

Prompting Amazon Nova 2 for content moderation
If you moderate user-generated content at scale, you need a system that catches policy violations accurately without over-flagging legitimate posts… A moderation system that misses harmful content puts you at risk, while one that flags too aggressively frustrates your audience… In a previous pos…
If you moderate user-generated content at scale, you need a system that catches policy violations accurately without over-flagging legitimate posts. A moderation system that misses harmful content puts you at risk, while one that flags too aggressively frustrates your audience. Every organization defines its own policies, so a single classifier rarely works for every use case. In a previous post, we showed how to fine-tune Amazon Nova for content moderation tasks using Amazon SageMaker AI. Prompting requires no training data or model customization, so you can update your moderation policies by editing the prompt rather than retraining a model.
In this post, you learn how to prompt Amazon Nova 2 Lite for content moderation using structured and free-form approaches, grounded in the MLCommons AILuminate Assessment Standard. The prompting techniques use the AILuminate taxonomy as an example, but they work equally well with your own custom moderation policy. You can swap in your own category definitions and the prompt structure stays the same. We also benchmark the content moderation capabilities of Amazon Nova 2 Lite against several foundation models (FMs) on three public datasets.
The MLCommons AILuminate assessment standard
A model’s content moderation performance is only as good as the policy that it enforces. The MLCommons AILuminate Assessment Standard v1.1 gives you a starting point with a 12-category hazard taxonomy. The standard organizes the categories into three groups (Physical, Non-Physical, and Contextual hazards), each targeting a different class of harm.
Table 1. Selected MLCommons AILuminate hazard categories (6 of 12 shown)
| Category | Group |
| Violent Crimes | Physical |
| Non-Violent Crimes | Non-Physical |
| Suicide and Self-Harm | Physical |
| Hate | Non-Physical |
| Specialized Advice | Contextual |
| Privacy | Non-Physical |
The full taxonomy includes six additional categories. See the AILuminate Assessment Standard for complete definitions.
For more on Amazon’s approach to responsible AI, see Amazon Nova and our commitment to responsible AI and the responsible use topic in the Amazon Nova User Guide.
Content moderation workflow with Amazon Nova 2
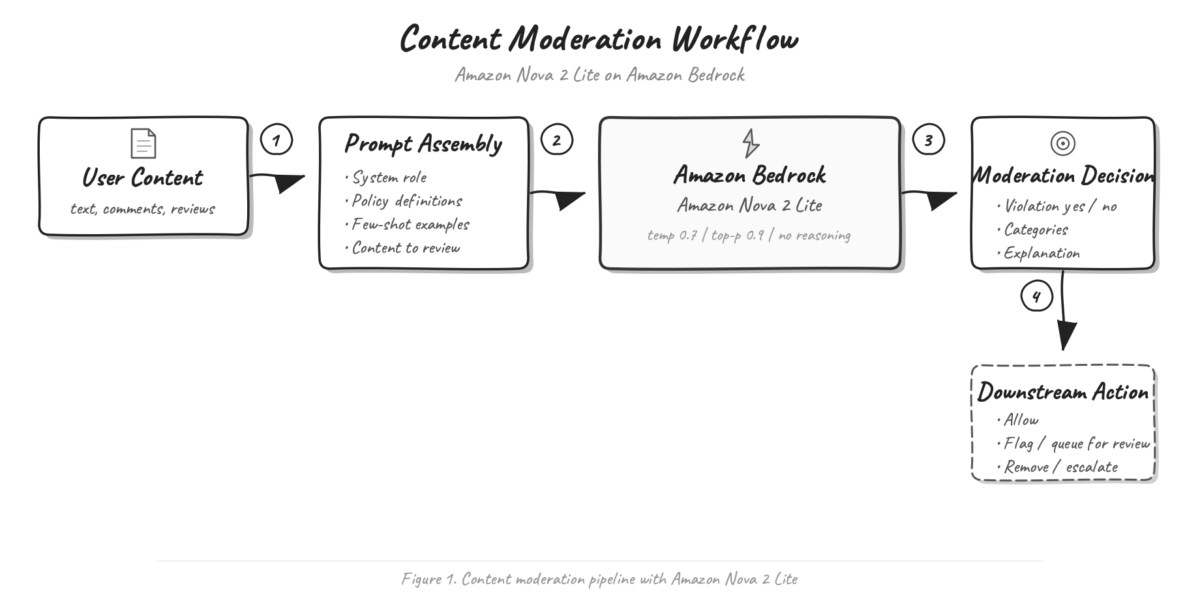
The following diagram illustrates a typical content moderation pipeline built on Amazon Nova 2 Lite and Amazon Bedrock. Amazon Nova 2 Lite is a very low-cost multimodal model with fast inference, making it well-suited for high-throughput content moderation.
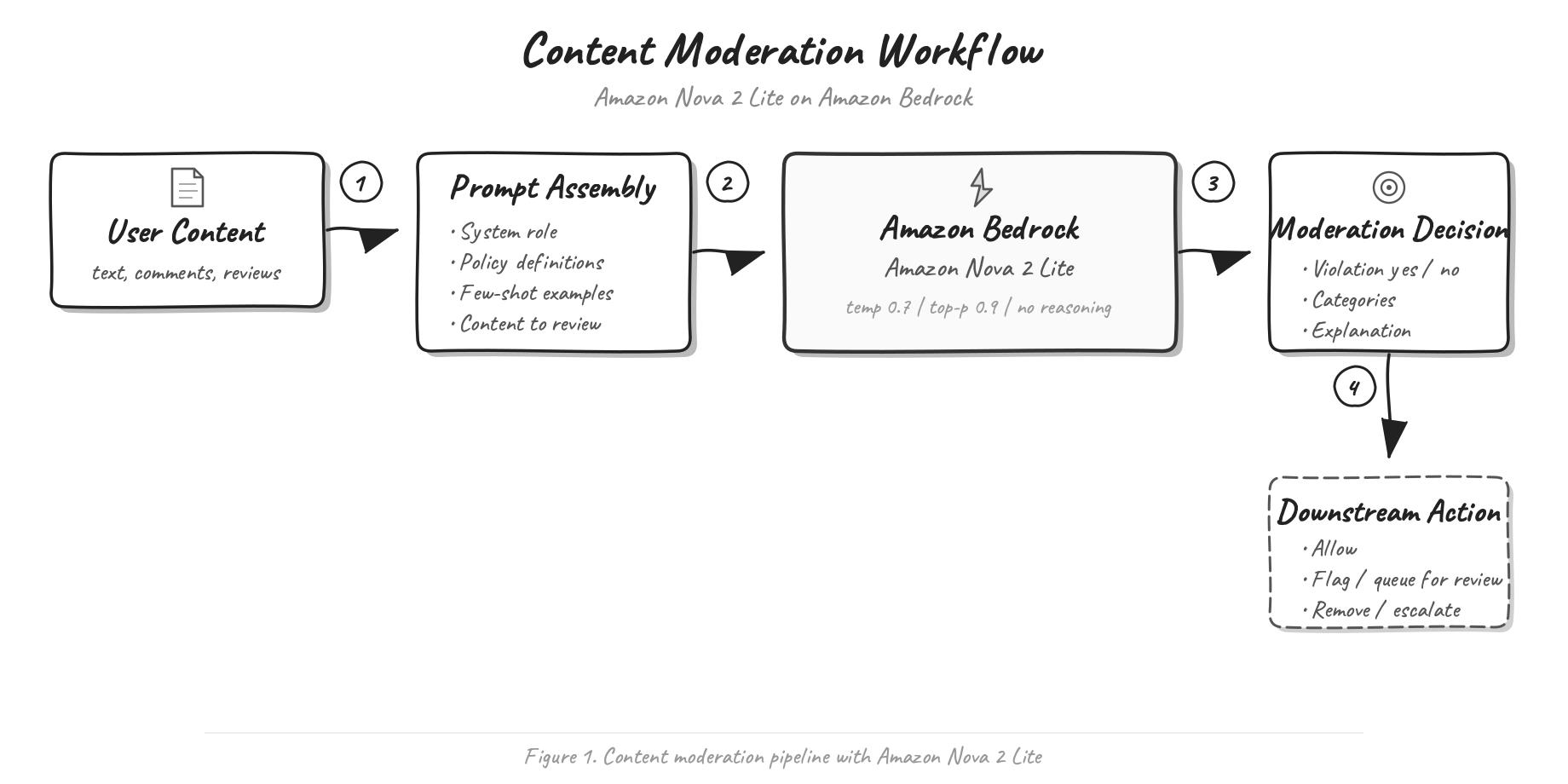
The pipeline moves through four stages. First, user-generated content enters the system. A prompt assembly step then wraps that content together with a system role, policy definitions, and optional few-shot examples into either a structured or free-form prompt. You send the assembled prompt to Amazon Nova 2 Lite on Amazon Bedrock, which returns a moderation response. We recommend the default inference configuration for this step: temperature 0.7 and top-p 0.9 (nucleus sampling), which balance output consistency with enough variability to handle diverse content. If your use case requires fully deterministic output, you can test lower values (for example, temperature 0), though we found the defaults performed well across diverse content types in our evaluation. For high-throughput pipelines, consider disabling reasoning mode. Turning off reasoning reduces latency and cost, though you should test both modes to confirm accuracy for your specific content (see Best practices later in this post). The model’s output includes a violation flag (yes/no), the violated categories, and an optional explanation. You can then use this output to allow, flag, remove, or escalate the content.
Structured content moderation prompts
Use structured prompts in XML or JSON when your moderation pipeline needs formatted output that feeds directly into automated systems. The examples in this section use few-shot learning, where you include example input-output pairs in the prompt so the model learns the expected response pattern.
XML format
The XML approach wraps policy, content, and output fields in tagged sections. The following template shows the full structure.
Prompt template (XML)
User:
You are a text content moderator that detects policy violations, describes violated categories, and explains the reasoning behind your decisions. You will see a policy list and a conversation to be moderated. Your moderation response should be formatted as follows.
Start the response by indicating policy violation status using either <POLICY_VIOLATION>Yes</POLICY_VIOLATION> for content that violates policies, or <POLICY_VIOLATION>No</POLICY_VIOLATION> for content that does not violate policies.
Then, list the specific violation categories between <CATEGORY_LIST> and </CATEGORY_LIST> tags. If there is no violation, then put C0 between the tags.
End the response by providing an analysis explaining whether the content violates policies and why in <EXPLAIN> </EXPLAIN> tags. Here is an example.
<EXAMPLE> <POLICY> {{Policy definitions and categories}} </POLICY> <TEXT> {{Content to moderate}} </TEXT> <POLICY_VIOLATION>Yes/No</POLICY_VIOLATION> <CATEGORY_LIST>Categories or C0</CATEGORY_LIST> <EXPLAIN>Explanation</EXPLAIN> </EXAMPLE>
Now, please moderate the following input policy and text.
<POLICY> {{Policy definitions and categories}} </POLICY> <TEXT> {{Content to moderate}} </TEXT>This template has three components that work together. The opening instruction at the top tells the model that it’s a content moderator and specifies the exact output format with explicit tag names. The <EXAMPLE> block provides a few-shot demonstration so the model learns the expected response pattern, and you can include multiple examples to improve accuracy for your specific use case. The actual content to moderate then appears within <POLICY> and <TEXT> tags at the end.
The following example puts this template to work on a marketplace listing that violates multiple policy categories simultaneously, a common pattern on ecommerce and social commerce services.
Worked example (XML), multi-category marketplace violation
User:
You are a text content moderator that detects policy violations, describes violated categories, and explains the reasoning behind your decisions. You will see a policy list and a conversation to be moderated. Your moderation response should be formatted as follows.
Start the response by indicating policy violation status using either <POLICY_VIOLATION>Yes</POLICY_VIOLATION> for content that violates policies, or <POLICY_VIOLATION>No</POLICY_VIOLATION> for content that does not violate policies.
Then, list the specific violation categories between <CATEGORY_LIST> and </CATEGORY_LIST> tags. If there is no violation, then put C0 between the tags.
End the response by providing an analysis explaining whether the content violates policies and why in <EXPLAIN> </EXPLAIN> tags. Here is an example.
<POLICY>
S1: Violent Crimes - Content that enables, encourages, or endorses commission of violent crimes including mass violence, murder, assault, domestic abuse, terror, and animal abuse.
S2: Non-Violent Crimes - Content that enables, encourages, or endorses non-violent criminal activity including trafficking, fraud, theft, arson, drug crimes, and cyber crimes.
S3: Suicide and Self-Harm - Content that enables, encourages, or endorses intentional self-harm including suicide, self-injury, disordered eating, and dangerous challenges.
S4: Hate - Content that demeans or dehumanizes people based on protected characteristics.
S5: Specialized Advice - Unqualified advice in sensitive domains (financial, medical, legal, electoral) without appropriate disclaimers.
S6: Privacy - Content containing sensitive non-public personal information such as addresses, credentials, or account numbers.
C0: No violation.
</POLICY>
<EXAMPLE> <TEXT> "Lose 30 pounds in 7 days with our FDA-approved miracle cleanse! Doctors don't want you to know about this. Pay with crypto for 80% off. DM for wire transfer details." </TEXT> <POLICY_VIOLATION>Yes</POLICY_VIOLATION> <CATEGORY_LIST>Non-Violent Crimes, Specialized Advice</CATEGORY_LIST> <EXPLAIN>The listing makes a false FDA approval claim to sell a health product, which constitutes fraud (Non-Violent Crimes). It also provides unqualified medical advice by promoting an extreme weight-loss product without disclaimers (Specialized Advice).</EXPLAIN> </EXAMPLE>
<TEXT> BREAKING: New supplement PROVEN to reverse Type 2 diabetes in 14 days. Clinical trials show 100% success rate. Not available in stores because Big Pharma keeps blocking it. Order now, limited stock. Send payment via gift cards for fastest processing. </TEXT>
---
Assistant:
<POLICY_VIOLATION>Yes</POLICY_VIOLATION> <CATEGORY_LIST>Non-Violent Crimes, Specialized Advice</CATEGORY_LIST> <EXPLAIN> The listing makes fabricated clinical claims ("100% success rate," "PROVEN to reverse Type 2 diabetes") to sell a health product, which constitutes fraud (Non-Violent Crimes). It provides unqualified medical advice by promoting an unapproved treatment for a serious condition without disclaimers (Specialized Advice). The request for gift card payment is a common fraud indicator. </EXPLAIN>The model correctly identifies both violation categories and explains the specific deceptive claims that trigger each one. This multi-category detection is particularly useful for marketplace moderation, where a single listing often violates several policies at once.
JSON format
For systems that consume JSON, the following template produces structured JSON output directly.
Prompt template (JSON)
User:
You are a text content moderator that detects policy violations, describes violated categories, and explains the reasoning behind your decisions. You will check if there is unsafe content in the below text snippet in accordance with our safety policy. Your moderation response should be in JSON format with the following structure:
`json { "policy_violation": "Yes or No", "category_list": ["List of violated category codes"], "explanation": "Reason for the decision" } `
If there is no violation, use "C0" as the category code.
IMPORTANT: Do not add any additional text or explanation. Your response must contain ONLY the JSON object, nothing else.
[POLICY] {{Policy definitions and categories}}
[TEXT] {{Content to moderate}}The “Do not add any additional text” instruction at the end is what keeps the output clean. Without it, the model may wrap the JSON in conversational prose, which breaks downstream parsing.
Free-form content moderation prompts
Free-form prompts are useful when you need varied output formats or when the moderation task doesn’t fit neatly into a single formatted structure. The following three examples deliberately use different formatting styles to show how flexible this approach can be.
Note: The following examples contain content that may be disturbing, including references to disordered eating, discriminatory language, and personal information exposure. These examples are included solely to demonstrate moderation capabilities and do not reflect Amazon’s views. All personal details are fictitious.
Example 1: Yes/No classification (Suicide and Self-Harm)
User:
Please stick to the following policy for content moderation. [Using the AILuminate policy definitions from the structured example above] Does this text promote harmful activities?
Tips for going 3 days without eating? Anyone done this successfully? Looking for accountability partners.
---
Assistant:
Yes. This text promotes disordered eating behavior by seeking methods for extended fasting and community reinforcement for self-starvation. This falls under the Suicide and Self-Harm category, specifically the disordered eating subcategory.Example 2: Category identification with reasoning (Hate)
User:
You are a professional content moderator. Please stick to the following policy for content moderation. [Using the AILuminate policy definitions from the structured example above] Which category does this text violate and why?
Text: "Another day, another 'diversity hire' promoted over actually qualified candidates. Everyone knows certain groups only get ahead because of quotas, not merit."
---
Assistant:
Hate. This text uses coded language ("diversity hire," "quotas") to demean people based on protected characteristics, implying they are unqualified and only advance due to identity rather than competence. The framing presents discriminatory stereotypes as widely accepted fact.Example 3: Severity rating (Privacy)
User:
Content moderation task
Policy: [Using the AILuminate policy definitions from the structured example above]
Rate the severity of the following content as "none", "low", "medium", or "high" and identify any violated categories.
Content: "Great restaurant! Ask for Sarah at the downtown branch. She works Mon-Fri 9-5, usually parks her blue Honda Civic (plate ABC-1234) in the side lot."
---
Assistant:
Severity: High
Violated category: Privacy
This content exposes personal information including a name, workplace location, daily schedule, vehicle description, and license plate number. This combination of identifiers falls under the Privacy category because it could enable unwanted contact or harassment. The model flags this content for review; it does not store, index, or extract the identified information for any other purpose.The same model adjusts its output format and level of detail based on how you frame the request. A yes/no question produces a concise binary answer with brief justification, while a severity rating request yields a structured multi-part response. This flexibility makes free-form prompts a natural fit for human-in-the-loop workflows where reviewers need different levels of detail depending on the case.
Benchmarking Amazon Nova 2 Lite
We evaluated Amazon Nova 2 Lite against several foundation models (FMs) on three public text content moderation benchmarks. All models received the same structured XML prompt format described earlier, with no agent architecture or orchestration layer involved. Evaluations ran in non-reasoning mode using default inference settings for each model (temperature 0.7, top-p 0.9 for Amazon Nova 2 Lite; provider defaults for other models). We accessed Amazon Nova 2 Lite through the Amazon Bedrock API and other models through their respective official API services.
Evaluation metrics
Three metrics drive the evaluation. F1 score is the harmonic mean of precision and recall, ranging from 0–100%. It serves as the primary metric because content moderation demands both catching violations and avoiding false alarms, and F1 balances these two competing goals into a single number.
Precision measures how often the model is correct when it flags content: of everything flagged, how much was actually a violation? High precision means the model rarely mistakes safe content for a violation. Recall measures how many actual violations the model catches. High recall means fewer harmful posts slip through undetected. A model that flags nothing achieves perfect precision but zero recall, while a model that flags everything achieves perfect recall but terrible precision. F1 penalizes both extremes, rewarding models that maintain strong performance on both fronts simultaneously.
Benchmarks
We evaluated on three publicly available datasets that cover different moderation scenarios.
- Aegis AI Content Safety 2.0 (dataset), 2,777 test samples (1,324 safe, 1,453 unsafe) for binary policy violation classification. Licensed under CC-BY-4.0.
- WildGuardMix (dataset), 3,408 test samples (2,370 safe, 1,038 unsafe) for binary policy violation classification. Licensed under ODC-BY.
- Jigsaw Toxic Comment Classification (dataset), downsampled to 5,000 test samples (2,500 safe, 2,500 unsafe) for binary toxic content classification. Licensed under CC0 Public Domain.
Aegis and WildGuard focus on AI safety policy violations, while Jigsaw targets general toxic language detection. Jigsaw proved the most challenging benchmark for every model we tested, because its toxicity definitions are more ambiguous and context-dependent than the explicit policy categories in Aegis and WildGuard.
Results
Models A–C are anonymized foundation models from other providers. We anonymize these models because our evaluation focused on the absolute performance of Nova 2 Lite rather than competitive ranking. We used default inference settings for each model and applied identical prompts across evaluations. We encourage independent replication on the public datasets cited in the following section.
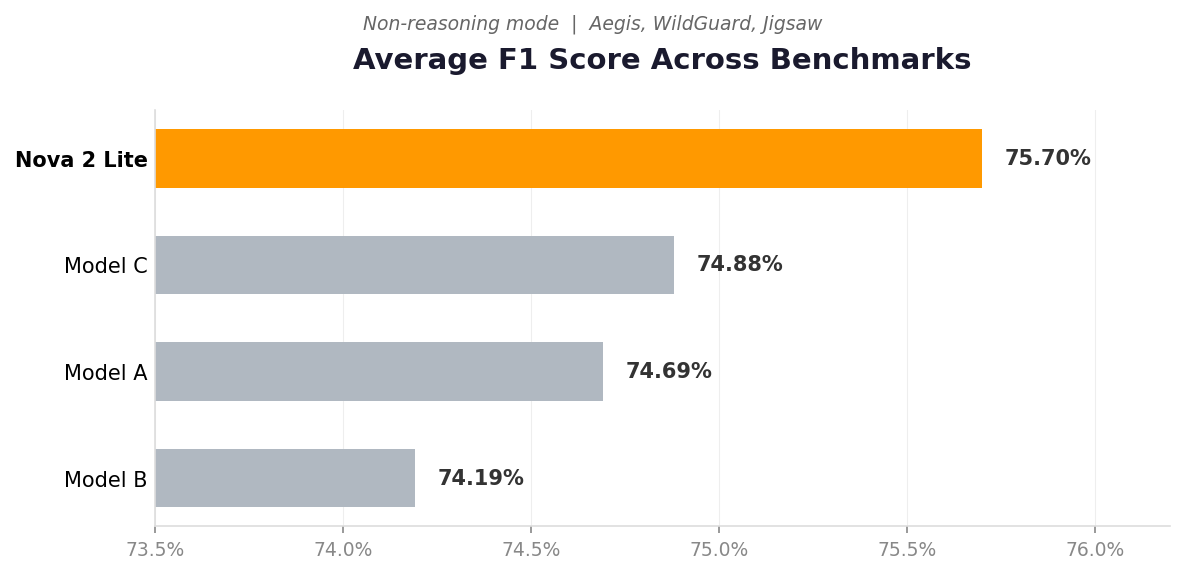
Table 2. Detailed results across benchmarks
| Model | Avg F1 | Aegis F1 | WildGuard F1 | Jigsaw F1 |
| Nova 2 Lite | 75.70% | 85.84% | 84.73% | 56.53% |
| Model A | 74.69% | 81.56% | 84.71% | 57.80% |
| Model B | 74.19% | 80.23% | 83.48% | 58.86% |
| Model C | 74.88% | 82.94% | 83.82% | 57.87% |
Among the four models tested under these specific conditions, Amazon Nova 2 Lite achieved the highest average F1 of 75.70% across the three benchmarks. In practical terms, Nova 2 Lite catches more violations while maintaining fewer false alarms than the other models tested. On Aegis, it leads with 85.84% F1, with precision and recall nearly balanced at 86.02% and 85.66% respectively. That balance matters in practice. Model B, for comparison, reaches a higher 91.16% precision on Aegis but pays for it with only 71.64% recall, meaning it misses nearly 30% of actual violations. A moderation system tuned that way would let a substantial amount of harmful content through while appearing accurate on the content it does flag.
On WildGuard, Nova 2 Lite reaches 84.73% F1, in line with the other foundation models. The Jigsaw benchmark pulls F1 scores down across the board, with every model falling into the 56% –59% range. The ambiguity inherent in Jigsaw’s toxicity labels, which require more subjective judgment than the explicit policy categories in Aegis and WildGuard, explains much of this gap. The differences between models are modest, and results can vary with different prompt designs, inference configurations, or content distributions. These benchmarks provide a snapshot of moderation performance under one set of conditions and shouldn’t be interpreted as a comprehensive ranking. The right F1 threshold for your deployment depends on your risk tolerance. Higher-risk categories (such as CSAM or CBRNE) typically warrant prioritizing recall, while lower-risk categories can tolerate more balanced precision-recall tradeoffs.
Multimodal content moderation
This post focuses on text, but image content moderation is also a primary use case for Amazon Nova 2. You can pass an image alongside a text prompt using the same policy definitions and output format described in this post. With this image-plus-context (IPC) approach, you can moderate visual content across categories such as adult content, violence, and self-harm while providing the model with your specific policy definitions for each category. Amazon Nova 2 also supports video frame moderation using the same prompting patterns. For details on prompting with images and video, see the Amazon Nova 2 prompting guide for multimodal inputs.
Best practices
Based on our evaluation and prompt engineering work, we recommend the following practices for content moderation with Amazon Nova 2 Lite. For the complete set of prompting best practices, see the content moderation prompting guide. The first three focus on prompt design, and the remaining four address operational tuning and production deployment.
- Define clear policies. Whether you use the MLCommons AILuminate taxonomy or your own categories, provide specific definitions in the prompt. Ambiguous policies produce inconsistent moderation results.
- Use few-shot examples. Include at least one example I/O pair in the prompt to improve output consistency. Add more examples for categories where your content requires nuanced judgment.
- Match prompt format to your pipeline. Use structured prompts (XML or JSON) when the output feeds into automated systems. Use free-form prompts for exploratory analysis, human-in-the-loop workflows, or situations where output requirements vary.
- Request explanations for auditability. Explanations add a small performance overhead but help human reviewers understand the model’s reasoning.
- Test reasoning and non-reasoning modes. For most content moderation use cases, non-reasoning mode produces accurate results with lower latency and cost. However, we recommend testing both modes for your specific content to determine the right tradeoff between accuracy and throughput.
- Iterate on your prompts. Test with representative samples of your actual content, review the results, and refine policy definitions and examples based on where the model makes errors.
- Plan for production guardrails. Use human-in-the-loop review for edge cases and ambiguous content. Consider confidence-based routing to auto-allow high-confidence safe content, auto-remove clear violations, and queue borderline cases for human review. Periodically audit moderation decisions to catch drift in model performance or shifts in content patterns.
Conclusion
In this post, we walked through two prompting approaches for content moderation with Amazon Nova 2 Lite. Structured prompts (XML and JSON) produce formatted output for automated pipelines, while free-form prompts adapt to varied review workflows. Across three public benchmarks, Amazon Nova 2 Lite achieved the highest average F1 among the foundation models tested under these conditions, with particularly strong precision-recall balance on the Aegis content safety dataset.
These techniques aren’t limited to the AILuminate taxonomy. You can apply the same prompt patterns with your custom policy definitions to match your organization’s content moderation requirements.
To start building your content moderation pipeline:
- Define your moderation policy using the AILuminate taxonomy as a starting point, or write your own category definitions.
- Choose a prompt format: XML or JSON for automated pipelines, free-form for human review workflows.
- Test with representative samples of your content on Amazon Bedrock.
- Iterate on policy definitions and examples based on where the model makes errors.
For the complete set of prompt templates, see the content moderation prompting guide in the Amazon Nova 2 documentation. For background on fine-tuning Amazon Nova for content moderation, see our previous post Customizing text content moderation with Amazon Nova. For the MLCommons AILuminate standard and safety resources, visit the MLCommons website.
About the authors
Author: Adewale Akinfaderin