

Container Insights with enhanced observability now available in Amazon ECS
Using container insights with enhanced observability for Amazon ECSThere are two ways to enable Container Insights with enhanced observability: Cluster-level onboarding – You can enable it for specific clusters individually… Account-level onboarding – You can also enable it at the ac…
Last year, we announced enhanced observability in Amazon CloudWatch Container Insights, a new capability to improve your observability for Amazon Elastic Kubernetes Service (Amazon EKS). This capability helps you detect and fix container issues faster by providing detailed performance metrics and logs.
Expanding this capability, today we’re launching enhanced observability for your container workloads running on Amazon Elastic Container Service (Amazon ECS). This new capability will help reduce your mean time to detect (MTTD) and mean time to repair (MTTR) for your overall applications, helping prevent issues that could negatively impact your user experience.
Here’s a quick look at Container Insights with enhanced observability for Amazon ECS.

Container Insights with enhanced observability addresses a critical gap in container monitoring. Previously, correlating metrics with logs and events was a time-consuming process, often requiring manual searches and expertise in application architecture. Now, with this capability, CloudWatch and Amazon ECS automatically collect granular performance metrics such as CPU utilization at both the task and container levels while providing visual drill downs enabling easy root-cause analysis.
This new capability enables the following use cases:
- Quickly identify root causes by viewing granular resource usage patterns and correlating telemetry data.
- Proactively manage your ECS resources using curated dashboards based on AWS best practices.
- Track your recent deployments and root causes of your deployment failures with the matching infrastructure anomalies enabling faster issue detection and quicker rollbacks when necessary.
- Effortlessly monitor resources across multiple accounts without manual setup. Built-in cross-account support reduces operational overhead with single pane of glass observability.
- Integration with other CloudWatch services such as Application Signals and CloudWatch Logs provides a seamless experience to correlate infrastructure with the services running and identify the impacted services.
Using container insights with enhanced observability for Amazon ECS
There are two ways to enable Container Insights with enhanced observability:
- Cluster-level onboarding – You can enable it for specific clusters individually.
- Account-level onboarding – You can also enable it at the account level, which automatically enables observability for all new clusters created in your account. This approach saves time and effort by eliminating the need to manually enable it for each new cluster.
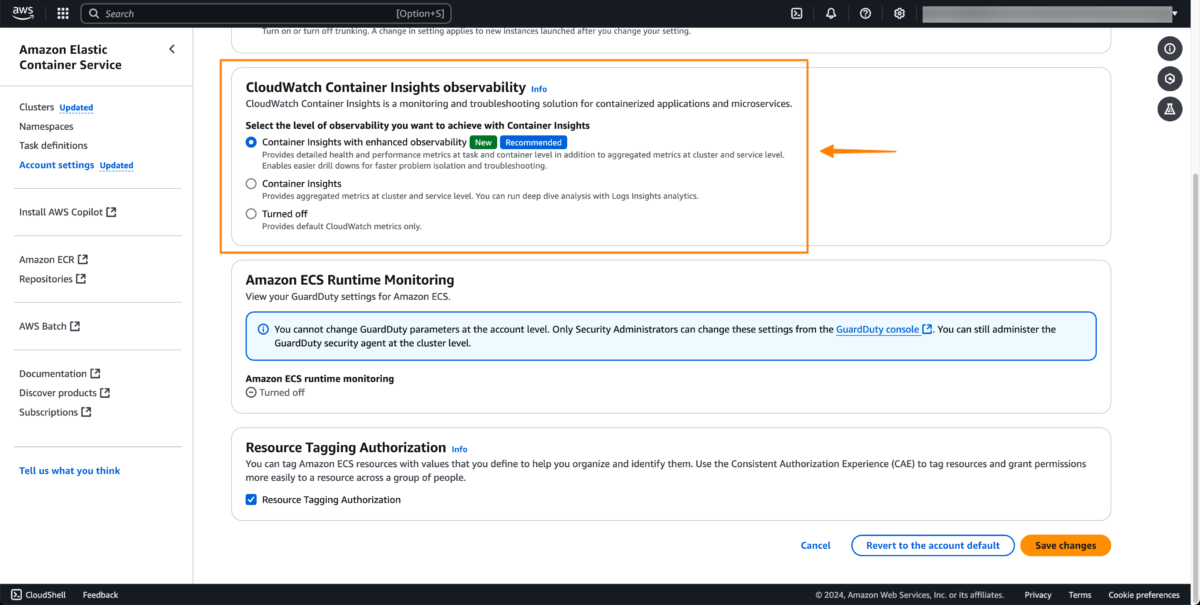
To enable this feature at the account level, I navigate to the Amazon ECS console and select Account settings. Under the CloudWatch Container Insights observability section, I can see it’s currently disabled. I choose Update.

On this page, I find a new option called Container Insights with enhanced observability. I select this option and then choose Save changes.

If I need to enable this capability at the cluster level, I can do so when creating a new cluster.

I can also enable this capability for my existing clusters. To do so, I select Update cluster, and then choose the option.

Once enabled, I can see task-level metrics by navigating to the Metrics tab in my cluster overview console. To access health and performance metrics across my clusters, I can select View Container Insights, which will redirect me to the Container Insights page.

To get a big picture of all my workloads across different clusters, I can navigate to Amazon CloudWatch and then to Container Insights.

This view addresses the challenge of effectively monitoring clusters, services, tasks, and containers by providing a honeycomb visualization that offers an intuitive, high-level summary of cluster health. The dashboard employs a dual-state monitoring approach:
- Alarm state (red or green) – Reflects customer-defined thresholds and alerts, allowing teams to configure monitoring based on their specific requirements
- Utilization state (dark blue or light blue) – Uses CloudWatch built-in best practices to monitor resource usage patterns across containers. The darker blue indicates clusters operating under higher utilization, enabling teams to proactively identify potential resource constraints before they impact performance
Let’s say there’s an issue in one of my clusters. I can hover over the cluster to display all the alarms created under that cluster at different layers, from the cluster layer down to the container layer.

I also have the option to view all clusters in a list format. The list format is essential for cross-account observability, displaying account IDs and labels for cluster ownership. This helps DevOps engineers quickly identify and collaborate with account owners to resolve potential application issues.

Now, I’d like to explore further. I select my cluster link, which redirects me to the Container Insights detailed dashboard view. Here, I can see a spike in memory utilization for this cluster.

I can dive deeper into container-level details, which help me quickly identify which services are causing this issue.

Another useful feature I found is the Filters option, which helps me conduct more thorough investigations across containers, services, or tasks in this cluster.

If I need to delve deeper into the application logs to understand the root cause of this issue, I can select the task, choose Actions, and choose which logs I would like to view.
On top of using AWS X-Ray traces, I can investigate another two types of logs here. First, I can use performance logs—structured logs containing metric data—to drill down and identify container-level root causes. Second, I examine collected application or container logs . These logs give me detailed insights into application behavior within the container, helping me trace the sequence of events that led to any issues.
In this case, I use application logs.

This streamlines my journey to troubleshoot my application. In this case, the issue is on the downstream calls to third-party applications, which return timeouts.

This enhanced capability also works with Amazon CloudWatch Application Signals to automatically instrument my application. I can monitor current application health and track long-term application performance against service-level objectives.
I select the Application Signals tab.

This integration with Amazon CloudWatch Application Signals provides me with end-to-end visibility, helping me correlate container performance with end-user experience.
When I select datapoints in the graphs, I can see associated traces, which show me all correlated services and their impact. I can also access relevant logs to understand root causes.

Additional things to know
Here are a couple of important points to note:
- Availability – Container Insights with enhanced observability for ECS is now available in all AWS Regions including the China Regions.
- Pricing – Container Insights with enhanced observability for ECS comes with a flat metric pricing, visit the Amazon CloudWatch Pricing page.
Get started today and experience improved observability for your container workloads. Learn more on the Amazon CloudWatch documentation page.
Happy monitoring,
— Donnie Prakoso
Author: Donnie Prakoso