

Amazon RDS for MySQL zero-ETL integration with Amazon Redshift, now generally available, enables near real-time analytics
They provide a fully managed, no-code, near real-time solution for making petabytes of transactional data available in Amazon Redshift within seconds of data being written into Amazon Relational Database Service (Amazon RDS) for MySQL… Last year, we announced the general availability of zero-ETL …
Zero-ETL integrations help unify your data across applications and data sources for holistic insights and breaking data silos. They provide a fully managed, no-code, near real-time solution for making petabytes of transactional data available in Amazon Redshift within seconds of data being written into Amazon Relational Database Service (Amazon RDS) for MySQL. This eliminates the need to create your own ETL jobs simplifying data ingestion, reducing your operational overhead and potentially lowering your overall data processing costs. Last year, we announced the general availability of zero-ETL integration with Amazon Redshift for Amazon Aurora MySQL-Compatible Edition as well as the availability in preview of Aurora PostgreSQL-Compatible Edition, Amazon DynamoDB, and RDS for MySQL.
I am happy to announce that Amazon RDS for MySQL zero-ETL with Amazon Redshift is now generally available. This release also includes new features such as data filtering, support for multiple integrations, and the ability to configure zero-ETL integrations in your AWS CloudFormation template.
In this post, I’ll show how you can get started with data filtering and consolidating your data across multiple databases and data warehouses. For a step-by-step walkthrough on how to set up zero-ETL integrations, see this blog post for a description of how to set one up for Aurora MySQL-Compatible, which offers a very similar experience.
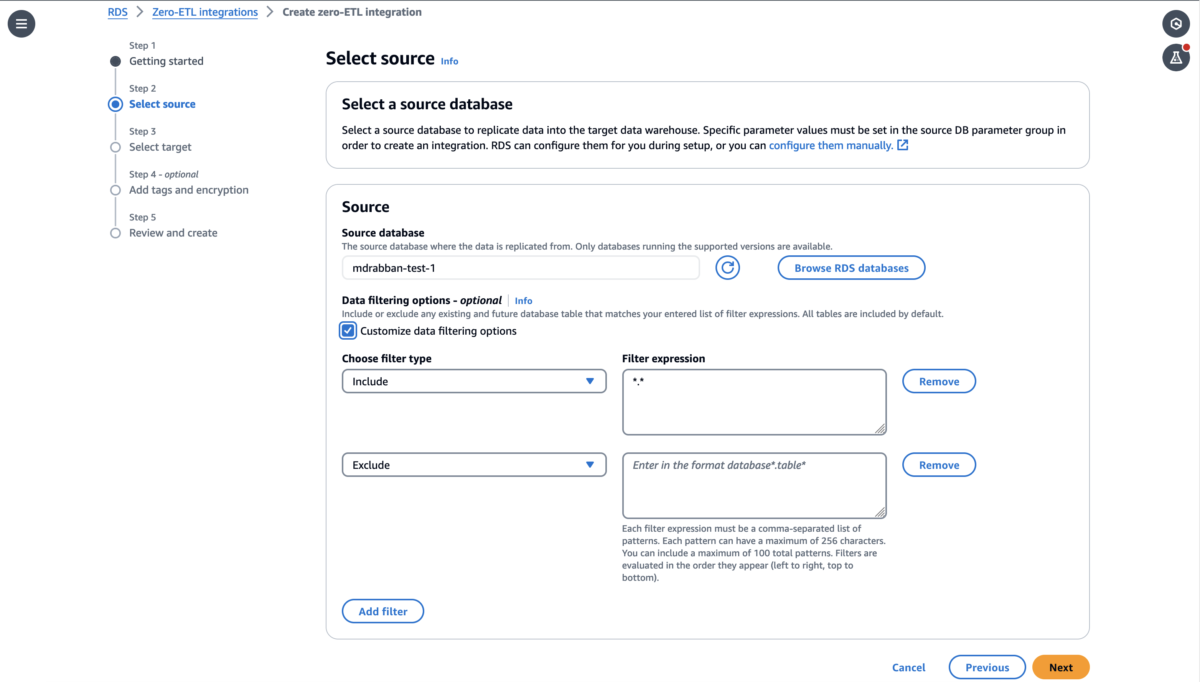
Data filtering
Most companies, no matter the size, can benefit from adding filtering to their ETL jobs. A typical use case is to reduce data processing and storage costs by selecting only the subset of data needed to replicate from their production databases. Another is to exclude personally identifiable information (PII) from a report’s dataset. For example, a business in healthcare might want to exclude sensitive patient information when replicating data to build aggregate reports analyzing recent patient cases. Similarly, an e-commerce store may want to make customer spending patterns available to their marketing department, but exclude any identifying information. Conversely, there are certain cases when you might not want to use filtering, such as when making data available to fraud detection teams that need all the data in near real time to make inferences. These are just a few examples, so I encourage you to experiment and discover different use cases that might apply to your organization.
There are two ways to enable filtering in your zero-ETL integrations: when you first create the integration or by modifying an existing integration. Either way, you will find this option on the “Source” step of the zero-ETL creation wizard.

You apply filters by entering filter expressions that can be used to either include or exclude databases or tables from the dataset in the format of database*.table*. You can add multiple expressions and they will be evaluated in order from left to right.
If you’re modifying an existing integration, the new filtering rules will apply from that point in time on after you confirm your changes and Amazon Redshift will drop tables that are no longer part of the filter.
If you want to dive deeper, I recommend you read this blog post, which goes in depth into how you can set up data filters for Amazon Aurora zero-ETL integrations since the steps and concepts are very similar.
Create multiple zero-ETL integrations from a single database
You are now also able to configure up integrations from a single RDS for MySQL database to up to 5 Amazon Redshift data warehouses. The only requirement is that you must wait for the first integration to finish setting up successfully before adding others.
This allows you to share transactional data with different teams while providing them ownership over their own data warehouses for their specific use cases. For example, you can also use this in conjunction with data filtering to fan out different sets of data to development, staging, and production Amazon Redshift clusters from the same Amazon RDS production database.
Another interesting scenario where this could be really useful is consolidation of Amazon Redshift clusters by using zero-ETL to replicate to different warehouses. You could also use Amazon Redshift materialized views to explore your data, power your Amazon Quicksight dashboards, share data, train jobs in Amazon SageMaker, and more.
Conclusion
RDS for MySQL zero-ETL integrations with Amazon Redshift allows you to replicate data for near real-time analytics without needing to build and manage complex data pipelines. It is generally available today with the ability to add filter expressions to include or exclude databases and tables from the replicated data sets. You can now also set up multiple integrations from the same source RDS for MySQL database to different Amazon Redshift warehouses or create integrations from different sources to consolidate data into one data warehouse.
This zero-ETL integration is available for RDS for MySQL versions 8.0.32 and later, Amazon Redshift Serverless, and Amazon Redshift RA3 instance types in supported AWS Regions.
In addition to using the AWS Management Console, you can also set up a zero-ETL integration via the AWS Command Line Interface (AWS CLI) and by using an AWS SDK such as boto3, the official AWS SDK for Python.
See the documentation to learn more about working with zero-ETL integrations.
Author: Matheus Guimaraes