

Amazon SageMaker launches the updated inference optimization toolkit for generative AI
Today, Amazon SageMaker is excited to announce updates to the inference optimization toolkit, providing new functionality and enhancements to help you optimize generative AI models even faster…1 models – The toolkit now supports speculative decoding for the latest Meta Llama 3…1 70B and 405B (…
Today, Amazon SageMaker is excited to announce updates to the inference optimization toolkit, providing new functionality and enhancements to help you optimize generative AI models even faster. These updates build on the capabilities introduced in the original launch of the inference optimization toolkit (to learn more, see Achieve up to ~2x higher throughput while reducing costs by ~50% for generative AI inference on Amazon SageMaker with the new inference optimization toolkit – Part 1).
The following are the key additions to the inference optimization toolkit:
- Speculative decoding support for Meta Llama 3.1 models – The toolkit now supports speculative decoding for the latest Meta Llama 3.1 70B and 405B (FP8) text models, allowing you to accelerate inference process.
- Support for FP8 quantization – The toolkit has been updated to enable FP8 (8-bit floating point) quantization, helping you further optimize model size and inference latency for GPUs. FP8 offers several advantages over FP32 (32-bit floating point) for deep learning model inference, including reduced memory usage, faster computation, lower power consumption, and broader applicability because FP8 quantization can be applied to key model components like the KV cache, attention, and MLP linear layers.
- Compilation support for TensorRT-LLM – You can now use the toolkit’s compilation capabilities to integrate your generative AI models with NVIDIA’s TensorRT-LLM, delivering enhanced performance by optimizing the model with ahead-of-time compilation. You reduce the model’s deployment time and auto scaling latency because the model weights don’t require just-in-time compilation when the model deploys to a new instance.
These updates build on the toolkit’s existing capabilities, allowing you to reduce the time it takes to optimize generative AI models from months to hours, and achieve best-in-class performance for your use case. Simply choose from the available optimization techniques, apply them to your models, validate the improvements, and deploy the models in just a few clicks through SageMaker.
In this post, we discuss these new features of the toolkit in more detail.
Speculative decoding
Speculative decoding is an inference technique that aims to speed up the decoding process of large language models (LLMs) for latency-critical applications, without compromising the quality of the generated text. The key idea is to use a smaller, less powerful, but faster language model called the draft model to generate candidate tokens. These candidate tokens are then validated by the larger, more powerful, but slower target model. At each iteration, the draft model generates multiple candidate tokens. The target model verifies the tokens, and if it finds a particular token unacceptable, it rejects it and regenerates that token itself. This allows the larger target model to focus on verification, which is faster than auto-regressive token generation. The smaller draft model can quickly generate all the tokens and send them in batches to the target model for parallel evaluation, significantly speeding up the final response generation.
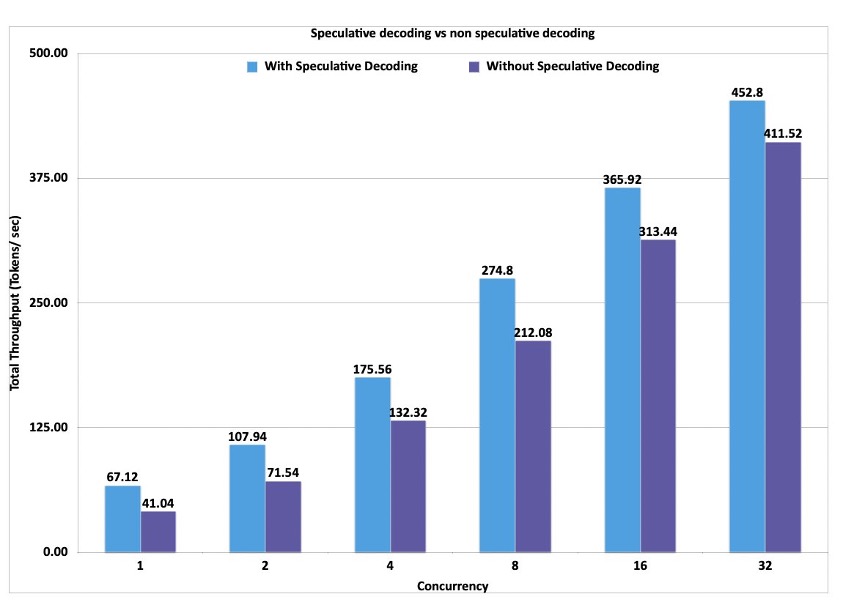
With the updated SageMaker inference toolkit, you get out-of-the-box support for speculative decoding that has been tested for performance at scale on various popular open source LLMs. The toolkit provides a pre-built draft model, eliminating the need to invest time and resources in building your own draft model from scratch. Alternatively, you can also use your own custom draft model, providing flexibility to accommodate your specific requirements. To showcase the benefits of speculative decoding, let’s look at the throughput (tokens per second) for a Meta Llama 3.1 70B Instruct model deployed on an ml.p4d.24xlarge instance using the Meta Llama 3.2 1B Instruct draft model.

Given the increase in throughput that is realized with speculative decoding, we can also see the blended price difference when using speculative decoding vs. when not using speculative decoding. Here we have calculated the blended price as a 3:1 ratio of input to output tokens. The blended price is defined as follows:
- Total throughput (tokens per second) = NumberOfOutputTokensPerRequest / (ClientLatency / 1,000) x concurrency
- Blended price ($ per 1 million tokens) = (1−(discount rate)) × (instance per hour price) ÷ ((total token throughput per second) × 60 × 60 ÷ 10^6)) ÷ 4
- Discount rate assuming a 26% Savings Plan

Quantization
Quantization is one of the most popular model compression methods to accelerate model inference. From a technical perspective, quantization has several benefits:
- It reduces model size, which makes it suitable for deploying using fewer GPUs with lower total device memory available.
- It reduces memory bandwidth pressure by using fewer-bit data types.
- If offers increased space for the KV cache. This enables larger batch sizes and sequence lengths.
- It significantly speeds up matrix multiplication (GEMM) operations on the NVIDIA architecture, for example, up to twofold for FP8 compared to the FP16/BF16 data type in microbenchmarks.
With this launch, the SageMaker inference optimization toolkit now supports FP8 and SmoothQuant (TensorRT-LLM only) quantization. SmoothQuant is a post-training quantization (PTQ) technique for LLMs that reduces memory and speeds up inference without sacrificing accuracy. It migrates quantization difficulty from activations to weights, which are easier to quantize. It does this by introducing a hyperparameter to calculate a per-channel scale that balances the quantization difficulty of activations and weights.
The current generation of instances like p5 and g6 provide support for FP8 using specialized tensor cores. FP8 represents float point numbers in 8 bits instead of the usual 16. At the time of writing, vLLM and TRT-LLM support quantizing the KV cache, attention, and linear layers for text-only LLMs. This reduces memory footprint, increases throughput, and lowers latency. Whereas both weights and activations can be quantized for p5 and g6 instances (W8A8), only weights can be quantized for p4d and g5 instances (W8A16). Though FP8 quantization has minimal impact on accuracy, you should always evaluate the quantized model on your data and for your use case. You can evaluate the quantized model through Amazon SageMaker Clarify. For more details, see Understand options for evaluating large language models with SageMaker Clarify.
The following graph compares the throughput of a FP8 quantized Meta Llama 3.1 70B Instruct model against a non-quantized Meta Llama 3.1 70B Instruct model on an ml.p4d.24xlarge instance.

The quantized model has a smaller memory footprint and it can be deployed to a smaller (and cheaper) instance type. In this post, we have deployed the quantized model on g5.12xlarge.
The following graph shows the price difference per million tokens between the FP8-quantized model deployed on g5.12xlarge and the non-quantized version deployed on p4d.24xlarge.

Our analysis shows a clear price-performance edge for the FP8 quantized model over the non-quantized approach. However, quantization has an impact on model accuracy, so we strongly testing the quantized version of the model on your datasets.
The following is the SageMaker Python SDK code snippet for quantization. You just need to provide the quantization_config attribute in the optimize() function:
Refer to the following code example to learn more about how to enable FP8 quantization and speculative decoding using the optimization toolkit for a pre-trained Amazon SageMaker JumpStart model. If you want to deploy a fine-tuned model with SageMaker JumpStart using speculative decoding, refer to the following notebook.
Compilation
Compilation optimizes the model to extract the best available performance on the chosen hardware type, without any loss in accuracy. For compilation, the SageMaker inference optimization toolkit provides efficient loading and caching of optimized models to reduce model loading and auto scaling time by up to 40–60 % for Meta Llama 3 8B and 70B.
Model compilation enables running LLMs on accelerated hardware, such as GPUs, while simultaneously optimizing the model’s computational graph for optimal performance on the target hardware. When using the Large Model Inference (LMI) Deep Learning Container (DLC) with the TensorRT-LLM framework, the compiler is invoked from within the framework and creates compiled artifacts. These compiled artifacts are unique for a combination of input shapes, precision of the model, tensor parallel degree, and other framework- or compiler-level configurations. Although the compilation process avoids overhead during inference and enables optimized inference, it can take a lot of time.
To avoid re-compiling every time a model is deployed onto a GPU with the TensorRT-LLM framework, SageMaker introduces the following features:
- A cache of pre-compiled artifacts – This includes popular models like Meta Llama 3.1. When using an optimized model with the compilation config, SageMaker automatically uses these cached artifacts when the configurations match.
- Ahead-of-time compilation – The inference optimization toolkit enables you to compile your models with the desired configurations before deploying them on SageMaker.
The following graph illustrates the improvement in model loading time when using pre-compiled artifacts with the SageMaker LMI DLC. The models were compiled with a sequence length of 4096 and a batch size of 16, with Meta Llama 3.1 8B deployed on a g5.12xlarge (tensor parallel degree = 4) and Meta Llama 3.1 70B Instruct on a p4d.24xlarge (tensor parallel degree = 8). As you can see on the graph, the bigger the model, the bigger the benefit of using a pre-compiled model (16% improvement for Meta Llama 3 8B and 43% improvement for Meta Llama 3 70B).

Compilation using the SageMaker Python SDK
For the SageMaker Python SDK, you can configure the compilation by changing the environment variables in the .optimize() function. For more details on compilation_config, refer to TensorRT-LLM ahead-of-time compilation of models tutorial.
Refer to the following notebook for more information on how to enable TensorRT-LLM compilation using the optimization toolkit for a pre-trained SageMaker JumpStart model.
Amazon SageMaker Studio UI experience
In this section, let’s walk through the Amazon SageMaker Studio UI experience to run an inference optimization job. In this case, we use the Meta Llama 3.1 70B Instruct model, and for the optimization option, we quantize the model using INT4-AWQ and then use the SageMaker JumpStart suggested draft model Meta Llama 3.2 1B Instruct for speculative decoding.
First, we search for the Meta Llama 3.1 70B Instruct model in the SageMaker JumpStart model hub and choose Optimize on the model card.

The Create inference optimization job page provides you options to choose the type of optimization. In this case, we choose to take advantage of the benefits of both INT4-AWQ quantization and speculative decoding.


For the draft model, you have a choice to use the SageMaker recommended draft model, choose one the SageMaker JumpStart models, or bring your own draft model.

For this scenario, we choose the SageMaker recommended Meta Llama 3.2 1B Instruct model as the draft model and start the optimization job.

When the optimization job is complete, you have an option to evaluate performance or deploy the model onto a SageMaker endpoint for inference.


Pricing
For compilation and quantization jobs, SageMaker will optimally choose the right instance type, so you don’t have to spend time and effort. You will be charged based on the optimization instance used. To learn more, see Amazon SageMaker pricing. For speculative decoding, there is no additional optimization cost involved; the SageMaker inference optimization toolkit will package the right container and parameters for the deployment on your behalf.
Conclusion
To get started with the inference optimization toolkit, refer to Achieve up to 2x higher throughput while reducing cost by up to 50% for GenAI inference on SageMaker with new inference optimization toolkit: user guide – Part 2. This post will walk you through how to use the inference optimization toolkit when using SageMaker inference with SageMaker JumpStart and the SageMaker Python SDK. You can use the inference optimization toolkit with supported models on SageMaker JumpStart. For the full list of supported models, refer to Inference optimization for Amazon SageMaker models.
About the Authors
 Marc Karp is an ML Architect with the Amazon SageMaker Service team. He focuses on helping customers design, deploy, and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.
Marc Karp is an ML Architect with the Amazon SageMaker Service team. He focuses on helping customers design, deploy, and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.
 Dmitry Soldatkin is a Senior AI/ML Solutions Architect at Amazon Web Services (AWS), helping customers design and build AI/ML solutions. Dmitry’s work covers a wide range of ML use cases, with a primary interest in Generative AI, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, utilities, and telecommunications. He has a passion for continuous innovation and using data to drive business outcomes.
Dmitry Soldatkin is a Senior AI/ML Solutions Architect at Amazon Web Services (AWS), helping customers design and build AI/ML solutions. Dmitry’s work covers a wide range of ML use cases, with a primary interest in Generative AI, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, utilities, and telecommunications. He has a passion for continuous innovation and using data to drive business outcomes.
 Raghu Ramesha is a Senior ML Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
Raghu Ramesha is a Senior ML Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
![]() Rishabh Ray Chaudhury is a Senior Product Manager with Amazon SageMaker, focusing on Machine Learning inference. He is passionate about innovating and building new experiences for Machine Learning customers on AWS to help scale their workloads. In his spare time, he enjoys traveling and cooking. You can find him on LinkedIn.
Rishabh Ray Chaudhury is a Senior Product Manager with Amazon SageMaker, focusing on Machine Learning inference. He is passionate about innovating and building new experiences for Machine Learning customers on AWS to help scale their workloads. In his spare time, he enjoys traveling and cooking. You can find him on LinkedIn.
 Lokeshwaran Ravi is a Senior Deep Learning Compiler Engineer at AWS, specializing in ML optimization, model acceleration, and AI security. He focuses on enhancing efficiency, reducing costs, and building secure ecosystems to democratize AI technologies, making cutting-edge ML accessible and impactful across industries.
Lokeshwaran Ravi is a Senior Deep Learning Compiler Engineer at AWS, specializing in ML optimization, model acceleration, and AI security. He focuses on enhancing efficiency, reducing costs, and building secure ecosystems to democratize AI technologies, making cutting-edge ML accessible and impactful across industries.
Author: Marc Karp