

Arrange your transcripts into paragraphs with Amazon Transcribe
Amazon Transcribe is a speech recognition service that generates transcripts from video and audio files in multiple supported languages and accents… It comes with a rich set of features, including automatic language identification, multi-channel and multi-speaker support, custom vocabularies, and …
Amazon Transcribe is a speech recognition service that generates transcripts from video and audio files in multiple supported languages and accents. It comes with a rich set of features, including automatic language identification, multi-channel and multi-speaker support, custom vocabularies, and transcript redaction.
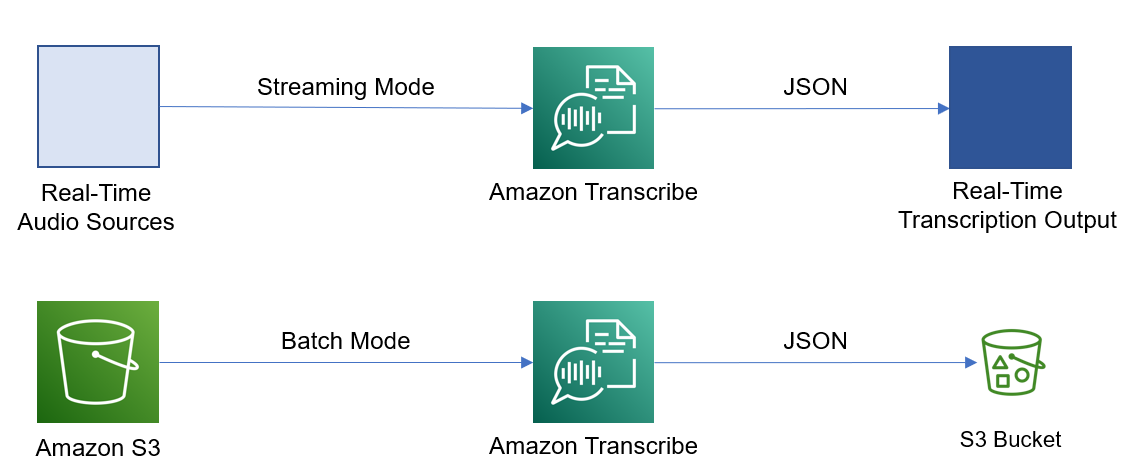
Amazon Transcribe supports two modes of operation: batch and streaming. In batch mode, a transcription job is created to process files residing in an Amazon Simple Storage Service (Amazon S3) bucket; in streaming mode, the audio source is integrated in real time with Amazon Transcribe through HTTP/2 calls or Web Sockets.

In this post, we explore how to automatically arrange the generated transcript into paragraphs while in batch mode, increasing the readability of the generated transcript.
Transcription output
Amazon Transcribe uses JSON representation for its output. It provides the transcription result in two different formats: text format and itemized format.
Text format provides the transcript altogether, as a block of text, whereas itemized format provides the transcript in the form of timely ordered transcribed items, along with additional metadata per item. Both formats exist in parallel in the output file.
Depending on the features selected during transcription job creation, Amazon Transcribe creates additional and enriched views of the transcription result. See the following example code:








Author: Konstantinos Tzouvanas