

How Amazon trains sequential ensemble models at scale with Amazon SageMaker Pipelines
This helps with data preparation and feature engineering tasks and model training and deployment automation… In this post, we provide an example of an ensemble model that was trained and deployed using Pipelines… With the ability to preprocess incoming data prior to training, we can make sure …
Amazon SageMaker Pipelines includes features that allow you to streamline and automate machine learning (ML) workflows. This allows scientists and model developers to focus on model development and rapid experimentation rather than infrastructure management
Pipelines offers the ability to orchestrate complex ML workflows with a simple Python SDK with the ability to visualize those workflows through SageMaker Studio. This helps with data preparation and feature engineering tasks and model training and deployment automation. Pipelines also integrates with Amazon SageMaker Automatic Model Tuning which can automatically find the hyperparameter values that result in the best performing model, as determined by your chosen metric.
Ensemble models are becoming popular within the ML communities. They generate more accurate predictions through combining the predictions of multiple models. Pipelines can quickly be used to create and end-to-end ML pipeline for ensemble models. This enables developers to build highly accurate models while maintaining efficiency, and reproducibility.
In this post, we provide an example of an ensemble model that was trained and deployed using Pipelines.
Use case overview
Sales representatives generate new leads and create opportunities within Salesforce to track them. The following application is a ML approach using unsupervised learning to automatically identify use cases in each opportunity based on various text information, such as name, description, details, and product service group.
Preliminary analysis showed that use cases vary by industry and different use cases have a very different distribution of annualized revenue and can help with segmentation. Hence, a use case is an important predictive feature that can optimize analytics and improve sales recommendation models.
We can treat the use case identification as a topic identification problem and we explore different topic identification models such as Latent Semantic Analysis (LSA), Latent Dirichlet Allocation (LDA), and BERTopic. In both LSA and LDA, each document is treated as a collection of words only and the order of the words or grammatical role does not matter, which may cause some information loss in determining the topic. Moreover, they require a pre-determined number of topics, which was hard to determine in our data set. Since, BERTopic overcame the above problem, it was used in order to identify the use case.
The approach uses three sequential BERTopic models to generate the final clustering in a hierarchical method.
Each BERTopic model consists of four parts:
- Embedding – Different embedding methods can be used in BERTopic. In this scenario, input data comes from various areas and is usually inputted manually. As a result, we use sentence embedding to ensure scalability and fast processing.
- Dimension reduction – We use Uniform Manifold Approximation and Projection (UMAP), which is an unsupervised and nonlinear dimension reduction method, to reduce high dimension text vectors.
- Clustering – We use the Balanced Iterative Reducing and Clustering using Hierarchies (BIRCH) method to form different use case clusters.
- Keyword identification – We use class-based TF-IDF to extract the most representative words from each cluster.
Sequential ensemble model
There is no predetermined number of topics, so we set an input for the number of clusters to be 15–25 topics. Upon observation, some of the topics are wide and general. Therefore, another layer of the BERTopic model is applied individually to them. After combining all of the newly identified topics in the second-layer model and together with the original topics from first-layer results, postprocessing is performed manually to finalize topic identification. Lastly, a third layer is used for some of the clusters to create sub-topics.
To enable the second- and third-layer models to work effectively, you need a mapping file to map results from previous models to specific words or phrases. This helps make sure that the clustering is accurate and relevant.
We’re using Bayesian optimization for hyperparameter tuning and cross-validation to reduce overfitting. The data set contains features like opportunity name, opportunity details, needs, associated product name, product details, product groups. The models are evaluated using a customized loss function, and the best embedding model is selected.
Challenges and considerations
Here are some of the challenges and considerations of this solution:
- The pipeline’s data preprocessing capability is crucial for enhancing model performance. With the ability to preprocess incoming data prior to training, we can make sure that our models are fed with high-quality data. Some of the preprocessing and data cleaning steps include converting all text column to lower case, removing template elements, contractions, URLs, emails, etc. removing non-relevant NER labels, and lemmatizing combined text. The result is more accurate and reliable predictions.
- We need a compute environment that is highly scalable so that we can effortlessly handle and train millions of rows of data. This allows us to perform large-scale data processing and modeling tasks with ease and reduces development time and costs.
- Because every step of the ML workflow requires varying resource requirements, a flexible and adaptable pipeline is essential for efficient resource allocation. We can reduce the overall processing time, resulting in faster model development and deployment, by optimizing resource usage for each step.
- Running custom scripts for data processing and model training requires the availability of required frameworks and dependencies.
- Coordinating the training of multiple models can be challenging, especially when each subsequent model depends on the output of the previous one. The process of orchestrating the workflow between these models can be complex and time-consuming.
- Following each training layer, it’s necessary to revise a mapping that reflects the topics produced by the model and use it as an input for the subsequent model layer.
Solution overview
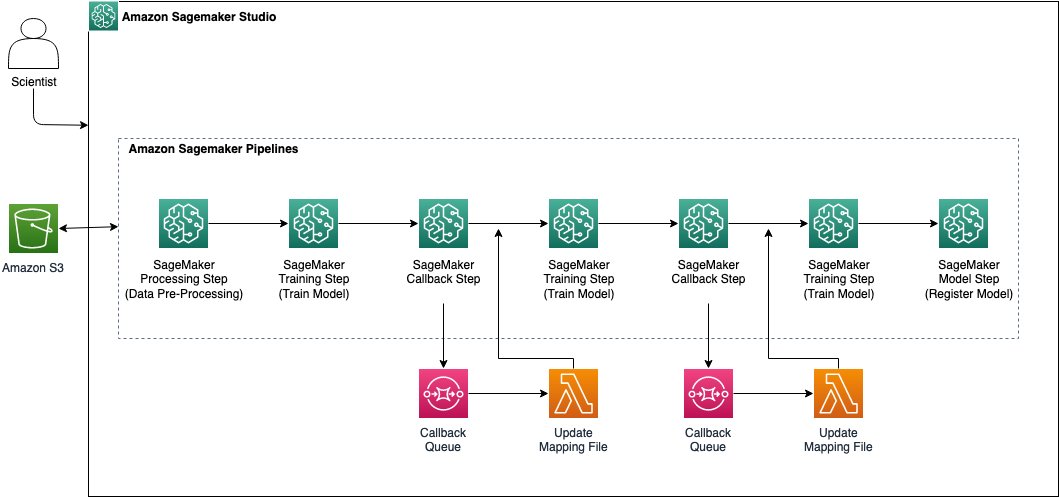
In this solution, the entry point is Amazon SageMaker Studio, which is a web-based integrated development environment (IDE) provided by AWS that enables data scientists and ML developers to build, train, and deploy ML models at scale in a collaborative and efficient manner.
The following diagrams illustrates the high-level architecture of the solution.

As part of the architecture, we’re using the following SageMaker pipeline steps:
- SageMaker Processing – This step allows you to preprocess and transform data before training. One benefit of this step is the ability to use built-in algorithms for common data transformations and automatic scaling of resources. You can also use custom code for complex data preprocessing, and it allows you to use custom container images.
- SageMaker Training – This step allows you to train ML models using SageMaker-built-in algorithms or custom code. You can use distributed training to accelerate model training.
- SageMaker Callback – This step allows you to run custom code during the ML workflow, such as sending notifications or triggering additional processing steps. You can run external processes and resume the pipeline workflow on completion in this step.
- SageMaker Model – This step allows you to create or register model to Amazon SageMaker
Implementation Walkthrough
First, we set up the Sagemaker pipeline:
import boto3
import sagemaker
# create a Session with custom region (e.g. us-east-1), will be None if not specified
region = "<your-region-name>"
# allocate default S3 bucket for SageMaker session, will be None if not specified
default_bucket = "<your-s3-bucket>"
boto_session = boto3.Session(region_name=region
sagemaker_client = boto_session.client("sagemaker")
Initialize a SageMaker Session
sagemaker_session = sagemaker.session.Session(boto_session=boto_session, sagemaker_client=sagemaker_client, default_bucket= default_bucket,)
Set Sagemaker execution role for the session
role = sagemaker.session.get_execution_role(sagemaker_session)
Manage interactions under Pipeline Context
pipeline_session = sagemaker.workflow.pipeline_context.PipelineSession(boto_session=boto_session, sagemaker_client=sagemaker_client, default_bucket=default_bucket,)
Define base image for scripts to run on
account_id = role.split(":")[4]
# create a base image that take care of dependencies
ecr_repository_name = "<your-base-image-to-run-script>".
tag = "latest"
container_image_uri = "{0}.dkr.ecr.{1}.amazonaws.com/{2}:{3}".format(account_id, region, ecr_repository_name, tag)
The following is a detailed explanation of the workflow steps:
- Preprocess the data – This involves cleaning and preparing the data for feature engineering and splitting the data into train, test, and validation sets.
import os
BASE_DIR = os.path.dirname(os.path.realpath(__file__))
from sagemaker.workflow.parameters import ParameterString
from sagemaker.workflow.steps import ProcessingStep
from sagemaker.processing import (
ProcessingInput,
ProcessingOutput,
ScriptProcessor,
)
processing_instance_type = ParameterString(
name="ProcessingInstanceType",
# choose an instance type suitable for the job
default_value="ml.m5.4xlarge"
)
script_processor = ScriptProcessor(
image_uri=container_image_uri,
command=["python"],
instance_type=processing_instance_type,
instance_count=1,
role=role,
)
# define the data preprocess job
step_preprocess = ProcessingStep(
name="DataPreprocessing",
processor=script_processor,
inputs=[
ProcessingInput(source=BASE_DIR, destination="/opt/ml/processing/input/code/")
],
outputs=[
ProcessingOutput(output_name="data_train", source="/opt/ml/processing/data_train"), # output data and dictionaries etc for later steps
]
code=os.path.join(BASE_DIR, "preprocess.py"),
)- Train layer 1 BERTopic model – A SageMaker training step is used to train the first layer of the BERTopic model using an Amazon Elastic Container Registry (Amazon ECR) image and a custom training script.
base_job_prefix="OppUseCase"
from sagemaker.workflow.steps import TrainingStep
from sagemaker.estimator import Estimator
from sagemaker.inputs import TrainingInput
training_instance_type = ParameterString(
name="TrainingInstanceType",
default_value="ml.m5.4xlarge"
)
# create an estimator for training job
estimator_first_layer = Estimator(
image_uri=container_image_uri,
instance_type=training_instance_type,
instance_count=1,
output_path= f"s3://{default_bucket}/{base_job_prefix}/train_first_layer", # S3 bucket where the training output be stored
role=role,
entry_point = "train_first_layer.py"
)
# create training job for the estimator based on inputs from data-preprocess step
step_train_first_layer = TrainingStep(
name="TrainFirstLayerModel",
estimator = estimator_first_layer,
inputs={
TrainingInput(
s3_data=step_preprocess.properties.ProcessingOutputConfig.Outputs[ "data_train" ].S3Output.S3Uri,
),
},
)- Use a callback step – This involves sending a message to an Amazon Simple Queue Service (Amazon SQS) queue, which triggers an AWS Lambda function. The Lambda function updates the mapping file in Amazon Simple Storage Service (Amazon S3) and sends a success token back to the pipeline to resume its run.
from sagemaker.workflow.callback_step import CallbackStep, CallbackOutput, CallbackOutputTypeEnum
first_sqs_queue_to_use = ParameterString(
name="FirstSQSQueue",
default_value= <first_queue_url>, # add queue url
)
first_callback_output = CallbackOutput(output_name="s3_mapping_first_update", output_type=CallbackOutputTypeEnum.String)
step_first_mapping_update = CallbackStep(
name="FirstMappingUpdate",
sqs_queue_url= first_sqs_queue_to_use,
# Input arguments that will be provided in the SQS message
inputs={
"input_location": f"s3://{default_bucket}/{base_job_prefix}/mapping",
"output_location": f"s3://{default_bucket}/{base_job_prefix}/ mapping_first_update "
},
outputs=[
first_callback_output,
],
)
step_first_mapping_update.add_depends_on([step_train_first_layer]) # call back is run after the step_train_first_layer
- Train layer 2 BERTopic model – Another SageMaker TrainingStep is used to train the second layer of the BERTopic model using an ECR image and a custom training script.
estimator_second_layer = Estimator(
image_uri=container_image_uri,
instance_type=training_instance_type, # same type as of first train layer
instance_count=1,
output_path=f"s3://{bucket}/{base_job_prefix}/train_second_layer", # S3 bucket where the training output be stored
role=role,
entry_point = "train_second_layer.py"
)
# create training job for the estimator based on inputs from preprocessing, output of previous call back step and first train layer step
step_train_second_layer = TrainingStep(
name="TrainSecondLayerModel",
estimator = estimator_second_layer,
inputs={
TrainingInput(
s3_data=step_preprocess.properties.ProcessingOutputConfig.Outputs[ "data_train"].S3Output.S3Uri,
),
TrainingInput(
# Output of the previous call back step
s3_data= step_first_mapping_update.properties.Outputs["s3_mapping_first_update"],
),
TrainingInput(
s3_data=f"s3://{bucket}/{base_job_prefix}/train_first_layer"
),
}
)
- Use a callback step – Similar to Step 3, this involves sending a message to an SQS queue which triggers a Lambda function. The Lambda function updates the mapping file in Amazon S3 and sends a success token back to the pipeline to resume its run.
second_sqs_queue_to_use = ParameterString(
name="SecondSQSQueue",
default_value= <second_queue_url>, # add queue url
)
second_callback_output = CallbackOutput(output_name="s3_mapping_second_update", output_type=CallbackOutputTypeEnum.String)
step_second_mapping_update = CallbackStep(
name="SecondMappingUpdate",
sqs_queue_url= second_sqs_queue_to_use,
# Input arguments that will be provided in the SQS message
inputs={
"input_location": f"s3://{default_bucket}/{base_job_prefix}/mapping_first_update ",
"output_location": f"s3://{default_bucket}/{base_job_prefix}/mapping_second_update "
},
outputs=[
second_callback_output,
],
)
step_second_mapping_update.add_depends_on([step_train_second_layer]) # call back is run after the step_train_second_layer
- Train layer 3 BERTopic model – This involves fetching the mapping file from Amazon S3 and training the third layer of the BERTopic model using an ECR image and a custom training script.
estimator_third_layer = Estimator(
image_uri=container_image_uri,
instance_type=training_instance_type, # same type as of prvious two train layers
instance_count=1,
output_path=f"s3://{default_bucket}/{base_job_prefix}/train_third_layer", # S3 bucket where the training output be stored
role=role,
entry_point = "train_third_layer.py"
)
# create training job for the estimator based on inputs from preprocess step, second callback step and outputs of previous two train layers
step_train_third_layer = TrainingStep(
name="TrainThirdLayerModel",
estimator = estimator_third_layer,
inputs={
TrainingInput(
s3_data=step_preprocess.properties.ProcessingOutputConfig.Outputs["data_train"].S3Output.S3Uri,
),
TrainingInput(
# s3_data = Output of the previous call back step
s3_data= step_second_mapping_update.properties.Outputs[' s3_mapping_second_update’],
),
TrainingInput(
s3_data=f"s3://{default_bucket}/{base_job_prefix}/train_first_layer"
),
TrainingInput(
s3_data=f"s3://{default_bucket}/{base_job_prefix}/train_second_layer"
),
}
)
- Register the model – A SageMaker model step is used to register the model in the SageMaker model registry. When the model is registered, you can use the model through a SageMaker inference pipeline.
from sagemaker.model import Model
from sagemaker.workflow.model_step import ModelStep
model = Model(
image_uri=container_image_uri,
model_data=step_train_third_layer.properties.ModelArtifacts.S3ModelArtifacts,
sagemaker_session=sagemaker_session,
role=role,
)
register_args = model.register(
content_types=["text/csv"],
response_types=["text/csv"],
inference_instances=["ml.c5.9xlarge", "ml.m5.xlarge"],
model_package_group_name=model_package_group_name,
approval_status=model_approval_status,
)
step_register = ModelStep(name="OppUseCaseRegisterModel", step_args=register_args)
To effectively train a BERTopic model and BIRCH and UMAP methods, you need a custom training image which can provide additional dependencies and framework required to run the algorithm. For a working sample of a custom docker image, refer to Create a custom Docker container Image for SageMaker
Conclusion
In this post, we explained how you can use wide range of steps offered by SageMaker Pipelines with custom images to train an ensemble model. For more information on how to get started with Pipelines using an existing ML Operations (MLOps) template, refer to Building, automating, managing, and scaling ML workflows using Amazon SageMaker Pipelines.
About the Authors
 Bikramjeet Singh is a Applied Scientist at AWS Sales Insights, Analytics and Data Science (SIADS) Team, responsible for building GenAI platform and AI/ML Infrastructure solutions for ML scientists within SIADS. Prior to working as an AS, Bikram worked as a Software Development Engineer within SIADS and Alexa AI.
Bikramjeet Singh is a Applied Scientist at AWS Sales Insights, Analytics and Data Science (SIADS) Team, responsible for building GenAI platform and AI/ML Infrastructure solutions for ML scientists within SIADS. Prior to working as an AS, Bikram worked as a Software Development Engineer within SIADS and Alexa AI.
 Rahul Sharma is a Senior Specialist Solutions Architect at AWS, helping AWS customers build ML and Generative AI solutions. Prior to joining AWS, Rahul has spent several years in the finance and insurance industries, helping customers build data and analytics platforms.
Rahul Sharma is a Senior Specialist Solutions Architect at AWS, helping AWS customers build ML and Generative AI solutions. Prior to joining AWS, Rahul has spent several years in the finance and insurance industries, helping customers build data and analytics platforms.
 Sachin Mishra is a seasoned professional with 16 years of industry experience in technology consulting and software leadership roles. Sachin lead the Sales Strategy Science and Engineering function at AWS. In this role, he was responsible for scaling cognitive analytics for sales strategy, leveraging advanced AI/ML technologies to drive insights and optimize business outcomes.
Sachin Mishra is a seasoned professional with 16 years of industry experience in technology consulting and software leadership roles. Sachin lead the Sales Strategy Science and Engineering function at AWS. In this role, he was responsible for scaling cognitive analytics for sales strategy, leveraging advanced AI/ML technologies to drive insights and optimize business outcomes.
 Nada Abdalla is a research scientist at AWS. Her work and expertise span multiple science areas in statistics and ML including text analytics, recommendation systems, Bayesian modeling and forecasting. She previously worked in academia and obtained her M.Sc and PhD from UCLA in Biostatistics. Through her work in academia and industry she published multiple papers at esteemed statistics journals and applied ML conferences. In her spare time she enjoys running and spending time with her family.
Nada Abdalla is a research scientist at AWS. Her work and expertise span multiple science areas in statistics and ML including text analytics, recommendation systems, Bayesian modeling and forecasting. She previously worked in academia and obtained her M.Sc and PhD from UCLA in Biostatistics. Through her work in academia and industry she published multiple papers at esteemed statistics journals and applied ML conferences. In her spare time she enjoys running and spending time with her family.
Author: Bikram Singh