

Amazon SageMaker adds new inference capabilities to help reduce foundation model deployment costs and latency
With the new inference capabilities, you can deploy one or more foundation models (FMs) on the same SageMaker endpoint and control how many accelerators and how much memory is reserved for each FM… This helps to improve resource utilization, reduce model deployment costs on average by 50 percent,…
Today, we are announcing new Amazon SageMaker inference capabilities that can help you optimize deployment costs and reduce latency. With the new inference capabilities, you can deploy one or more foundation models (FMs) on the same SageMaker endpoint and control how many accelerators and how much memory is reserved for each FM. This helps to improve resource utilization, reduce model deployment costs on average by 50 percent, and lets you scale endpoints together with your use cases.
For each FM, you can define separate scaling policies to adapt to model usage patterns while further optimizing infrastructure costs. In addition, SageMaker actively monitors the instances that are processing inference requests and intelligently routes requests based on which instances are available, helping to achieve on average 20 percent lower inference latency.
Key components
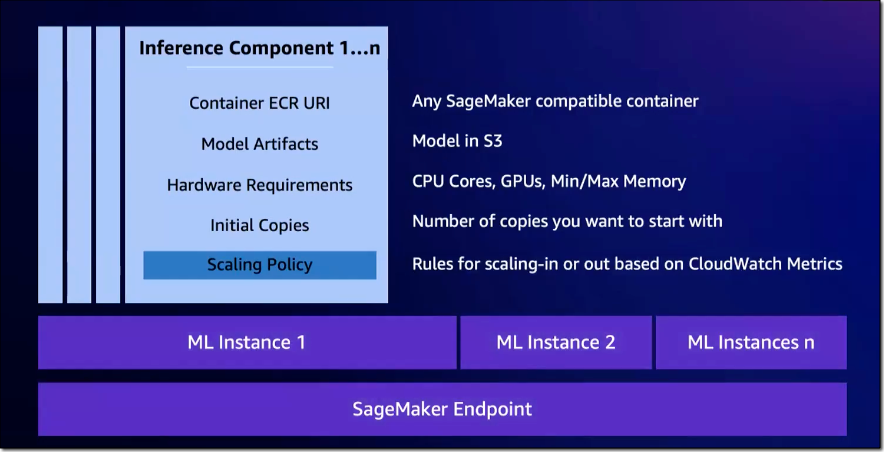
The new inference capabilities build upon SageMaker real-time inference endpoints. As before, you create the SageMaker endpoint with an endpoint configuration that defines the instance type and initial instance count for the endpoint. The model is configured in a new construct, an inference component. Here, you specify the number of accelerators and amount of memory you want to allocate to each copy of a model, together with the model artifacts, container image, and number of model copies to deploy.

Let me show you how this works.
New inference capabilities in action
You can start using the new inference capabilities from SageMaker Studio, the SageMaker Python SDK, and the AWS SDKs and AWS Command Line Interface (AWS CLI). They are also supported by AWS CloudFormation.
For this demo, I use the AWS SDK for Python (Boto3) to deploy a copy of the Dolly v2 7B model and a copy of the FLAN-T5 XXL model from the Hugging Face model hub on a SageMaker real-time endpoint using the new inference capabilities.
Create a SageMaker endpoint configuration
import boto3
import sagemaker
role = sagemaker.get_execution_role()
sm_client = boto3.client(service_name="sagemaker")
sm_client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ExecutionRoleArn=role,
ProductionVariants=[{
"VariantName": "AllTraffic",
"InstanceType": "ml.g5.12xlarge",
"InitialInstanceCount": 1,
"RoutingConfig": {
"RoutingStrategy": "LEAST_OUTSTANDING_REQUESTS"
}
}]
)Create the SageMaker endpoint
sm_client.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name,
)Before you can create the inference component, you need to create a SageMaker-compatible model and specify a container image to use. For both models, I use the Hugging Face LLM Inference Container for Amazon SageMaker. These deep learning containers (DLCs) include the necessary components, libraries, and drivers to host large models on SageMaker.
Prepare the Dolly v2 model
from sagemaker.huggingface import get_huggingface_llm_image_uri
# Retrieve the container image URI
hf_inference_dlc = get_huggingface_llm_image_uri(
"huggingface",
version="0.9.3"
)
# Configure model container
dolly7b = {
'Image': hf_inference_dlc,
'Environment': {
'HF_MODEL_ID':'databricks/dolly-v2-7b',
'HF_TASK':'text-generation',
}
}
# Create SageMaker Model
sagemaker_client.create_model(
ModelName = "dolly-v2-7b",
ExecutionRoleArn = role,
Containers = [dolly7b]
)Prepare the FLAN-T5 XXL model
# Configure model container
flant5xxlmodel = {
'Image': hf_inference_dlc,
'Environment': {
'HF_MODEL_ID':'google/flan-t5-xxl',
'HF_TASK':'text-generation',
}
}
# Create SageMaker Model
sagemaker_client.create_model(
ModelName = "flan-t5-xxl",
ExecutionRoleArn = role,
Containers = [flant5xxlmodel]
)Now, you’re ready to create the inference component.
Create an inference component for each model
Specify an inference component for each model you want to deploy on the endpoint. Inference components let you specify the SageMaker-compatible model and the compute and memory resources you want to allocate. For CPU workloads, define the number of cores to allocate. For accelerator workloads, define the number of accelerators. RuntimeConfig defines the number of model copies you want to deploy.
# Inference compoonent for Dolly v2 7B
sm_client.create_inference_component(
InferenceComponentName="IC-dolly-v2-7b",
EndpointName=endpoint_name,
VariantName=variant_name,
Specification={
"ModelName": "dolly-v2-7b",
"ComputeResourceRequirements": {
"NumberOfAcceleratorDevicesRequired": 2,
"NumberOfCpuCoresRequired": 2,
"MinMemoryRequiredInMb": 1024
}
},
RuntimeConfig={"CopyCount": 1},
)
# Inference component for FLAN-T5 XXL
sm_client.create_inference_component(
InferenceComponentName="IC-flan-t5-xxl",
EndpointName=endpoint_name,
VariantName=variant_name,
Specification={
"ModelName": "flan-t5-xxl",
"ComputeResourceRequirements": {
"NumberOfAcceleratorDevicesRequired": 2,
"NumberOfCpuCoresRequired": 1,
"MinMemoryRequiredInMb": 1024
}
},
RuntimeConfig={"CopyCount": 1},
)Once the inference components have successfully deployed, you can invoke the models.
Run inference
To invoke a model on the endpoint, specify the corresponding inference component.
import json
sm_runtime_client = boto3.client(service_name="sagemaker-runtime")
payload = {"inputs": "Why is California a great place to live?"}
response_dolly = sm_runtime_client.invoke_endpoint(
EndpointName=endpoint_name,
InferenceComponentName = "IC-dolly-v2-7b",
ContentType="application/json",
Accept="application/json",
Body=json.dumps(payload),
)
response_flant5 = sm_runtime_client.invoke_endpoint(
EndpointName=endpoint_name,
InferenceComponentName = "IC-flan-t5-xxl",
ContentType="application/json",
Accept="application/json",
Body=json.dumps(payload),
)
result_dolly = json.loads(response_dolly['Body'].read().decode())
result_flant5 = json.loads(response_flant5['Body'].read().decode())
Next, you can define separate scaling policies for each model by registering the scaling target and applying the scaling policy to the inference component. Check out the SageMaker Developer Guide for detailed instructions.
The new inference capabilities provide per-model CloudWatch metrics and CloudWatch Logs and can be used with any SageMaker-compatible container image across SageMaker CPU- and GPU-based compute instances. Given support by the container image, you can also use response streaming.
Now available
The new Amazon SageMaker inference capabilities are available today in AWS Regions US East (Ohio, N. Virginia), US West (Oregon), Asia Pacific (Jakarta, Mumbai, Seoul, Singapore, Sydney, Tokyo), Canada (Central), Europe (Frankfurt, Ireland, London, Stockholm), Middle East (UAE), and South America (São Paulo). For pricing details, visit Amazon SageMaker Pricing. To learn more, visit Amazon SageMaker.
Get started
Log in to the AWS Management Console and deploy your FMs using the new SageMaker inference capabilities today!
— Antje
Author: Antje Barth