

Build a video insights and summarization engine using generative AI with Amazon Bedrock
Professionals in a wide variety of industries have adopted digital video conferencing tools as part of their regular meetings with suppliers, colleagues, and customers… This post presents a solution where you can upload a recording of your meeting (a feature available in most modern digital commu…
Professionals in a wide variety of industries have adopted digital video conferencing tools as part of their regular meetings with suppliers, colleagues, and customers. These meetings often involve exchanging information and discussing actions that one or more parties must take after the session. The traditional way to make sure information and actions aren’t forgotten is to take notes during the session; a manual and tedious process that can be error-prone, particularly in a high-activity or high-pressure scenario. Furthermore, these notes are usually personal and not stored in a central location, which is a lost opportunity for businesses to learn what does and doesn’t work, as well as how to improve their sales, purchasing, and communication processes.
This post presents a solution where you can upload a recording of your meeting (a feature available in most modern digital communication services such as Amazon Chime) to a centralized video insights and summarization engine. This engine uses artificial intelligence (AI) and machine learning (ML) services and generative AI on AWS to extract transcripts, produce a summary, and provide a sentiment for the call. The solution notes the logged actions per individual and provides suggested actions for the uploader. All of this data is centralized and can be used to improve metrics in scenarios such as sales or call centers. Many commercial generative AI solutions available are expensive and require user-based licenses. In contrast, our solution is an open-source project powered by Amazon Bedrock, offering a cost-effective alternative without those limitations.
This solution can help your organizations’ sales, sales engineering, and support functions become more efficient and customer-focused by reducing the need to take notes during customer calls.
Use case overview
The organization in this scenario has noticed that during customer calls, some actions often get skipped due to the complexity of the discussions, and that there might be potential to centralize customer data to better understand how to improve customer interactions in the long run. The organization already records sessions in video format, but these videos are often kept in individual repositories, and a review of the access logs has shown that employees rarely use them in their day-to-day activities.
To increase efficiency, reduce the load, and gain better insights, this solution looks at how to use generative AI to analyze recorded videos and provide employees with valuable insights relating to their calls. It also supports audio files so you have flexibility around the type of call recordings you use. Generated call transcripts and insights include conversation summary, sentiment, a list of logged actions, and a set of suggested next best actions. These insights are stored in a central repository, unlocking the ability for analytics teams to have a single view of interactions and use the data to formulate better sales and support strategies.
Organizations typically can’t predict their call patterns, so the solution relies on AWS serverless services to scale during busy times. This enables you to keep up with peak demands, but also scale down to reduce costs during times such as seasonal holidays when the sales, engineering, and support teams are away.
This post provides guidance on how you can create a video insights and summarization engine using AWS AI/ML services. We walk through the key components and services needed to build the end-to-end architecture, offering example code snippets and explanations for each critical element that help achieve the core functionality. This approach should enable you to understand the underlying architectural concepts and provides flexibility for you to either integrate these into existing workloads or use them as a foundation to build a new workload.
Solution overview
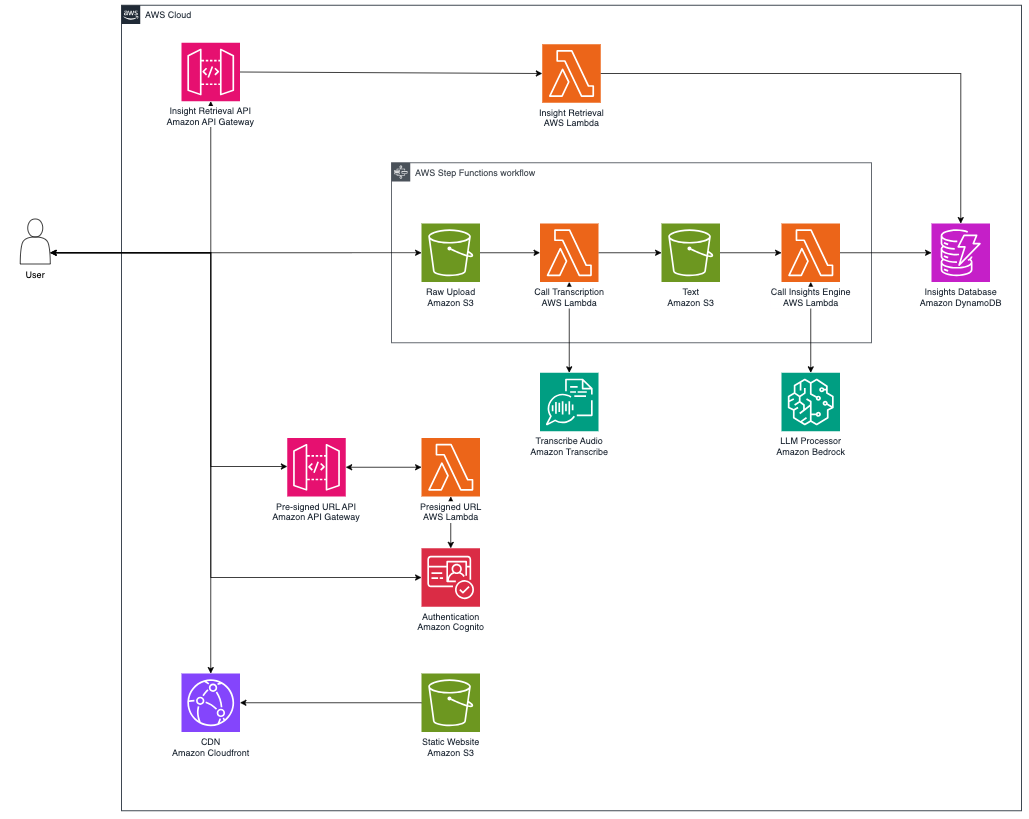
The following diagram illustrates the pipeline for the video insights and summarization engine.

To enable the video insights solution, the architecture uses a combination of AWS services, including the following:
- Amazon API Gateway is a fully managed service that makes it straightforward for developers to create, publish, maintain, monitor, and secure APIs at scale.
- Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
- Amazon DynamoDB is a fully managed NoSQL database service that provides fast and predictable performance with seamless scalability.
- AWS Lambda is an event-driven compute service that lets you run code for virtually any type of application or backend service without provisioning or managing servers. You can invoke Lambda functions from over 200 AWS services and software-as-a-service (SaaS) applications.
- Amazon Simple Storage Service (Amazon S3) is an object storage service offering industry-leading scalability, data availability, security, and performance. You can use Amazon S3 to securely store objects and also serve static websites.
- Amazon Transcribe is an automatic speech recognition (ASR) service that makes it straightforward for developers to add speech-to-text capability to their applications.
For integration between services, we use API Gateway as an event trigger for our Lambda function, and DynamoDB as a highly scalable database to store our customer details. Finally, video or audio files uploaded are stored securely in an S3 bucket.
The end-to-end solution for the video insights and summarization engine starts with the UI. We build a simple static web application hosted in Amazon S3 and deploy an Amazon CloudFront distribution to serve the static website for low latency and high transfer speeds. We use CloudFront origin access control (OAC) to secure Amazon S3 origins and permit access to the designated CloudFront distributions only. With Amazon Cognito, we are able to protect the web application from unauthenticated users.
We use API Gateway as the entry point for real-time communications between the frontend and backend of the video insights and summarization engine, while controlling access using Amazon Cognito as the authorizer. With Lambda integration, we can create a web API with an endpoint to the Lambda function.
To start the workflow, upload a raw video file directly into an S3 bucket with the pre-signed URL given through API Gateway and a Lambda function. The updated video is fed into Amazon Transcribe, which converts the speech of the video into a video transcript in text format. Finally, we use large language models (LLMs) available through Amazon Bedrock to summarize the video transcript and extract insights from the video content.
The solution stores uploaded videos and video transcripts in Amazon S3, which offers durable, highly available, and scalable data storage at a low cost. We also store the video summaries, sentiments, insights, and other workflow metadata in DynamoDB, a NoSQL database service that allows you to quickly keep track of the workflow status and retrieve relevant information from the original video.
We also use Amazon CloudWatch and Amazon EventBridge to monitor every component of the workflow in real time and respond as necessary.
AI/ML workflow
In this post, we focus on the workflow using AWS AI/ML services to generate the summarized content and extract insights from the video transcript.
Starting with the Amazon Transcribe StartTranscriptionJob API, we transcribe the original video stored in Amazon S3 into a JSON file. The following code shows an example of this using Python:
The following is an example of our workload’s Amazon Transcribe output in JSON format:
As the output from Amazon Transcribe is created and stored in Amazon S3, we use Amazon S3 Event Notifications to invoke an event to a Lambda function when the transcription job is finished and a video transcript file object has been created.
In the next step of the workflow, we use LLMs available through Amazon Bedrock. LLMs are neural network-based language models containing hundreds of millions to over a trillion parameters. The ability to generate content has resulted in LLMs being widely utilized for use cases such as text generation, summarization, translation, sentiment analysis, conversational chatbots, and more. For this solution, we use Anthropic’s Claude 3 on Amazon Bedrock to summarize the original text, get the sentiment of the conversation, extract logged actions, and suggest further actions for the sales team. In Amazon Bedrock, you can also use other LLMs for text summarization such as Amazon Titan, Meta Llama 3, and others, which can be invoked using the Amazon Bedrock API.
As shown in the following Python code to summarize the video transcript, you can call the InvokeEndpoint API to invoke the specified Amazon Bedrock model to run inference using the input provided in the request body:
You can invoke the endpoint with different parameters defined in the payload to impact the text summarization:
- temperature –
temperatureis used in text generation to control the level of randomness of the output. A lowertemperaturevalue results in a more conservative and deterministic output; a highertemperaturevalue encourages more diverse and creative outputs. - top_p –
top_p, also known as nucleus sampling, is another parameter to control the diversity of the summaries text. It indicates the cumulative probability threshold to select the next token during the text generation process. Lower values oftop_presult in a narrower selection of tokens with high probabilities, leading to more deterministic outputs. Conversely, higher values oftop_pintroduce more randomness and diversity into the generated summaries.
Although there’s no universal optimal combination of top_p and temperature for all scenarios, in the preceding code, we demonstrate sample values with high top_p and low temperature in order to generate summaries focused on key information, maintaining fidelity to the original video transcript while still introducing some degree of wording variation.
The following is another example of using the Anthropic’s Claude 3 model through the Amazon Bedrock API to provide suggested actions to sales representatives based on the video transcript:
After we successfully generate video summaries, sentiments, logged actions, and suggested actions from the original video transcript, we store these insights in a DynamoDB table, which is then updated in the UI through API Gateway.
The following screenshot shows a simple UI for the video insights and summarization engine. The frontend is built on Cloudscape, an open source design system for the cloud. On average, it takes less than 5 minutes and costs no more than $2 to process 1 hour of video, assuming the video’s transcript contains approximately 8,000 words.

Future improvements
The solution in this post shows how you can use AWS services with Amazon Bedrock to build a cost-effective and powerful generative AI application that allows you to analyze video content and extract insights to help teams become more efficient. This solution is just the beginning of the value you can unlock with AWS generative AI and broader ML services.
One example of how this solution could be taken further is to expand the scope to help tackle some of the logged actions from calls. The addition of services such as Amazon Bedrock Agents could help automate some of the responses, such as forwarding relevant documentation like product specifications, price lists, or even a simple recap email. All of these could save effort and time, enabling you to focus more on value-added activities.
Similarly, the centralization of all this data could allow you to create an analytics layer on top of a centralized database to help formulate more effective sales and support strategies. This data is usually lost or misplaced within organizations because people prefer different methods for note collection. The proposed solution gives you the freedom to centralize data but also augment organization data with the voice of the customer. For example, the analytics team could analyze what employees did well in calls that have a positive sentiment and offer training or guidance to help everyone achieve more positive customer interactions.
Conclusion
In this post, we described how to create a solution that ingests video and audio files to create powerful, actionable, and accurate insights that an organization can use through the power of Amazon Bedrock generative AI capabilities on AWS. The insights provided can help reduce the undifferentiated heavy lifting that customer-facing teams encounter, and also provide a centralized dataset of customer conversations that an organization can use to further improve performance.
For further information on how you can use Amazon Bedrock for your workloads, see Amazon Bedrock.
About the Authors
 Simone Zucchet is a Solutions Architect Manager at AWS. With over 6 years of experience as a Cloud Architect, Simone enjoys working on innovative projects that help transform the way organizations approach business problems. He helps support large enterprise customers at AWS and is part of the Machine Learning TFC. Outside of his professional life, he enjoys working on cars and photography.
Simone Zucchet is a Solutions Architect Manager at AWS. With over 6 years of experience as a Cloud Architect, Simone enjoys working on innovative projects that help transform the way organizations approach business problems. He helps support large enterprise customers at AWS and is part of the Machine Learning TFC. Outside of his professional life, he enjoys working on cars and photography.
 Vu San Ha Huynh is a Solutions Architect at AWS. He has a PhD in computer science and enjoys working on different innovative projects to help support large enterprise customers.
Vu San Ha Huynh is a Solutions Architect at AWS. He has a PhD in computer science and enjoys working on different innovative projects to help support large enterprise customers.
 Adam Raffe is a Principal Solutions Architect at AWS. With over 8 years of experience in cloud architecture, Adam helps large enterprise customers solve their business problems using AWS.
Adam Raffe is a Principal Solutions Architect at AWS. With over 8 years of experience in cloud architecture, Adam helps large enterprise customers solve their business problems using AWS.
 Ahmed Raafat is a Principal Solutions Architect at AWS, with 20 years of field experience and a dedicated focus of 6 years within the AWS ecosystem. He specializes in AI/ML solutions. His extensive experience spans various industry verticals, making him a trusted advisor for numerous enterprise customers, helping them seamlessly navigate and accelerate their cloud journey.
Ahmed Raafat is a Principal Solutions Architect at AWS, with 20 years of field experience and a dedicated focus of 6 years within the AWS ecosystem. He specializes in AI/ML solutions. His extensive experience spans various industry verticals, making him a trusted advisor for numerous enterprise customers, helping them seamlessly navigate and accelerate their cloud journey.
Author: Simone Zucchet