Specialist for third-party models at AWS, where he works with top-tier third-party foundational model providers to define and run join GTM motions that help customers train, deploy, and scale foundational models. Karan holds a Bachelor’s of Science in Electrical and Instrumentation Engineering from Manipal University and a Master’s in Science in Electrical Engineering from Northwestern University, and is currently an MBA Candidate at the Haas School of Business at University of California, Berkeley.
Author: Breanne Warner