

Orchestrate generative AI workflows with Amazon Bedrock and AWS Step Functions
5 Haiku on Amazon Bedrock in a supported AWS Region (we will use us-west-2) Create a State Machine and add a Map state In the AWS console in the us-west-2 Region, launch into Step Functions, and select Get started and Create your own to open a blank canvas in Step Functions Workflow Studio… T…
Companies across all industries are harnessing the power of generative AI to address various use cases. Cloud providers have recognized the need to offer model inference through an API call, significantly streamlining the implementation of AI within applications. Although a single API call can address simple use cases, more complex ones may necessitate the use of multiple calls and integrations with other services.
This post discusses how to use AWS Step Functions to efficiently coordinate multi-step generative AI workflows, such as parallelizing API calls to Amazon Bedrock to quickly gather answers to lists of submitted questions. We also touch on the usage of Retrieval Augmented Generation (RAG) to optimize outputs and provide an extra layer of precision, as well as other possible integrations through Step Functions.
Introduction to Amazon Bedrock and Step Functions
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI. Using Amazon Bedrock, you can easily experiment with and evaluate top FMs for your use case, privately customize them with your data using techniques such as fine-tuning and Retrieval Augmented Generation (RAG), and build agents that execute tasks using your enterprise systems and data sources. Since Amazon Bedrock is serverless, you don’t have to manage any infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with.
AWS Step Functions is a fully managed service that makes it easier to coordinate the components of distributed applications and microservices using visual workflows. Building applications from individual components that each perform a discrete function helps you scale more easily and change applications more quickly. Step Functions is a reliable way to coordinate components and step through the functions of your application. Step Functions provides a graphical console to arrange and visualize the components of your application as a series of steps. This makes it easier to build and run multi-step applications. Step Functions automatically triggers and tracks each step and retries when there are errors, so your application executes in order and as expected. Step Functions logs the state of each step, so when things do go wrong, you can diagnose and debug problems more quickly. You can change and add steps without even writing code, so you can more easily evolve your application and innovate faster.
Orchestrating parallel tasks using the map functionality
Arrays are fundamental data structures in programming, consisting of ordered collections of elements. In the context of Step Functions, arrays play a crucial role in enabling parallel processing and efficient task orchestration. The map functionality in Step Functions uses arrays to execute multiple tasks concurrently, significantly improving performance and scalability for workflows that involve repetitive operations. Step Functions provides two different mapping strategies for iterating through arrays: inline mapping and distributed mapping, each with its own advantages and use cases.
Inline mapping
The inline map functionality allows you to perform parallel processing of array elements within a single Step Functions state machine execution. This approach is suitable when you have a relatively small number of items to process and when the processing of each item is independent of the others.
Here’s how it works:
- You define a Map state in your Step Functions state machine.
- Step Functions iterates over the array and runs the specified tasks for each element concurrently.
- The results of each iteration are collected and made available for subsequent steps in the state machine.
Inline mapping is efficient for lightweight tasks and helps avoid launching multiple Step Functions executions, which can be more costly and resource intensive. But there are limitations. When using inline mapping, only JSON payloads can be accepted as input, your workflow’s execution history can’t exceed 25,000 entries, and you can’t run more than 40 concurrent map iterations.
Distributed mapping
The distributed map functionality is designed for scenarios where many items need to be processed or when the processing of each item is resource intensive or time-consuming. Instead of handling all items within a single execution, Step Functions launches a separate execution for each item in the array, letting you concurrently process large-scale data sources stored in Amazon Simple Storage Service (Amazon S3), such as a single JSON or CSV file containing large amounts of data, or even a large set of Amazon S3 objects. This approach offers the following advantages:
- Scalability – By distributing the processing across multiple executions, you can scale more efficiently and take advantage of the built-in parallelism in Step Functions
- Fault isolation – If one execution fails, it doesn’t affect the others, providing better fault tolerance and reliability
- Resource management – Each execution can be allocated its own resources, helping prevent resource contention and providing consistent performance
However, distributed mapping can incur additional costs due to the overhead of launching multiple Step Functions executions.
Choosing a mapping approach
In summary, inline mapping is suitable for lightweight tasks with a relatively small number of items, whereas distributed mapping is better suited for resource-intensive tasks or large datasets that require better scalability and fault isolation. The choice between the two mapping strategies depends on the specific requirements of your application, such as the number of items, the complexity of processing, and the desired level of parallelism and fault tolerance.
Another important consideration when building generative AI applications using Amazon Bedrock and Step Functions Map states together would be the Amazon Bedrock runtime quotas. Generally, these model quotas allow for hundreds or even thousands of requests per minute. However, you may run into issues trying to run a large map on models with low requests processed per minute quotas, such as image generation models. In that scenario, you can include a retrier in the error handling of your Map state.
Solution overview
In the following sections, we get hands-on to see how this solution works. Amazon Bedrock has a variety of model choices to address specific needs of individual use cases. For the purposes of this exercise, we use Amazon Bedrock to run inference on Anthropic’s Claude 3.5 Haiku model to receive answers to an array of questions because it’s a performant, fast, and cost-effective option.
Our goal is to create an express state machine in Step Functions using the inline Map state to parse through the JSON array of questions sent by an API call from an application. For each question, Step Functions will scale out horizontally, creating a simultaneous call to Amazon Bedrock. After all the answers come back, Step Functions will concatenate them into a single response, which our original calling application can then use for further processing or displaying to end-users.
The payload we send consists of an array of nine Request for Proposal (RFP) questions, as well as a company description:
You can use the step-by-step guide in this post or use the prebuilt AWS CloudFormation template in the us-west-2 Region to provision the necessary AWS resources. AWS CloudFormation gives developers and businesses a straightforward way to create a collection of related AWS and third-party resources, and provision and manage them in an orderly and predictable fashion.
Prerequisites
You need the following prerequisites to follow along with this solution implementation:
- An AWS account
- An AWS Identity and Access Management (IAM) user that has access to Amazon Bedrock and Step Functions
- Model access to Anthropic Claude 3.5 Haiku on Amazon Bedrock in a supported AWS Region (we will use
us-west-2)
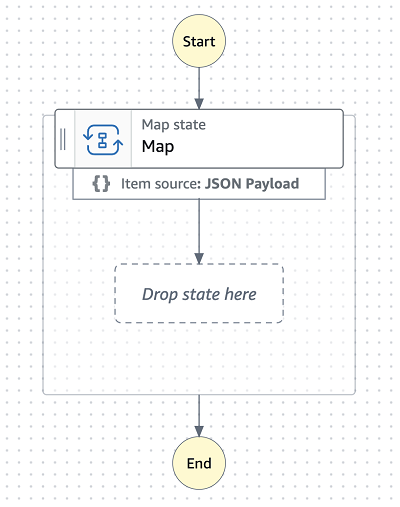
Create a State Machine and add a Map state
In the AWS console in the us-west-2 Region, launch into Step Functions, and select Get started and Create your own to open a blank canvas in Step Functions Workflow Studio.
Edit the state machine by adding an inline Map state with items sourced from a JSON payload.

Next, tell the Map state where the array of questions is located by selecting Provide a path to items array and pointing it to the questions array using JSONPath syntax. Selecting Modify items with ItemSelector allows you to structure the payload, which is then sent to each of the child workflow executions. Here, we map the description through with no change and use $$.Map.Item.Value to map the question from the array at the index of the map iteration.

Invoke an Amazon Bedrock model
Next, add a Bedrock: InvokeModel action task as the next state within the Map state.

Now you can structure your Amazon Bedrock API calls through Workflow Studio. Because we’re using Anthropic’s Claude 3.5 Haiku model on Amazon Bedrock, we select the corresponding model ID for Bedrock model identifier and edit the provided sample with instructions to incorporate the incoming payload. Depending on which model you select, the payload may have a different structure and prompt syntax.

Build the payload
The prompt you build uses the Amazon State Language intrinsic function States.Format in order to do string interpolation, substituting {} for the variables declared after the string. We must also include .$ after our text key to reference a node in this state’s JSON input.
When building out this prompt, you should be very prescriptive in asking the model to do the following:
- Answer the questions thoroughly using the following description
- Not repeat the question
- Only respond with the answer to the question
We set the max_tokens to 800 to allow for longer responses from Amazon Bedrock. Additionally, you can include other inference parameters such as temperature, top_p, top_k, and stop_sequences. Tuning these parameters can help limit the length or influence the randomness or diversity of the model’s response. For the sake of this example, we keep all other optional parameters as default.
Form the response
To provide a cleaner response back to our calling application, we want to use some options to transform the output of the Amazon Bedrock Task state. First, use ResultSelector to filter the response coming back from the service to pull out the text completion, then add the original input back to the output using ResultPath and finish by filtering the final output using OutputPath. That way you don’t have to see the description being mapped unnecessarily for each array item.

To simulate the state machine being called by an API, choose Execute in Workflow Studio. Using the preceding input, the Step Functions output should look like the following code, although it may vary slightly due to the diversity and randomness of FMs:
Clean up resources
To delete this solution, navigate to the State machines page on the Step Functions console, select your state machine, choose Delete, and enter delete to confirm. It will be marked for deletion and will be deleted when all executions are stopped.
RAG and other possible integrations
RAG is a strategy that enhances the output of a large language model (LLM) by allowing it to reference an authoritative external knowledge base, generating more accurate or secure responses. This powerful tool can extend the capabilities of LLMs to specific domains or an organization’s internal knowledge base without needing to retrain or even fine-tune the model.
A straightforward way to integrate RAG into the preceding RFP example is by adding a Bedrock Runtime Agents: Retrieve action task to your Map state before invoking the model. This enables queries to Amazon Bedrock Knowledge Bases, which supports various vector storage databases, including the Amazon OpenSearch Serverless vector engine, Pinecone, Redis Enterprise Cloud, and soon Amazon Aurora and MongoDB. Using Knowledge Bases to ingest and vectorize example RFPs and documents stored in Amazon S3 eliminates the need to include a description with the question array. Also, because a vector store can accommodate a broader range of information than a single prompt is able to, RAG can greatly enhance the specificity of the responses.
In addition to Amazon Bedrock Knowledge Bases, there are other options to integrate for RAG depending on your existing tech stack, such as directly with an Amazon Kendra Task state or with a vector database of your choosing through third-party APIs using HTTP Task states.

Step Functions offers composability, allowing you to seamlessly integrate over 9,000 AWS API actions from more than 200 services directly into your workflows. These optimized service integrations simplify the use of common services like AWS Lambda, Amazon Elastic Container Service (Amazon ECS), AWS Glue, and Amazon EMR, offering features such as IAM policy generation and the Run A Job (.sync) pattern, which automatically waits for the completion of asynchronous jobs. Another common pattern seen in generative AI applications is chaining models together to accomplish secondary tasks, like language translation after a primary summarization task is completed. This can be accomplished by adding another Bedrock: InvokeModel action task just as we did earlier.
Conclusion
In this post, we demonstrated the power and flexibility of Step Functions for orchestrating parallel calls to Amazon Bedrock. We explored two mapping strategies—inline and distributed—for processing small and large datasets, respectively. Additionally, we delved into a practical use case of answering a list of RFP questions, demonstrating how Step Functions can efficiently scale out and manage multiple Amazon Bedrock calls.
We introduced the concept of RAG as a strategy for enhancing the output of an LLM by referencing an external knowledge base and demonstrated multiple ways to incorporate RAG into Step Functions state machines. We also highlighted the integration capabilities of Step Functions, particularly the ability to invoke over 9,000 AWS API actions from more than 200 services directly from your workflow.
As next steps, explore the possibilities of application patterns offered by the GenAI Quick Start PoCs GitHub repo as well as various Step Functions integrations through sample project templates within Workflow Studio. Also, consider integrating RAG into your workflows to use your organization’s internal knowledge base or specific domain expertise.
About the Author
 Dimitri Restaino is a Brooklyn-based AWS Solutions Architect specialized in designing innovative and efficient solutions for healthcare companies, with a focus on the potential applications of AI, blockchain and other promising industry disruptors. Off the clock, he can be found spending time in nature or setting fastest laps in his racing sim.
Dimitri Restaino is a Brooklyn-based AWS Solutions Architect specialized in designing innovative and efficient solutions for healthcare companies, with a focus on the potential applications of AI, blockchain and other promising industry disruptors. Off the clock, he can be found spending time in nature or setting fastest laps in his racing sim.
Author: Dimitri Restaino