

Automate invoice processing with Streamlit and Amazon Bedrock
Invoice processing is a critical yet often cumbersome task for businesses of all sizes, especially for large enterprises dealing with invoices from multiple vendors with varying formats… The sheer volume of data, coupled with the need for accuracy and efficiency, can make invoice processing a sign…
Invoice processing is a critical yet often cumbersome task for businesses of all sizes, especially for large enterprises dealing with invoices from multiple vendors with varying formats. The sheer volume of data, coupled with the need for accuracy and efficiency, can make invoice processing a significant challenge. Invoices can vary widely in format, structure, and content, making efficient processing at scale difficult. Traditional methods relying on manual data entry or custom scripts for each vendor’s format can not only lead to inefficiencies, but can also increase the potential for errors, resulting in financial discrepancies, operational bottlenecks, and backlogs.
To extract key details such as invoice numbers, dates, and amounts, we use Amazon Bedrock, a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies such as AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
In this post, we provide a step-by-step guide with the building blocks needed for creating a Streamlit application to process and review invoices from multiple vendors. Streamlit is an open source framework for data scientists to efficiently create interactive web-based data applications in pure Python. We use Anthropic’s Claude 3 Sonnet model in Amazon Bedrock and Streamlit for building the application front-end.
Solution overview
This solution uses the Amazon Bedrock Knowledge Bases chat with document feature to analyze and extract key details from your invoices, without needing a knowledge base. The results are shown in a Streamlit app, with the invoices and extracted information displayed side-by-side for quick review. Importantly, your document and data are not stored after processing.
The storage layer uses Amazon Simple Storage Service (Amazon S3) to hold the invoices that business users upload. After uploading, you can set up a regular batch job to process these invoices, extract key information, and save the results in a JSON file. In this post, we save the data in JSON format, but you can also choose to store it in your preferred SQL or NoSQL database.
The application layer uses Streamlit to display the PDF invoices alongside the extracted data from Amazon Bedrock. For simplicity, we deploy the app locally, but you can also run it on Amazon SageMaker Studio, Amazon Elastic Compute Cloud (Amazon EC2), or Amazon Elastic Container Service (Amazon ECS) if needed.
Prerequisites
To perform this solution, complete the following:
- Create and activate an AWS account. Make sure your AWS credentials are configured correctly.
- This tutorial assumes you have the necessary AWS Identity and Access Management (IAM) permissions.
- Install AWS Command Line Interface (AWS CLI)
- Configure AWS CLI and set the AWS Region to where you would like to run this invoice processor by following the Set up AWS temporary credentials and AWS Region for development documentation. The Region you choose must have Amazon Bedrock and Anthropic’s Claude 3 Sonnet model available.
- Install Python 3.7 or later on your local machine.
- Access to Anthropic’s Claude 3 Sonnet in Amazon Bedrock.
Install dependencies and clone the example
To get started, install the necessary packages on your local machine or on an EC2 instance. If you’re new to Amazon EC2, refer to the Amazon EC2 User Guide. This tutorial we will use the local machine for project setup.
To install dependencies and clone the example, follow these steps:
- Clone the repository into a local folder:
- Install Python dependencies
- Navigate to the project directory:
- Upgrade pip
- (Optional) Create a virtual environment isolate dependencies:
- Activate the virtual environment:
- Mac/Linux:
- Windows:
- In the cloned directory, invoke the following to install the necessary Python packages:
This will install the necessary packages, including Boto3 (AWS SDK for Python), Streamlit, and other dependencies.
- Update the
regionin theconfig.yamlfile to the same Region set for your AWS CLI where Amazon Bedrock and Anthropic’s Claude 3 Sonnet model are available.
After completing these steps, the invoice processor code will be set up in your local environment and will be ready for the next stages to process invoices using Amazon Bedrock.
Process invoices using Amazon Bedrock
Now that the environment setup is done, you’re ready to start processing invoices and deploying the Streamlit app. To process invoices using Amazon Bedrock, follow these steps:
Store invoices in Amazon S3
Store invoices from different vendors in an S3 bucket. You can upload them directly using the console, API, or as part of your regular business process. Follow these steps to upload using the CLI:
- Create an S3 bucket:
Replace
your-bucket-namewith the name of the bucket you created andyour-regionwith the Region set for your AWS CLI and inconfig.yaml(for example,us-east-1) - Upload invoices to S3 bucket. Use one of the following commands to upload the invoice to S3.
- To upload invoices to the root of the bucket:
- To upload invoices to a specific folder (for example,
invoices): - Validate the upload:
Process invoices with Amazon Bedrock
In this section, you will process the invoices in Amazon S3 and store the results in a JSON file (processed_invoice_output.json). You will extract the key details from the invoices (such as invoice numbers, dates, and amounts) and generate summaries.
You can trigger the processing of these invoices using the AWS CLI or automate the process with an Amazon EventBridge rule or AWS Lambda trigger. For this walkthrough, we will use the AWS CLI to trigger the processing.
We packaged the processing logic in the Python script invoices_processor.py, which can be run as follows:
The --prefix argument is optional. If omitted, all of the PDFs in the bucket will be processed. For example:
or
Use the solution
This section examines the invoices_processor.py code. You can chat with your document either on the Amazon Bedrock console or by using the Amazon Bedrock RetrieveAndGenerate API (SDK). In this tutorial, we use the API approach.
- Initialize the environment: The script imports the necessary libraries and initializes the Amazon Bedrock and Amazon S3 client.
- Configure : The
config.yamlfile specifies the model ID, Region, prompts for entity extraction, and the output file location for processing. - Set up API calls: The
RetrieveAndGenerateAPI fetches the invoice from Amazon S3 and processes it using the FM. It takes several parameters, such as prompt, source type (S3), model ID, AWS Region, and S3 URI of the invoice. - Batch processing: The
batch_process_s3_bucket_invoicesfunction batch process the invoices in parallel in the specified S3 bucket and writes the results to the output file (processed_invoice_output.jsonas specified byoutput_fileinconfig.yaml). It relies on the process_invoice function, which calls the Amazon Bedrock RetrieveAndGenerate API for each invoice and prompt. - Post-processing: The extracted data in
processed_invoice_output.jsoncan be further structured or customized to suit your needs.
This approach allows invoice handling from multiple vendors, each with its own unique format and structure. By using large language models (LLMs), it extracts important details such as invoice numbers, dates, amounts, and vendor information without requiring custom scripts for each vendor format.
Run the Streamlit demo
Now that you have the components in place and the invoices processed using Amazon Bedrock, it’s time to deploy the Streamlit application. You can launch the app by invoking the following command:
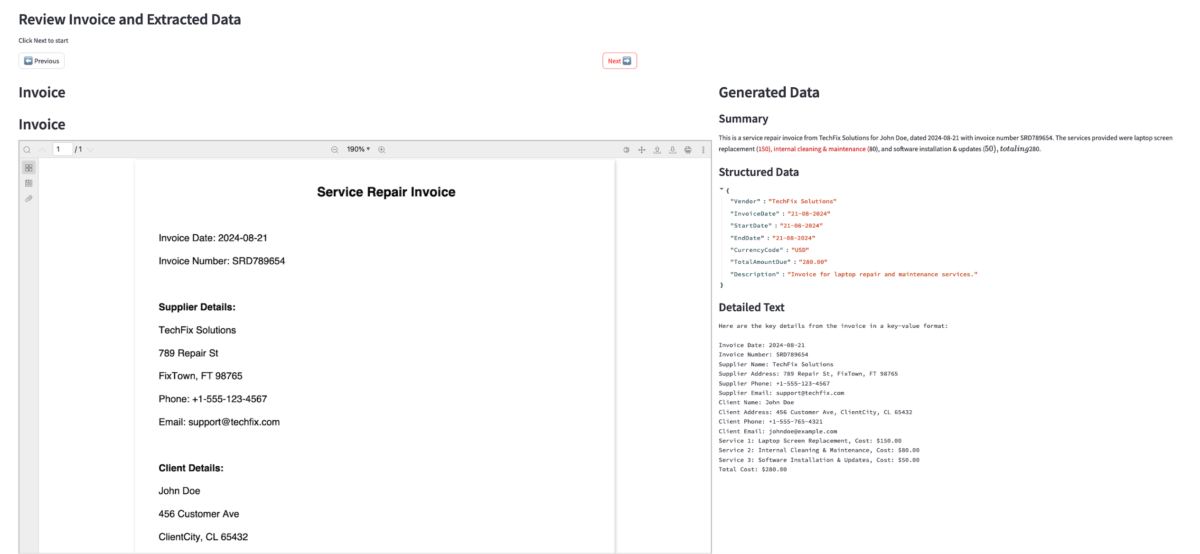
When the app is up, it will open in your default web browser. From there, you can review the invoices and the extracted data side-by-side. Use the Previous and Next arrows to seamlessly navigate through the processed invoices so you can interact with and analyze the results efficiently. The following screenshot shows the UI.

There are quotas for Amazon Bedrock (of which some are adjustable) that you need to consider when building at scale with Amazon Bedrock.
Cleanup
To clean up after running the demo, follow these steps:
- Delete the S3 bucket containing your invoices using the command
- If you set up a virtual environment, deactivate it by invoking
deactivate - Remove any local files created during the process, including the cloned repository and output files
- If you used any AWS resources such as an EC2 instance, terminate them to avoid unnecessary charges
Conclusion
In this post, we walked through a step-by-step guide to automating invoice processing using Streamlit and Amazon Bedrock, addressing the challenge of handling invoices from multiple vendors with different formats. We showed how to set up the environment, process invoices stored in Amazon S3, and deploy a user-friendly Streamlit application to review and interact with the processed data.
If you are looking to further enhance this solution, consider integrating additional features or deploying the app on scalable AWS services such as Amazon SageMaker, Amazon EC2, or Amazon ECS. Due to this flexibility, your invoice processing solution can evolve with your business, providing long-term value and efficiency.
We encourage you to learn more by exploring Amazon Bedrock, Access Amazon Bedrock foundation models, RetrieveAndGenerate API, and Quotas for Amazon Bedrock and building a solution using the sample implementation provided in this post and a dataset relevant to your business. If you have questions or suggestions, leave a comment.
About the Authors
 Deepika Kumar is a Solution Architect at AWS. She has over 13 years of experience in the technology industry and has helped enterprises and SaaS organizations build and securely deploy their workloads on the cloud securely. She is passionate about using Generative AI in a responsible manner whether that is driving product innovation, boost productivity or enhancing customer experiences.
Deepika Kumar is a Solution Architect at AWS. She has over 13 years of experience in the technology industry and has helped enterprises and SaaS organizations build and securely deploy their workloads on the cloud securely. She is passionate about using Generative AI in a responsible manner whether that is driving product innovation, boost productivity or enhancing customer experiences.
 Jobandeep Singh is an Associate Solution Architect at AWS specializing in Machine Learning. He supports customers across a wide range of industries to leverage AWS, driving innovation and efficiency in their operations. In his free time, he enjoys playing sports, with a particular love for hockey.
Jobandeep Singh is an Associate Solution Architect at AWS specializing in Machine Learning. He supports customers across a wide range of industries to leverage AWS, driving innovation and efficiency in their operations. In his free time, he enjoys playing sports, with a particular love for hockey.
 Ratan Kumar is a solutions architect based out of Auckland, New Zealand. He works with large enterprise customers helping them design and build secure, cost-effective, and reliable internet scale applications using the AWS cloud. He is passionate about technology and likes sharing knowledge through blog posts and twitch sessions.
Ratan Kumar is a solutions architect based out of Auckland, New Zealand. He works with large enterprise customers helping them design and build secure, cost-effective, and reliable internet scale applications using the AWS cloud. He is passionate about technology and likes sharing knowledge through blog posts and twitch sessions.
Author: Deepika Kumar