

Amazon SageMaker with TensorBoard: An overview of a hosted TensorBoard experience
Among the data scientist community, TensorBoard is a popular toolkit that allows data scientists to visualize and analyze various aspects of their machine learning (ML) models and training processes… TensorFlow and PyTorch projects both endorse and use TensorBoard in their official documentation …
Today, data scientists who are training deep learning models need to identify and remediate model training issues to meet accuracy targets for production deployment, and require a way to utilize standard tools for debugging model training. Among the data scientist community, TensorBoard is a popular toolkit that allows data scientists to visualize and analyze various aspects of their machine learning (ML) models and training processes. It provides a suite of tools for visualizing training metrics, examining model architectures, exploring embeddings, and more. TensorFlow and PyTorch projects both endorse and use TensorBoard in their official documentation and examples.
Amazon SageMaker with TensorBoard is a capability that brings the visualization tools of TensorBoard to SageMaker. Integrated with SageMaker training jobs and domains, it provides SageMaker domain users access to the TensorBoard data and helps domain users perform model debugging tasks using the SageMaker TensorBoard visualization plugins. When they create a SageMaker training job, domain users can use TensorBoard using the SageMaker Python SDK or Boto3 API. SageMaker with TensorBoard is supported by the SageMaker Data Manager plugin, with which domain users can access many training jobs in one place within the TensorBoard application.
In this post, we demonstrate how to set up a training job with TensorBoard in SageMaker using the SageMaker Python SDK, access SageMaker TensorBoard, explore training output data visualized in TensorBoard, and delete unused TensorBoard applications.
Solution overview
A typical training job for deep learning in SageMaker consists of two main steps: preparing a training script and configuring a SageMaker training job launcher. In this post, we walk you through the required changes to collect TensorBoard-compatible data from SageMaker training.
Prerequisites
To start using SageMaker with TensorBoard, you need to set up a SageMaker domain with an Amazon VPC under an AWS account. Domain user profiles for each individual user are required to access the TensorBoard on SageMaker, and the AWS Identity and Access Management (IAM) execution role needs a minimum set of permissions, including the following:
sagemaker:CreateAppsagemaker:DeleteAppsagemaker:DescribeTrainingJobsagemaker:Searchs3:GetObjects3:ListBucket
For more information on how to set up SageMaker Domain and user profiles, see Onboard to Amazon SageMaker Domain Using Quick setup and Add and Remove User Profiles.
Directory structure
When using Amazon SageMaker Studio, the directory structure can be organized as follows:
Here, script/train.py is your training script, and simple_tensorboard.ipynb launches the SageMaker training job.
Modify your training script
You can use any of the following tools to collect tensors and scalars: TensorBoardX, TensorFlow Summary Writer, PyTorch Summary Writer, or Amazon SageMaker Debugger, and specify the data output path as the log directory in the training container (log_dir). In this sample code, we use TensorFlow to train a simple, fully connected neural network for a classification task. For other options, refer to Prepare a training job with a TensorBoard output data configuration. In the train() function, we use the tensorflow.keras.callbacks.TensorBoard tool to collect tensors and scalars, specify /opt/ml/output/tensorboard as the log directory in the training container, and pass it to model training callbacks argument. See the following code:
Construct a SageMaker training launcher with a TensorBoard data configuration
Use sagemaker.debugger.TensorBoardOutputConfig while configuring a SageMaker framework estimator, which maps the Amazon Simple Storage Service (Amazon S3) bucket you specify for saving TensorBoard data with the local path in the training container (for example, /opt/ml/output/tensorboard). You can use a different container local output path. However, it must be consistent with the value of the LOG_DIR variable, as specified in the previous step, to have SageMaker successfully search the local path in the training container and save the TensorBoard data to the S3 output bucket.
Next, pass the object of the module to the tensorboard_output_config parameter of the estimator class. The following code snippet shows an example of preparing a TensorFlow estimator with the TensorBoard output configuration parameter.
The following is the boilerplate code:
The following code is for the training container:
The following code is the TensorBoard configuration:
Launch the training job with the following code:
Access TensorBoard on SageMaker
You can access TensorBoard with two methods: programmatically using the sagemaker.interactive_apps.tensorboard module that generates the URL or using the TensorBoard landing page on the SageMaker console. After you open TensorBoard, SageMaker runs the TensorBoard plugin and automatically finds and loads all training job output data in a TensorBoard-compatible file format from S3 buckets paired with training jobs during or after training.
The following code autogenerates the URL to the TensorBoard console landing page:
This returns the following message with a URL that opens the TensorBoard landing page.
For opening TensorBoard from the SageMaker console, please refer to How to access TensorBoard on SageMaker.
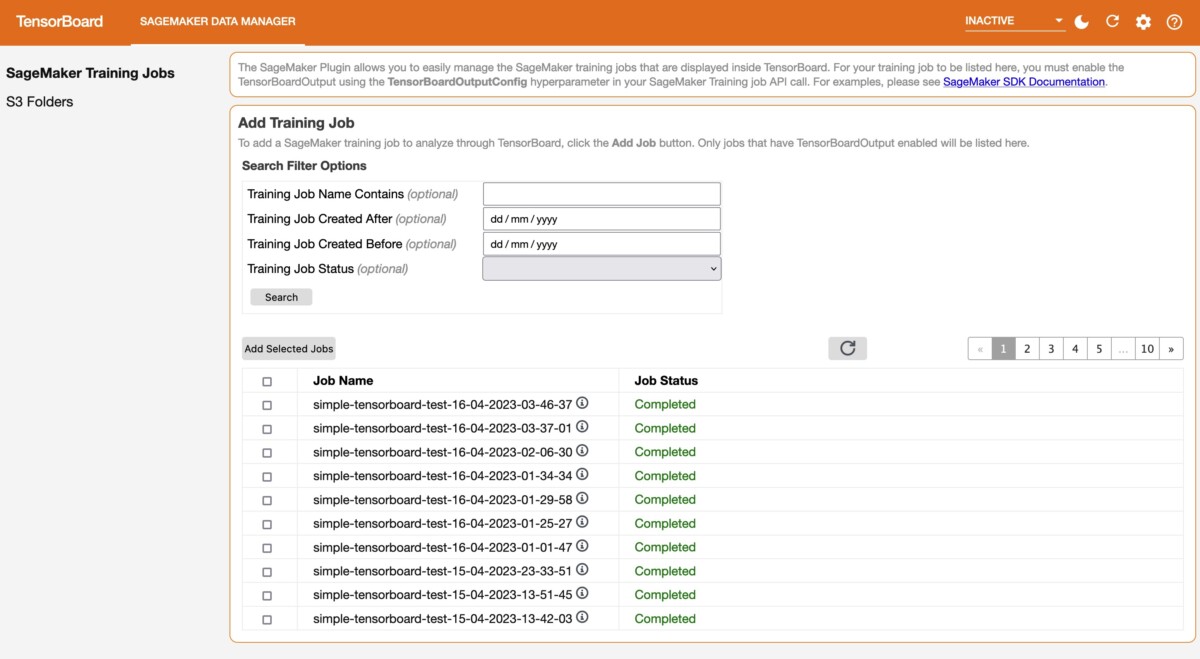
When you open the TensorBoard application, TensorBoard opens with the SageMaker Data Manager tab. The following screenshot shows the full view of the SageMaker Data Manager tab in the TensorBoard application.
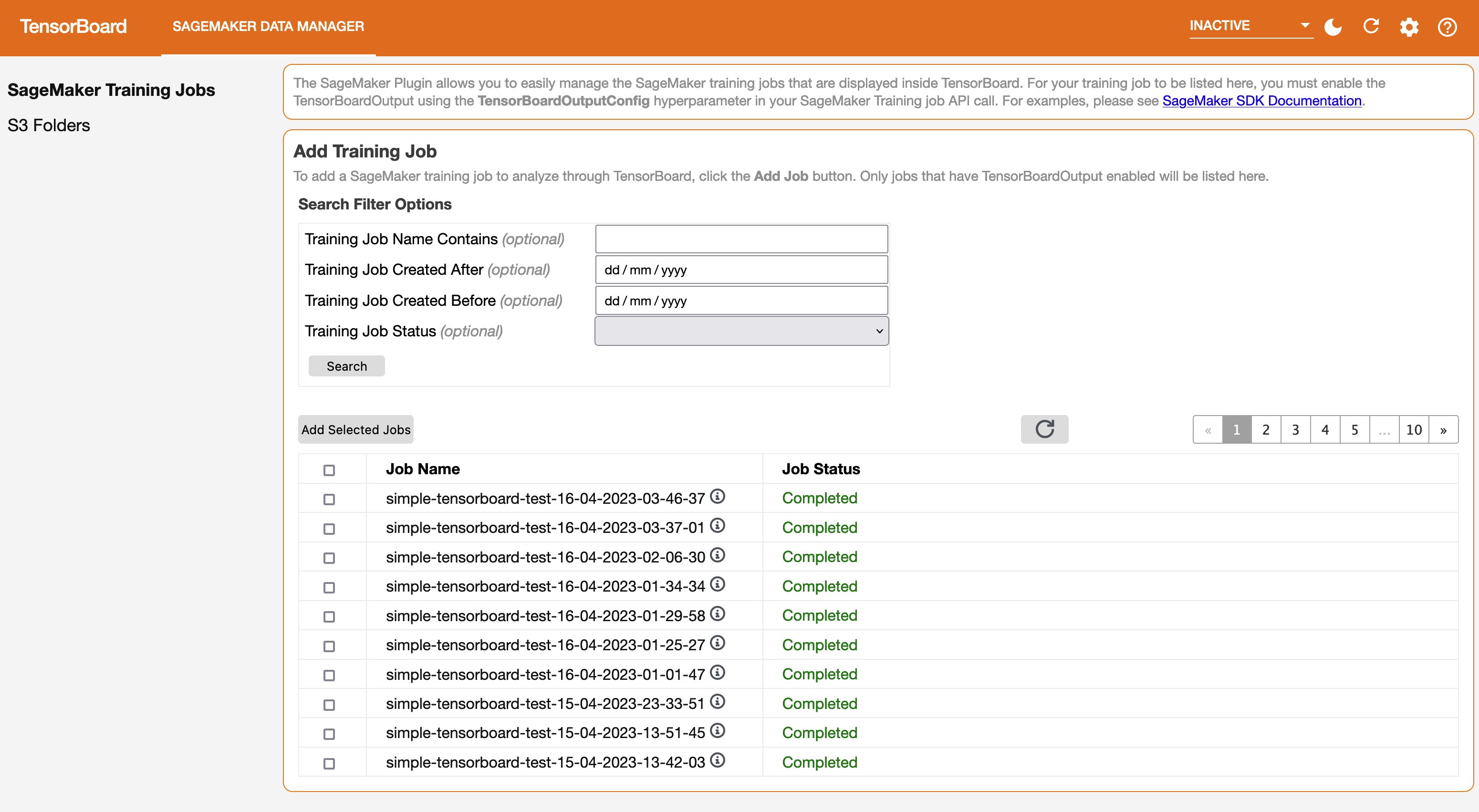
On the SageMaker Data Manager tab, you can select any training job and load TensorBoard-compatible training output data from Amazon S3.
- In the Add Training Job section, use the check boxes to choose training jobs from which you want to pull data and visualize for debugging.
- Choose Add Selected Jobs.
The selected jobs should appear in the Tracked Training Jobs section.
Refresh the viewer by choosing the refresh icon in the upper-right corner, and the visualization tabs should appear after the job data is successfully loaded.
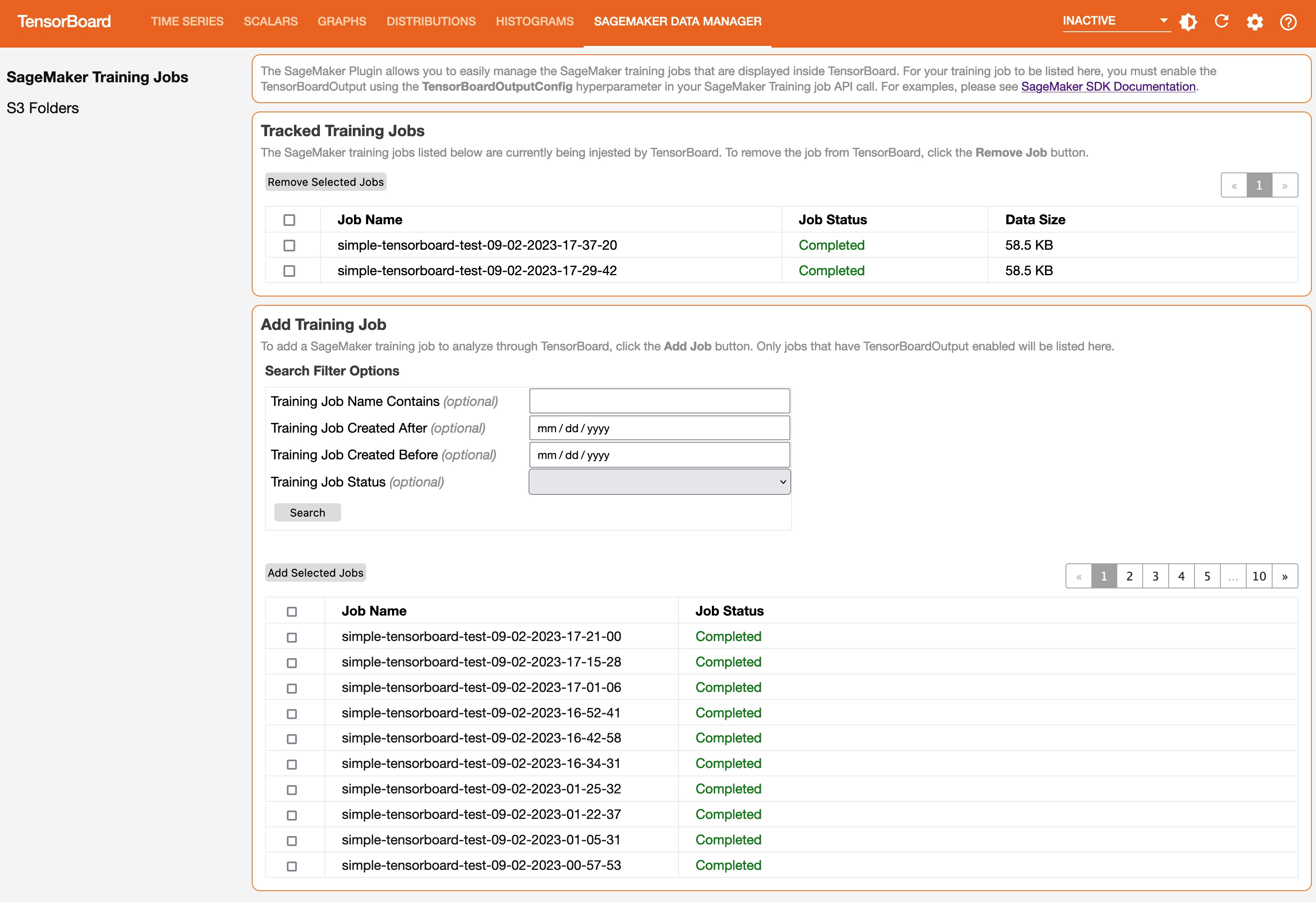
Explore training output data visualized in TensorBoard
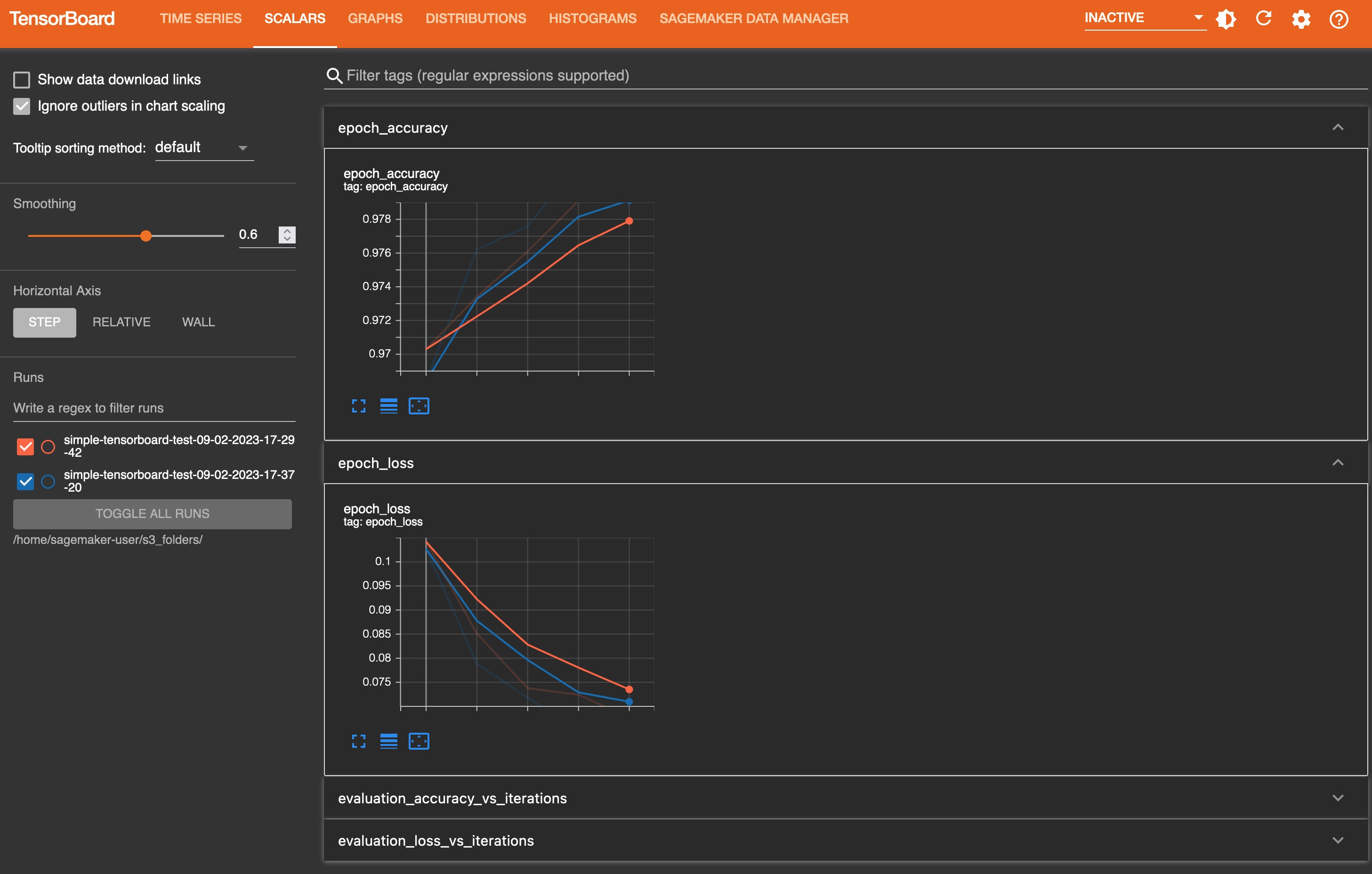
On the Time Series tab and other graphics-based tabs, you can see the list of Tracked Training Jobs in the left pane. You can also use the check boxes of the training jobs to show or hide visualizations. The TensorBoard dynamic plugins are activated dynamically depending on how you have set your training script to include summary writers and pass callbacks for tensor and scalar collection, and the graphics tabs also appear dynamically. The following screenshots show example views of each tab with visualizations of the collected metrics of two training jobs. The metrices include time series, scalar, graph, distribution, and histogram plugins.
The following screenshot is the Time Series tab view.

The following screenshot is the Scalars tab view.
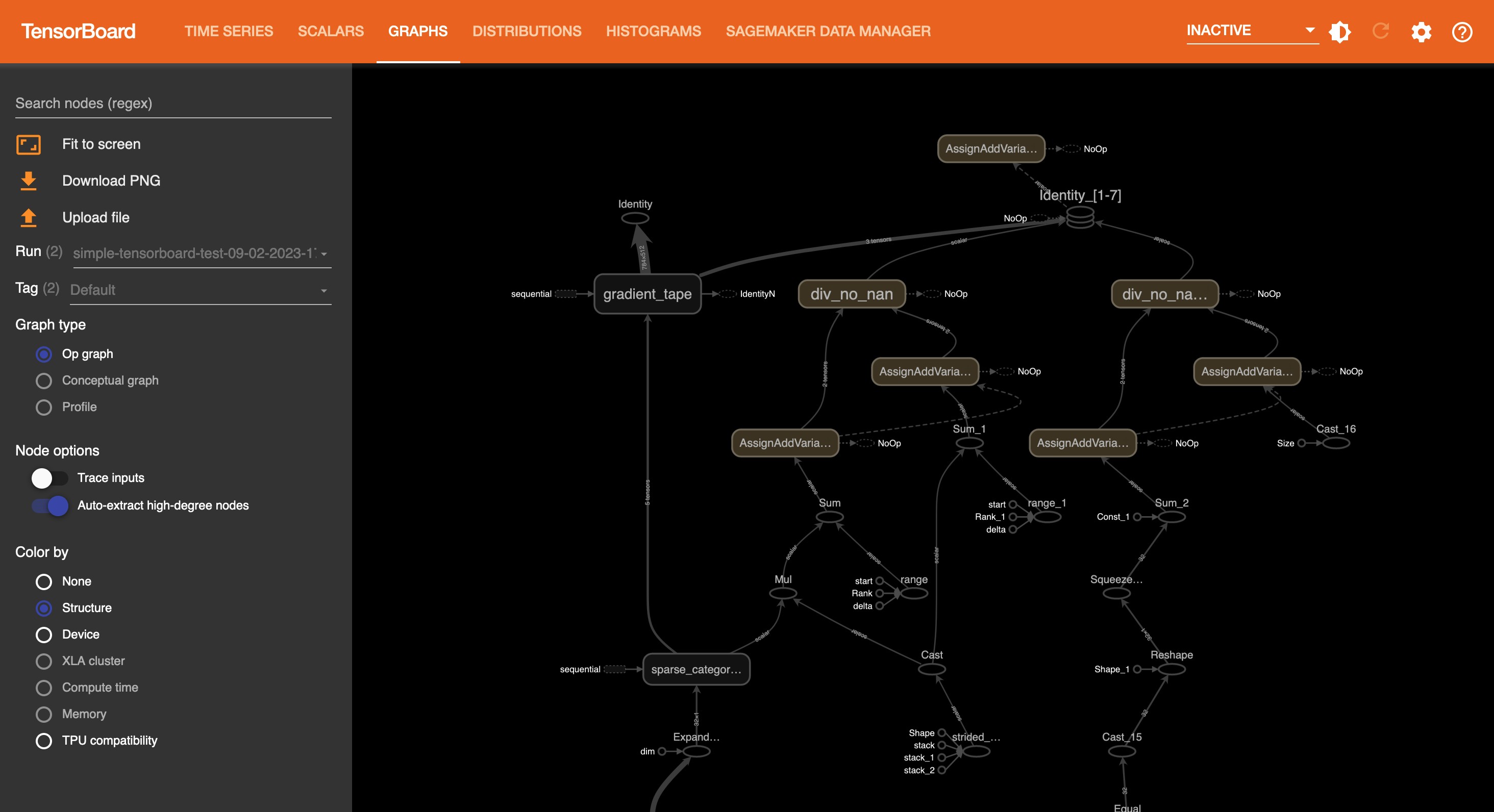
The following screenshot is the Graphs tab view.
The following screenshot is the Distributions tab view.

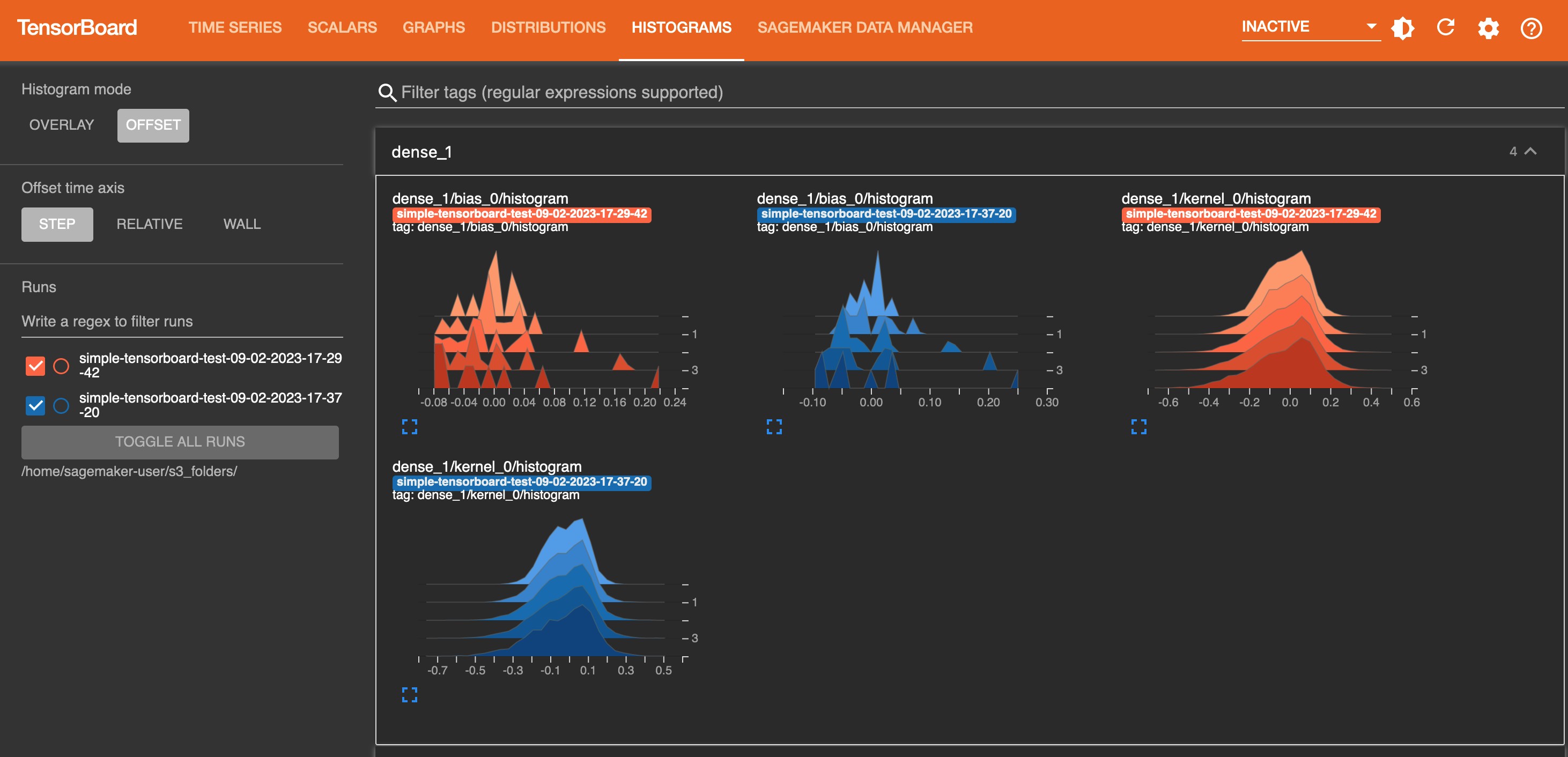
The following screenshot is the Histograms tab view.
Clean up
After you are done with monitoring and experimenting with jobs in TensorBoard, shut the TensorBoard application down:
- On the SageMaker console, choose Domains in the navigation pane.
- Choose your domain.
- Choose your user profile.
- Under Apps, choose Delete App for the TensorBoard row.
- Choose Yes, delete app.
- Enter delete in the text box, then choose Delete.
A message should appear at the top of the page: “Default is being deleted”.
Conclusion
TensorBoard is a powerful tool for visualizing, analyzing, and debugging deep learning models. In this post, we provide a guide to using SageMaker with TensorBoard, including how to set up TensorBoard in a SageMaker training job using the SageMaker Python SDK, access SageMaker TensorBoard, explore training output data visualized in TensorBoard, and delete unused TensorBoard applications. By following these steps, you can start using TensorBoard in SageMaker for your work.
We encourage you to experiment with different features and techniques.
About the authors
 Dr. Baichuan Sun is a Senior Data Scientist at AWS AI/ML. He is passionate about solving strategic business problems with customers using data-driven methodology on the cloud, and he has been leading projects in challenging areas including robotics computer vision, time series forecasting, price optimization, predictive maintenance, pharmaceutical development, product recommendation system, etc. In his spare time he enjoys traveling and hanging out with family.
Dr. Baichuan Sun is a Senior Data Scientist at AWS AI/ML. He is passionate about solving strategic business problems with customers using data-driven methodology on the cloud, and he has been leading projects in challenging areas including robotics computer vision, time series forecasting, price optimization, predictive maintenance, pharmaceutical development, product recommendation system, etc. In his spare time he enjoys traveling and hanging out with family.
 Manoj Ravi is a Senior Product Manager for Amazon SageMaker. He is passionate about building next-gen AI products and works on software and tools to make large-scale machine learning easier for customers. He holds an MBA from Haas School of Business and a Masters in Information Systems Management from Carnegie Mellon University. In his spare time, Manoj enjoys playing tennis and pursuing landscape photography.
Manoj Ravi is a Senior Product Manager for Amazon SageMaker. He is passionate about building next-gen AI products and works on software and tools to make large-scale machine learning easier for customers. He holds an MBA from Haas School of Business and a Masters in Information Systems Management from Carnegie Mellon University. In his spare time, Manoj enjoys playing tennis and pursuing landscape photography.
Author: Baichuan Sun