

Amazon Aurora PostgreSQL Limitless Database is now generally available
Today, we are announcing the general availability of Amazon Aurora PostgreSQL Limitless Database, a new serverless horizontal scaling (sharding) capability of Amazon Aurora… When we previewed Aurora PostgreSQL Limitless Database at AWS re:Invent 2023, I explained that it uses a two-layer architec…
Today, we are announcing the general availability of Amazon Aurora PostgreSQL Limitless Database, a new serverless horizontal scaling (sharding) capability of Amazon Aurora. With Aurora PostgreSQL Limitless Database, you can scale beyond the existing Aurora limits for write throughput and storage by distributing a database workload over multiple Aurora writer instances while maintaining the ability to use it as a single database.
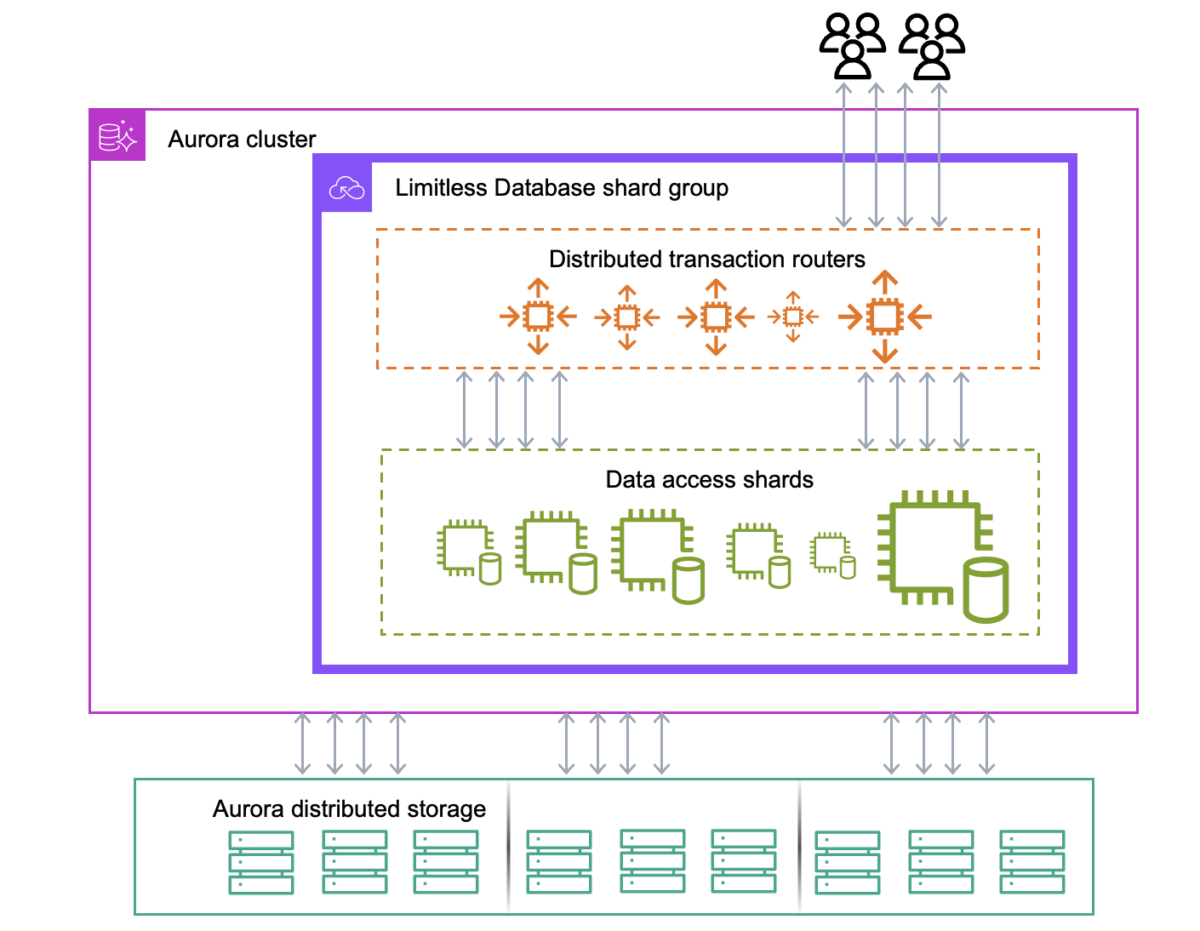
When we previewed Aurora PostgreSQL Limitless Database at AWS re:Invent 2023, I explained that it uses a two-layer architecture consisting of multiple database nodes in a DB shard group – either routers or shards to scale based on the workload.

- Routers – Nodes that accept SQL connections from clients, send SQL commands to shards, maintain system-wide consistency, and return results to clients.
- Shards – Nodes that store a subset of tables and full copies of data, which accept queries from routers.
There will be three types of tables that contain your data: sharded, reference, and standard.
- Sharded tables – These tables are distributed across multiple shards. Data is split among the shards based on the values of designated columns in the table, called shard keys. They are useful for scaling the largest, most I/O-intensive tables in your application.
- Reference tables – These tables copy data in full on every shard so that join queries can work faster by eliminating unnecessary data movement. They are commonly used for infrequently modified reference data, such as product catalogs and zip codes.
- Standard tables – These tables are like regular Aurora PostgreSQL tables. Standard tables are all placed together on a single shard so join queries can work faster by eliminating unnecessary data movement. You can create sharded and reference tables from standard tables.
Once you have created the DB shard group and your sharded and reference tables, you can load massive amounts of data into Aurora PostgreSQL Limitless Database and query data in those tables using standard PostgreSQL queries. To learn more, visit Limitless Database architecture in the Amazon Aurora User Guide.
Getting started with Aurora PostgreSQL Limitless Database
You can get started in the AWS Management Console and AWS Command Line Interface (AWS CLI) to create a new DB cluster that uses Aurora PostgreSQL Limitless Database, add a DB shard group to the cluster, and query your data.
1. Create an Aurora PostgreSQL Limitless Database Cluster
Open the Amazon Relational Database Service (Amazon RDS) console and choose Create database. For Engine options, choose Aurora (PostgreSQL Compatible) and Aurora PostgreSQL with Limitless Database (Compatible with PostgreSQL 16.4).

For Aurora PostgreSQL Limitless Database, enter a name for your DB shard group and values for minimum and maximum capacity measured by Aurora Capacity Units (ACUs) across all routers and shards. The initial number of routers and shards in a DB shard group is determined by this maximum capacity. Aurora PostgreSQL Limitless Database scales a node up to a higher capacity when its current utilization is too low to handle the load. It scales the node down to a lower capacity when its current capacity is higher than needed.

For DB shard group deployment, choose whether to create standbys for the DB shard group: no compute redundancy, one compute standby in a different Availability Zone, or two compute standbys in two different Availability Zones.
You can set the remaining DB settings to what you prefer and choose Create database. After the DB shard group is created, it is displayed on the Databases page.

You can connect, reboot, or delete a DB shard group, or you can change the capacity, split a shard, or add a router in the DB shard group. To learn more, visit Working with DB shard groups in the Amazon Aurora User Guide.
2. Create Aurora PostgreSQL Limitless Database tables
As shared previously, Aurora PostgreSQL Limitless Database has three table types: sharded, reference, and standard. You can convert standard tables to sharded or reference tables to distribute or replicate existing standard tables or create new sharded and reference tables.
You can use variables to create sharded and reference tables by setting the table creation mode. The tables that you create will use this mode until you set a different mode. The following examples show how to use these variables to create sharded and reference tables.
For example, create a sharded table named items with a shard key composed of the item_id and item_cat columns.
SET rds_aurora.limitless_create_table_mode='sharded';
SET rds_aurora.limitless_create_table_shard_key='{"item_id", "item_cat"}';
CREATE TABLE items(item_id int, item_cat varchar, val int, item text);Now, create a sharded table named item_description with a shard key composed of the item_id and item_cat columns and collocate it with the items table.
SET rds_aurora.limitless_create_table_collocate_with='items';
CREATE TABLE item_description(item_id int, item_cat varchar, color_id int, ...);You can also create a reference table named colors.
SET rds_aurora.limitless_create_table_mode='reference';
CREATE TABLE colors(color_id int primary key, color varchar);You can find information about Limitless Database tables by using the rds_aurora.limitless_tables view, which contains information about tables and their types.
postgres_limitless=> SELECT * FROM rds_aurora.limitless_tables;
table_gid | local_oid | schema_name | table_name | table_status | table_type | distribution_key
-----------+-----------+-------------+-------------+--------------+-------------+------------------
1 | 18797 | public | items | active | sharded | HASH (item_id, item_cat)
2 | 18641 | public | colors | active | reference |
(2 rows)You can convert standard tables into sharded or reference tables. During the conversion, data is moved from the standard table to the distributed table, then the source standard table is deleted. To learn more, visit Converting standard tables to limitless tables in the Amazon Aurora User Guide.
3. Query Aurora PostgreSQL Limitless Database tables
Aurora PostgreSQL Limitless Database is compatible with PostgreSQL syntax for queries. You can query your Limitless Database using psql or any other connection utility that works with PostgreSQL. Before querying tables, you can load data into Aurora Limitless Database tables by using the COPY command or by using the data loading utility.
To run queries, connect to the cluster endpoint, as shown in Connecting to your Aurora Limitless Database DB cluster. All PostgreSQL SELECT queries are performed on the router to which the client sends the query and shards where the data is located.
To achieve a high degree of parallel processing, Aurora PostgreSQL Limitless Database utilizes two querying methods: single-shard queries and distributed queries, which determines whether your query is single-shard or distributed and processes the query accordingly.
- Single-shard query – A query where all the data needed for the query is on one shard. The entire operation can be performed on one shard, including any result set generated. When the query planner on the router encounters a query like this, the planner sends the entire SQL query to the corresponding shard.
- Distributed query – A query run on a router and more than one shard. The query is received by one of the routers. The router creates and manages the distributed transaction, which is sent to the participating shards. The shards create a local transaction with the context provided by the router, and the query is run.
For examples of single-shard queries, you use the following parameters to configure the output from the EXPLAIN command.
postgres_limitless=> SET rds_aurora.limitless_explain_options = shard_plans, single_shard_optimization;
SET
postgres_limitless=> EXPLAIN SELECT * FROM items WHERE item_id = 25;
QUERY PLAN
--------------------------------------------------------------
Foreign Scan (cost=100.00..101.00 rows=100 width=0)
Remote Plans from Shard postgres_s4:
Index Scan using items_ts00287_id_idx on items_ts00287 items_fs00003 (cost=0.14..8.16 rows=1 width=15)
Index Cond: (id = 25)
Single Shard Optimized
(5 rows) To learn more about the EXPLAIN command, see EXPLAIN in the PostgreSQL documentation.
For examples of distributed queries, you can insert new items named Book and Pen into the items table.
postgres_limitless=> INSERT INTO items(item_name)VALUES ('Book'),('Pen')This makes a distributed transaction on two shards. When the query runs, the router sets a snapshot time and passes the statement to the shards that own Book and Pen. The router coordinates an atomic commit across both shards, and returns the result to the client.
You can use distributed query tracing, a tool to trace and correlate queries in PostgreSQL logs across Aurora PostgreSQL Limitless Database. To learn more, visit Querying Limitless Database in the Amazon Aurora User Guide.
Some SQL commands aren’t supported. For more information, see Aurora Limitless Database reference in the Amazon Aurora User Guide.
Things to know
Here are a couple of things that you should know about this feature:
- Compute – You can only have one DB shard group per DB cluster and set the maximum capacity of a DB shard group to 16–6144 ACUs. Contact us if you need more than 6144 ACUs. The initial number of routers and shards is determined by the maximum capacity that you set when you create a DB shard group. The number of routers and shards doesn’t change when you modify the maximum capacity of a DB shard group. To learn more, see the table of the number of routers and shards in the Amazon Aurora User Guide.
- Storage – Aurora PostgreSQL Limitless Database only supports the Amazon Aurora I/O-Optimized DB cluster storage configuration. Each shard has a maximum capacity of 128 TiB. Reference tables have a size limit of 32 TiB for the entire DB shard group. To reclaim storage space by cleaning up your data, you can use the vacuuming utility in PostgreSQL.
- Monitoring – You can use Amazon CloudWatch, Amazon CloudWatch Logs, or Performance Insights to monitor Aurora PostgreSQL Limitless Database. There are also new statistics functions and views and wait events for Aurora PostgreSQL Limitless Database that you can use for monitoring and diagnostics.
Now available
Amazon Aurora PostgreSQL Limitless Database is available today with PostgreSQL 16.4 compatibility in the AWS US East (N. Virginia), US East (Ohio), US West (Oregon), Asia Pacific (Hong Kong), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Europe (Frankfurt), Europe (Ireland), and Europe (Stockholm) Regions.
Give Aurora PostgreSQL Limitless Database a try in the Amazon RDS console. For more information, visit the Amazon Aurora User Guide and send feedback to AWS re:Post for Amazon Aurora or through your usual AWS support contacts.
— Channy
Author: Channy Yun (윤석찬)