

Amazon SageMaker Inference now supports G6e instances
xlarge—to host powerful open-source foundation models such as Llama 3… The key highlights for G6e instances include: Twice the GPU memory compared to G5 and G6 instances, enabling deployment of large language models in FP16 up to: 14B parameter model on a single GPU node (G6e…xlar…
As the demand for generative AI continues to grow, developers and enterprises seek more flexible, cost-effective, and powerful accelerators to meet their needs. Today, we are thrilled to announce the availability of G6e instances powered by NVIDIA’s L40S Tensor Core GPUs on Amazon SageMaker. You will have the option to provision nodes with 1, 4, and 8 L40S GPU instances, with each GPU providing 48 GB of high bandwidth memory (HBM). This launch provides organizations with the capability to use a single-node GPU instance—G6e.xlarge—to host powerful open-source foundation models such as Llama 3.2 11 B Vision, Llama 2 13 B, and Qwen 2.5 14B, offering organizations a cost-effective and high-performing option. This makes it a perfect choice for those looking to optimize costs while maintaining high performance for inference workloads.
The key highlights for G6e instances include:
- Twice the GPU memory compared to G5 and G6 instances, enabling deployment of large language models in FP16 up to:
- 14B parameter model on a single GPU node (G6e.xlarge)
- 72B parameter model on a 4 GPU node (G6e.12xlarge)
- 90B parameter model on an 8 GPU node (G6e.48xlarge)
- Up to 400 Gbps of networking throughput
- Up to 384 GB GPU Memory
Use cases
G6e instances are ideal for fine-tuning and deploying open large language models (LLMs). Our benchmarks show that G6e provides higher performance and is more cost-effective compared to G5 instances, making them an ideal fit for use in low-latency, real time use cases such as:
- Chatbots and conversational AI
- Text generation and summarization
- Image generation and vision models
We have also observed that G6e performs well for inference at high concurrency and with longer context lengths. We have provided complete benchmarks in the following section.
Performance
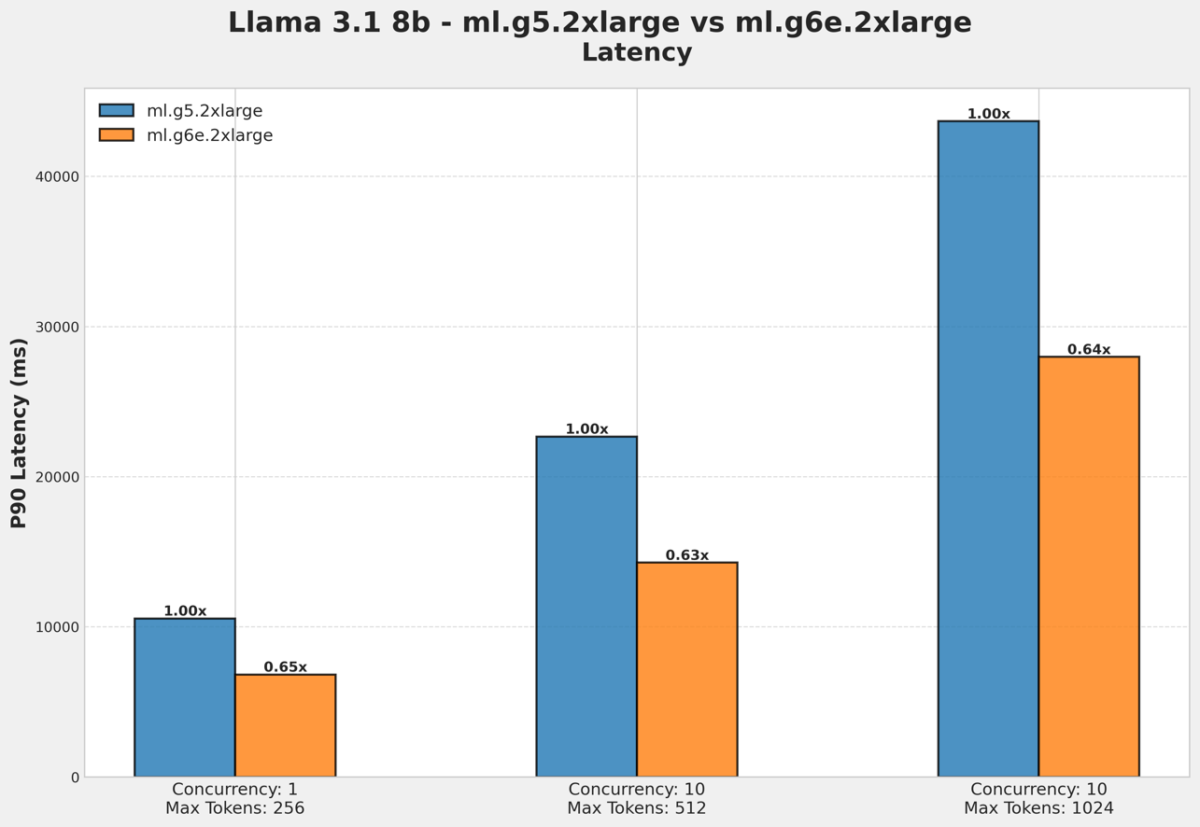
In the following two figures, we see that for long context length of 512 and 1024, G6e.2xlarge provides up to 37% better latency and 60% better throughput compared to G5.2xlarge for a Llama 3.1 8B model.


In the following two figures, we see that G5.2xlarge throws a CUDA out of memory (OOM) when deploying the LLama 3.2 11B Vision model, whereas G6e.2xlarge provides great performance.


In the following two figures, we compare G5.48xlarge (8 GPU node) with the G6e.12xlarge (4 GPU) node, which costs 35% less and is more performant. For higher concurrency, we see that G6e.12xlarge provides 60% lower latency and 2.5 times higher throughput.


In the below figure, we are comparing cost per 1000 tokens when deploying a Llama 3.1 70b which further highlights the cost/performance benefits of using G6e instances compared to G5.

Deployment walkthrough
Prerequisites
To try out this solution using SageMaker, you’ll need the following prerequisites:
- An AWS account that will contain all of your AWS resources.
- An AWS Identity and Access Management (IAM) role to access SageMaker. To learn more about how IAM works with SageMaker, see Identity and Access Management for Amazon SageMaker.
- Access to Amazon SageMaker Studio or a SageMaker notebook instance, or an interactive development environment (IDE) such as PyCharm or Visual Studio Code. We recommend using SageMaker Studio for straightforward deployment and inference.
- 1 instance of ml.g6e.xlarge (or larger) for SageMaker hosting.
Deployment
You can clone the repository and use the notebook provided here.
Clean up
To prevent incurring unnecessary charges, it’s recommended to clean up the deployed resources when you’re done using them. You can remove the deployed model with the following code:
predictor.delete_predictor()
Conclusion
G6e instances on SageMaker unlock the ability to deploy a wide variety of open source models cost-effectively. With superior memory capacity, enhanced performance, and cost-effectiveness, these instances represent a compelling solution for organizations looking to deploy and scale their AI applications. The ability to handle larger models, support longer context lengths, and maintain high throughput makes G6e instances particularly valuable for modern AI applications. Try the code to deploy with G6e.
About the Authors
 Vivek Gangasani is a Senior GenAI Specialist Solutions Architect at AWS. He helps emerging GenAI companies build innovative solutions using AWS services and accelerated compute. Currently, he is focused on developing strategies for fine-tuning and optimizing the inference performance of Large Language Models. In his free time, Vivek enjoys hiking, watching movies and trying different cuisines.
Vivek Gangasani is a Senior GenAI Specialist Solutions Architect at AWS. He helps emerging GenAI companies build innovative solutions using AWS services and accelerated compute. Currently, he is focused on developing strategies for fine-tuning and optimizing the inference performance of Large Language Models. In his free time, Vivek enjoys hiking, watching movies and trying different cuisines.
 Alan Tan is a Senior Product Manager with SageMaker, leading efforts on large model inference. He’s passionate about applying machine learning to the area of analytics. Outside of work, he enjoys the outdoors.
Alan Tan is a Senior Product Manager with SageMaker, leading efforts on large model inference. He’s passionate about applying machine learning to the area of analytics. Outside of work, he enjoys the outdoors.
 Pavan Kumar Madduri is an Associate Solutions Architect at Amazon Web Services. He has a strong interest in designing innovative solutions in Generative AI and is passionate about helping customers harness the power of the cloud. He earned his MS in Information Technology from Arizona State University. Outside of work, he enjoys swimming and watching movies.
Pavan Kumar Madduri is an Associate Solutions Architect at Amazon Web Services. He has a strong interest in designing innovative solutions in Generative AI and is passionate about helping customers harness the power of the cloud. He earned his MS in Information Technology from Arizona State University. Outside of work, he enjoys swimming and watching movies.
 Michael Nguyen is a Senior Startup Solutions Architect at AWS, specializing in leveraging AI/ML to drive innovation and develop business solutions on AWS. Michael holds 12 AWS certifications and has a BS/MS in Electrical/Computer Engineering and an MBA from Penn State University, Binghamton University, and the University of Delaware.
Michael Nguyen is a Senior Startup Solutions Architect at AWS, specializing in leveraging AI/ML to drive innovation and develop business solutions on AWS. Michael holds 12 AWS certifications and has a BS/MS in Electrical/Computer Engineering and an MBA from Penn State University, Binghamton University, and the University of Delaware.
Author: Vivek Gangasani