

How Karrot built a feature platform on AWS, Part 2: Feature ingestion
In Part 1 of this series, we discussed how Karrot developed a new feature platform, which consists of three main components: feature serving, a stream ingestion pipeline, and a batch ingestion pipeline… We discussed their requirements, the solution architecture, and feature serving using a multi…
This post is co-written with Hyeonho Kim, Jinhyeong Seo and Minjae Kwon from Karrot.
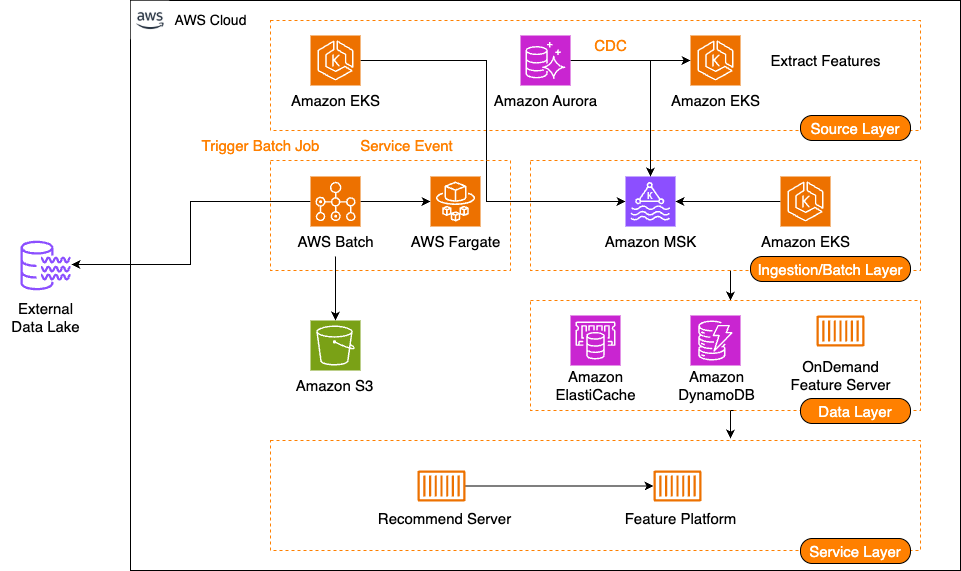
In Part 1 of this series, we discussed how Karrot developed a new feature platform, which consists of three main components: feature serving, a stream ingestion pipeline, and a batch ingestion pipeline. We discussed their requirements, the solution architecture, and feature serving using a multi-level cache. In this post, we share the stream and batch ingestion pipelines and how they ingest data into an online store from various event sources.
Solution overview
The following diagram illustrates the solution architecture, as introduced in Part 1.
Stream ingestion
Stream ingestion is the process of collecting data from various event sources in real time, transforming it into features, and storing them. It consists of two main components:
- Message broker – Amazon Managed Streaming for Apache Kafka (Amazon MSK) is used to store events published from various platform services and change data capture (CDC) events from Amazon Aurora.
- Consumer – These are pods located on Amazon Elastic Kubernetes Service (Amazon EKS) that process events according to feature group specifications defined in the feature platform and load them into the database and remote cache.
Consumers handle not only the source events, but also re-published events. When loading features, they are performed by considering different strategies, such as write-through and write-around, and are loaded in detail considering cardinality, data size, and access patterns.
Most features are generated based on two types of events: events that occur due to real-time user actions, and asynchronous events that occur due to state changes in user and article data. These events and features have an M:N relationship, meaning one event can be the source of multiple features, and one feature can be generated based on multiple events.
The following diagram illustrates the architecture of the stream ingestion pipeline.
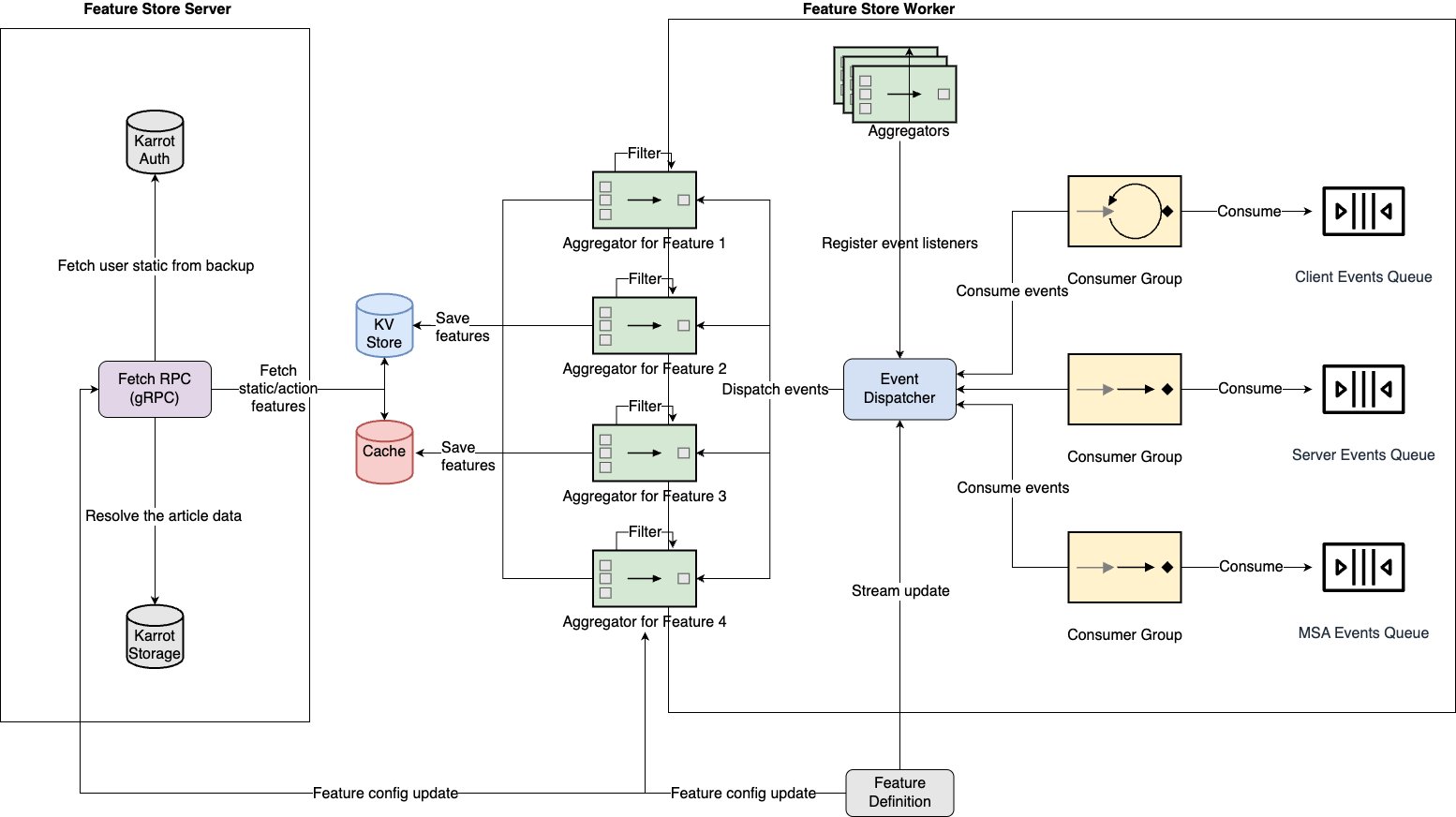
To efficiently handle M:N relationships, a structure was needed to receive events and distribute them to multiple feature processing logics. Two core components were designed for this purpose:
- Dispatcher – Receives events from multiple consumer groups and propagates them to relevant feature processing logic
- Aggregator – Processes events received from the dispatcher into actual features
This stream processing pipeline enables real-time feature generation and storage.
Message broker optimization: Fast at-least-once delivery
The feature platform processes up to 25,000 events per second, including user behavior log events, at high speed. However, when worker traffic surges, event processing failures or infrastructure failures occasionally cause event loss. To solve this problem, the existing automatic commit mode was changed to manual commit in Amazon MSK. This allows events to be committed only when they are definitely processed, and failed events are sent to a separate retry topic and postprocessed through a dedicated worker.
However, processing large volumes of events synchronously with manual commit resulted in approximately 10 times slower processing speed and increased latency. Although consumer group resources were available, simply increasing the number of partitions in Amazon MSK wasn’t a solution due to team-specific partitioning permissions. The platform designed parallel processing within single partitions and implemented a custom consumer supporting retry functionality. The core of the implementation is to read as many messages from the partition as the fetch size at a time and process them by spawning worker threads in parallel for each message. When processing is complete, the offsets of successful messages are sorted and a manual commit is performed for the largest offset, and failed messages are republished to the retry topic. This enables parallel processing even in a single partition, and the concurrency can be controlled automatically. As a result, the event processing speed is faster than the existing automatic commit method, and it is stably processed without delay even when the number of events increases.
Stream processing
The stream ingestion pipeline performs only simple extract, transform, and load (ETL) logic and validation. There were already many requirements for complex stream processing in the feature platform, and a separate service was created to accommodate them. The feature platform didn’t address these requirements for the following reasons:
- The purpose of stream ingestion in the feature platform is to collect and store features in real time, whereas the main purpose of stream processing is to process data.
- Not all features require complex processing. We decided that it wasn’t appropriate to make the entire stream collection process complicated for some features.
- The result data of stream processing could be used outside the feature platform, and there were requirements to consider this. Therefore, creating a separate service was more suitable for Karrot’s situation.
- Additionally, some source data didn’t exist in AWS, which could have resulted in significant additional costs if everything was handled within the feature platform.
Although it’s a separate service from the feature platform, the following is a brief introduction to how the feature platform uses data through stream processing:
- Various content embedding cases – We perform stream processing using models, and use various contents (articles, images, and so on) as input values to pre-trained models to create embeddings. These embeddings are stored in the feature platform and used as features during recommendation to improve recommendation quality.
- Rich feature generation cases – Some of the processed data is further processed using large language models (LLMs) for use as features. One example is predicting which category a specific second-hand product belongs to and using this prediction value as a feature.
Batch ingestion
Batch ingestion is responsible for processing and storing large amounts of data into features in batches. This is divided into a cron job that runs periodically and a backfill job that loads large amounts of data one time.
For this purpose, AWS Batch based on AWS Fargate is used. AWS Batch jobs running on Fargate are provisioned independently from the other environments, enabling safe large-scale processing. For example, even if more than 1,000 servers or 10,000 vCPUs are used for backfilling large amounts of data, they are operated separately from the other services and can be operated efficiently with a usage-based billing method.
When adding new features, batch loading of past data or periodic loading of large amounts of data is one of the core functions of the feature platform. The main requirements considered in the design are as follows:
- It must be able to process large amounts of data.
- It must be able to start at the time desired by the user and finish the work within an appropriate time.
- It must have low operating costs. It should be a managed service if possible, and it’s better if there is less additional work or specific domain knowledge for operation. Also, it should reuse existing service code as much as possible.
- Complex operations for features or the configuration of Directed Acyclic Graphs (DAGs) are not necessarily required.
There were several options to choose from, such as Apache Airflow, but AWS Batch was chosen to avoid over-engineering considering the operating cost according to the current requirements.
The following diagram illustrates the architecture of the batch ingestion pipeline.
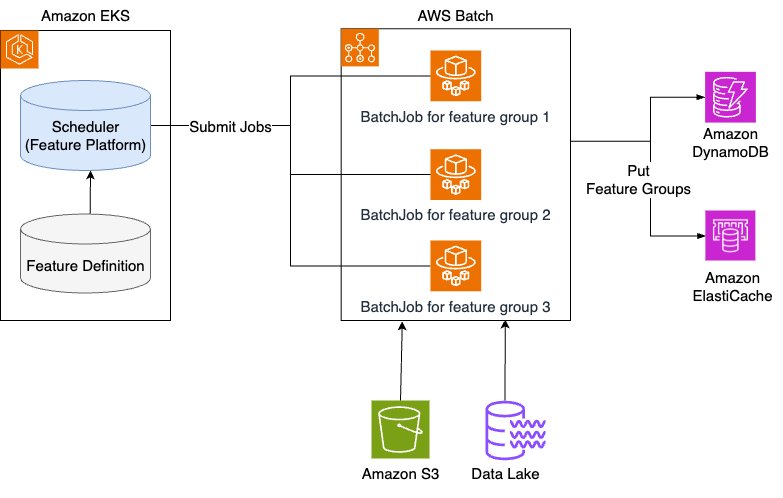
The key components are as follows:
- Scheduler – It extracts the targets that need to perform the batch jobs according to the specifications such as
FeatureGroupSpecandIngestionSpecwritten by the user on the feature platform, and registers the corresponding job specifications to an AWS Batch job (submit job). - AWS Batch – The jobs submitted by the scheduler are executed using the preconfigured job queue and computing environment. In the case of AWS Batch, you can configure a Fargate environment separately from the other production services, so that even if you provision large-scale resources and perform tasks, you can perform tasks stably without affecting the other production services.
Future improvements for batch ingestion
The current configuration works well and reliably, but there are some areas for improvement:
- No DAG support – The initial feature platform performed relatively simple tasks, such as parsing batch data sources, converting them to the feature schema, and storing them. However, as the platform became more advanced, more complex operations became necessary, and therefore support for DAG configurations that can process features by sequentially performing various dependent jobs became necessary.
- Manual configuration for parallel processing – Currently, when processing large-scale data in parallel, the worker must manually estimate the number of jobs to be processed in parallel and provide it in the specification, and the scheduler performs a submit job in parallel based on this. This method is based purely on experience, and in order for the system to become more advanced, the system must be able to automatically abstract and optimize the appropriate level of parallel processing.
- Limited AWS Batch monitoring usability – AWS Batch monitoring has some limitations, such as jobs don’t transition from Runnable to Running state, a lack of appropriate notification systems for such cases, and the inability to directly check failed jobs through URL parameters when receiving alerts. These aspects should be improved from an operational convenience perspective.
Results
As of February 2025, Karrot has addressed the major problems mentioned in the early stages of feature platform development:
- Decoupling recommendation logic from flea market server – The recommendation system now uses the feature platform across more than 10 different recommendation spaces and services.
- Securing scalability of features used in recommendation logic – With more than 1,000 high-quality and rich features acquired from various services such as flea market, advertisements, local jobs, and real estate, we are contributing to the advancement of recommendation logic and making it straightforward for all Karrot engineers to explore and add features.
- Maintaining the reliability of feature data sources – Through the feature platform, we are providing reliable data using a consistent schema and ingestion pipeline.
Karrot engineers are continuously improving the user experience by advancing recommendations through high-quality features through the feature platform. This has contributed to increasing click-through rates by 30% and conversion rates by 70% compared to before by recommending articles that users might be interested in.
This was possible because the AWS services used in the feature platform were firmly supporting it. Amazon DynamoDB has amazing scalability in all aspects of read, write, and storage, so it was possible to handle dynamically changing workloads without incurring separate operating costs. Amazon ElastiCache showed highly reliable service stability, so we could use it with confidence. In addition, it was straightforward and stable to scale up, down, in, and out, so it was possible to reduce the operational burden. It also seamlessly integrated with the ecosystem of Redis OSS, so we could use open source ecosystems such as Redis Exporter. Amazon MSK also supports reliable operation and seamless integration with the Apache Kafka ecosystem, making the development and operation of the feature platform effortless.
Furthermore, working with AWS enables cost-efficient operations based on their various support and expertise. Recently, we had an over-provisioning problem with our ElastiCache cluster. Right-sizing our ElastiCache cluster with various experts (including Solutions Architects) made it possible to optimize ElastiCache costs by nearly 40%. Such technical human resources from AWS have been invaluable in operating the feature platform using AWS products.
Conclusion
In this series, we discussed how Karrot built a feature platform on AWS. We believe that by combining AWS services and our experience, you can develop and operate a feature store without difficulty by modifying it to suit your company’s requirements. Try out this implementation and let us know your thoughts in the comments.
About the authors
Author: Hyeonho Kim