

Automate the deployment of an Amazon Forecast time-series forecasting model
Time series forecasting refers to the process of predicting future values of time series data (data that is collected at regular intervals over time)… Simple methods for time series forecasting use historical values of the same variable whose future values need to be predicted, whereas more comple…
Time series forecasting refers to the process of predicting future values of time series data (data that is collected at regular intervals over time). Simple methods for time series forecasting use historical values of the same variable whose future values need to be predicted, whereas more complex, machine learning (ML)-based methods use additional information, such as the time series data of related variables.
Amazon Forecast is an ML-based time series forecasting service that includes algorithms that are based on over 20 years of forecasting experience used by Amazon.com, bringing the same technology used at Amazon to developers as a fully managed service, removing the need to manage resources. Forecast uses ML to learn not only the best algorithm for each item, but also the best ensemble of algorithms for each item, automatically creating the best model for your data.
This post describes how to deploy recurring Forecast workloads (time series forecasting workloads) with no code using AWS CloudFormation, AWS Step Functions, and AWS Systems Manager. The method presented here helps you build a pipeline that allows you to use the same workflow starting from the first day of your time series forecasting experimentation through the deployment of the model into production.
Time series forecasting using Forecast
The workflow for Forecast involves the following common concepts:
- Importing datasets – In Forecast, a dataset group is a collection of datasets, schema, and forecast results that go together. Each dataset group can have up to three datasets, one of each dataset type: target time series (TTS), related time series (RTS), and item metadata. A dataset is a collection of files that contain data that is relevant for a forecasting task. A dataset must conform to the schema defined within Forecast. For more details, refer to Importing Datasets.
- Training predictors – A predictor is a Forecast-trained model used for making forecasts based on time series data. During training, Forecast calculates accuracy metrics that you use to evaluate the predictor and decide whether to use the predictor to generate a forecast. For more information, refer to Training Predictors.
- Generating forecasts – You can then use the trained model for generating forecasts for a future time horizon, known as the forecasting horizon. Forecast provides forecasts at various specified quantiles. For example, a forecast at the 0.90 quantile will estimate a value that is lower than the observed value 90% of the time. By default, Forecast uses the following values for the predictor forecast types: 0.1 (P10), 0.5 (P50), and 0.9 (P90). Forecasts at various quantiles are typically used to provide a prediction interval (an upper and lower bound for forecasts) to account for forecast uncertainty.
You can implement this workflow in Forecast either from the AWS Management Console, the AWS Command Line Interface (AWS CLI), via API calls using Python notebooks, or via automation solutions. The console and AWS CLI methods are best suited for quick experimentation to check the feasibility of time series forecasting using your data. The Python notebook method is great for data scientists already familiar with Jupyter notebooks and coding, and provides maximum control and tuning. However, the notebook-based method is difficult to operationalize. Our automation approach facilitates rapid experimentation, eliminates repetitive tasks, and allows easier transition between various environments (development, staging, production).
In this post, we describe an automation approach to using Forecast that allows you to use your own data and provides a single workflow that you can use seamlessly throughout the lifecycle of the development of your forecasting solution, from the first days of experimentation through the deployment of the solution in your production environment.
Solution overview
In the following sections, we describe a complete end-to-end workflow that serves as a template to follow for automated deployment of time series forecasting models using Forecast. This workflow creates forecasted data points from an open-source input dataset; however, you can use the same workflow for your own data, as long as you can format your data according to the steps outlined in this post. After you upload the data, we walk you through the steps to create Forecast dataset groups, import data, train ML models, and produce forecasted data points on future unseen time horizons from raw data. All of this is possible without having to write or compile code.
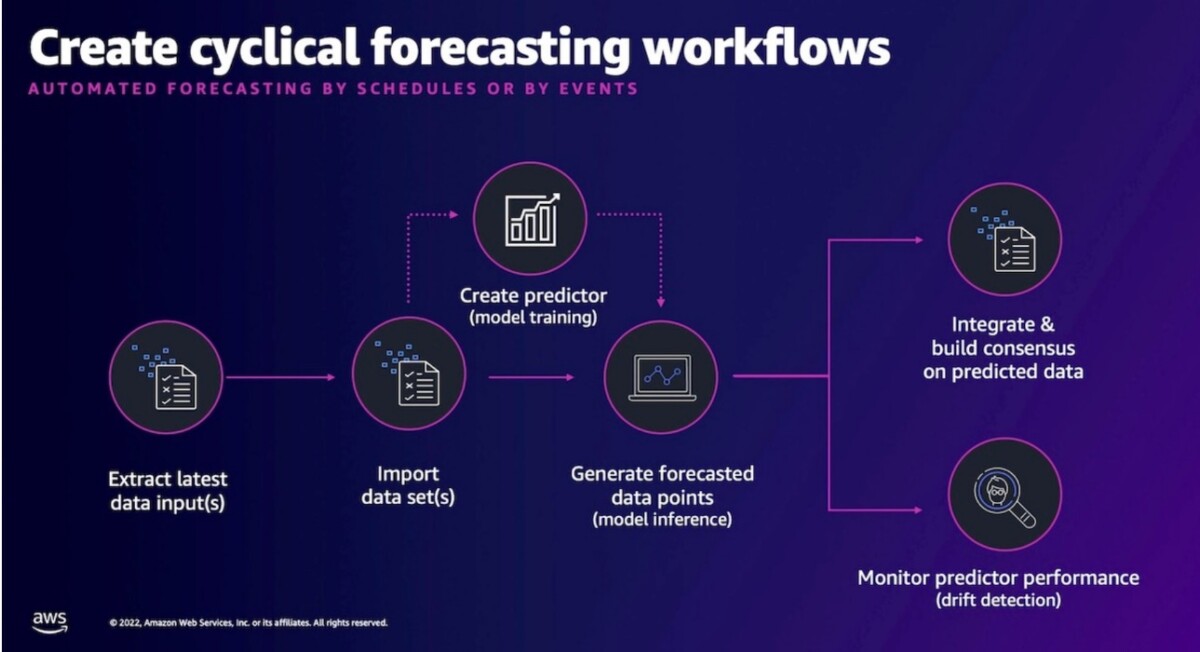
The following diagram illustrates the forecasting workflow.

The solution is deployed using two CloudFormation templates: the dependencies template and the workload template. CloudFormation enables you to perform AWS infrastructure deployments predictably and repeatedly by using templates describing the resources to be deployed. A deployed template is referred to as a stack. We’ve taken care of defining the infrastructure in the solution for you in the two provided templates. The dependencies template defines prerequisite resources used by the workload template, such as an Amazon Simple Storage Service (Amazon S3) bucket for object storage and AWS Identity and Access Management (IAM) permissions for AWS API actions. The resources defined in the dependencies template may be shared by multiple workload templates. The workload template defines the resources used to ingest data, train a predictor, and generate a forecast.

Deploy the dependencies CloudFormation template
First, let’s deploy the dependencies template to create our prerequisite resources. The dependencies template deploys an optional S3 bucket, AWS Lambda functions, and IAM roles. Amazon S3 is a low-cost, highly available, resilient, object storage service. We use an S3 bucket in this solution to store source data and trigger the workflow, resulting in a forecast. Lambda is a serverless, event-driven compute service that lets you run code without provisioning or managing servers. The dependencies template includes functions to do things like create a dataset group in Forecast and purge objects within an S3 bucket before deleting the bucket. IAM roles define permissions within AWS for users and services. The dependencies template deploys a role to be used by Lambda and another for Step Functions, a workflow management service that will coordinate the tasks of data ingestion and processing, as well as predictor training and inference using Forecast.
Complete the following steps to deploy the dependencies template:
- On the console, select the desired Region supported by Forecast for solution deployment.
- On the AWS CloudFormation console, choose Stacks in the navigation pane.
- Choose Create stack and choose With new resources (standard).

- For Template source, select Amazon S3 URL.
- Enter the template URL:
https://amazon-forecast-samples.s3.us-west-2.amazonaws.com/ml_ops/forecast-mlops-dependency.yaml. - Choose Next.

- For Stack name, enter
forecast-mlops-dependency. - Under Parameters, choose to use an existing S3 bucket or create a new one, then provide the name of the bucket.
- Choose Next.
- Choose Next to accept the default stack options.
- Select the check box to acknowledge the stack creates IAM resources, then choose Create stack to deploy the template.


You should see the template deploy as the forecast-mlops-dependency stack. When the status changes to CREATE_COMPLETE, you may move to the next step.
Deploy the workload CloudFormation template
Next, let’s deploy the workload template to create our prerequisite resources. The workload template deploys Step Functions state machines for workflow management, AWS Systems Manager Parameter Store parameters to store parameter values from AWS CloudFormation and inform the workflow, an Amazon Simple Notification Service (Amazon SNS) topic for workflow notifications, and an IAM role for workflow service permissions.
The solution creates five state machines:
- CreateDatasetGroupStateMachine – Creates a Forecast dataset group for data to be imported into.
- CreateImportDatasetStateMachine – Imports source data from Amazon S3 into a dataset group for training.
- CreateForecastStateMachine – Manages the tasks required to train a predictor and generate a forecast.
- AthenaConnectorStateMachine – Enables you to write SQL queries with the Amazon Athena connector to land data in Amazon S3. This is an optional process to obtain historical data in the required format for Forecast by using Athena instead of placing files manually in Amazon S3.
- StepFunctionWorkflowStateMachine – Coordinates calls out to the other four state machines and manages the overall workflow.
Parameter Store, a capability of Systems Manager, provides secure, hierarchical storage and programmatic retrieval of configuration data management and secrets management. Parameter Store is used to store parameters set in the workload stack as well as other parameters used by the workflow.
Complete the following steps to deploy the workload template:
- On the AWS CloudFormation console, choose Stacks in the navigation pane.
- Choose Create stack and choose With new resources (standard).
- For Template source, select Amazon S3 URL.
- Enter the template URL:
https://amazon-forecast-samples.s3.us-west-2.amazonaws.com/ml_ops/forecast-mlops-solution-guidance.yaml. - Choose Next.
- For Stack name, enter a name.
- Accept the default values or modify the parameters.
Be sure to enter the S3 bucket name from the dependencies stack for S3 Bucket and a valid email address for SNSEndpoint even if you accept the default parameter values.
The following table describes each parameter.
| Parameter | Description | More Information |
DatasetGroupFrequencyRTS | The frequency of data collection for the RTS dataset. | . |
DatasetGroupFrequencyTTS | The frequency of data collection for the TTS dataset. | . |
DatasetGroupName | A short name for the dataset group, a self-contained workload. | CreateDatasetGroup |
DatasetIncludeItem | Specify if you want to provide item metadata for this use case. | . |
DatasetIncludeRTS | Specify if you want to provide a related time series for this use case. | . |
ForecastForecastTypes | When a CreateForecast job runs, this declares which quantiles to produce predictions for. You may choose up to five values in this array. Edit this value to include values according to need. | CreateForecast |
PredictorAttributeConfigs | For the target variable in TTS and each numeric field in the RTS datasets, a record must be created for each time interval for each item. This configuration helps determine how missing records are filled in: with 0, NaN, or otherwise. We recommend filing the gaps in the TTS with NaN instead of 0. With 0, the model might learn wrongly to bias forecasts toward 0. NaN is how the guidance is delivered. Consult with your AWS Solutions Architect with any questions on this. | CreateAutoPredictor |
PredictorExplainPredictor | Valid values are TRUE or FALSE. These determine if explainability is enabled for your predictor. This can help you understand how values in the RTS and item metadata influence the model. | Explainability |
PredictorForecastDimensions | You may want to forecast at a finer grain than item. Here, you can specify dimensions such as location, cost center, or whatever your needs are. This needs to agree with the dimensions in your RTS and TTS. Note that if you have no dimension, the correct parameter is null, by itself and in all lowercase. null is a reserved word that lets the system know there is no parameter for the dimension. | CreateAutoPredictor |
PredictorForecastFrequency | Defines the time scale at which your model and predictions will be generated, such as daily, weekly, or monthly. The drop-down menu helps you choose allowed values. This needs to agree with your RTS time scale if you’re using RTS. | CreateAutoPredictor |
PredictorForecastHorizon | The number of time steps that the model predicts. The forecast horizon is also called the prediction length. | CreateAutoPredictor |
PredictorForecastOptimizationMetric | Defines the accuracy metric used to optimize the predictor. The drop-down menu will help you select weighted quantile loss balances for over- or under-forecasting. RMSE is concerned with units, and WAPE/MAPE are concerned with percent errors. | CreateAutoPredictor |
PredictorForecastTypes | When a CreateAutoPredictor job runs, this declares which quantiles are used to train prediction points. You may choose up to five values in this array, allowing you to balance over- and under-forecasting. Edit this value to include values according to need. | CreateAutoPredictor |
S3Bucket | The name of the S3 bucket where input data and output data are written for this workload. | . |
SNSEndpoint | A valid email address to receive notifications when the predictor and Forecast jobs are complete. | . |
SchemaITEM | This defines the physical order, column names, and data types for your item metadata dataset. This is an optional file provided in the solution example. | CreateDataset |
SchemaRTS | This defines the physical order, column names, and data types for your RTS dataset. The dimensions must agree with your TTS. The time-grain of this file governs the time-grain at which predictions can be made. This is an optional file provided in the solution example. | CreateDataset |
SchemaTTS | This defines the physical order, column names, and data types for your TTS dataset, the only required dataset. The file must contain a target value, timestamp, and item at a minimum. | CreateDataset |
TimestampFormatRTS | Defines the timestamp format provided in the RTS file. | CreateDatasetImportJob |
TimestampFormatTTS | Defines the timestamp format provided in the TTS file. | CreateDatasetImportJob |
- Choose Next to accept the default stack options.
- Select the check box to acknowledge the stack creates IAM resources, then choose Create stack to deploy the template.
You should see the template deploy as the stack name you chose earlier. When the status changes to CREATE_COMPLETE, you may move to the data upload step.
Upload the data
In the previous section, you provided a stack name and an S3 bucket. This section describes how to deposit the publicly available dataset Food Demand in this bucket. If you’re using your own dataset, refer to Datasets to prepare your dataset in a format the deployment is expecting. The dataset needs to contain at least the target time series, and optionally, the related time series and the item metadata:
- TTS is the time series data that includes the field that you want to generate a forecast for; this field is called the target field
- RTS is time series data that doesn’t include the target field, but includes a related field
- The item data file isn’t time series data, but includes metadata information about the items in the TTS or RTS datasets
Complete the following steps:
- If you’re using the provided sample dataset, download the dataset Food Demand to your computer and unzip the file, which creates three files inside three directories (
rts,tts,item). - On the Amazon S3 console, navigate to the bucket you created earlier.
- Choose Create folder.
- Use the same string as your workload stack name for the folder name.
- Choose Upload.
- Choose the three dataset folders, then choose Upload.
When the upload is complete, you should see something like the following screenshot. For this example, our folder is aiml42.
Create a Forecast dataset group
Complete the steps in this section to create a dataset group as a one-time event for each workload. Going forward, you should plan on running the import data, create predictor, and create forecast steps as appropriate, as a series, according to your schedule, which could be daily, weekly, or otherwise.
- On the Step Functions console, locate the state machine containing
Create-Dataset-Group. - On the state machine detail page, choose Start execution.
- Choose Start execution again to confirm.
The state machine takes about 1 minute to run. When it’s complete, the value under Execution Status should change from Running to Succeeded 
Import data into Forecast
Follow the steps in this section to import the data set that you uploaded to your S3 bucket into your dataset group:
- On the Step Functions console, locate the state machine containing
Import-Dataset. - On the state machine detail page, choose Start Execution.
- Choose Start execution again to confirm.
The amount of time the state machine takes to run depends on the dataset being processed.

- While this is running, in your browser, open another tab and navigate to the Forecast console.
- On the Forecast console, choose View dataset groups and navigate to the dataset group with the name specified for
DataGroupNamefrom your workload stack. - Choose View datasets.
You should see the data imports in progress.

When the state machine for Import-Dataset is complete, you can proceed to the next step to build your time series data model.
Create AutoPredictor (train a time series model)
This section describes how to train an initial predictor with Forecast. You may choose to create a new predictor (your first, baseline predictor) or retrain a predictor during each production cycle, which could be daily, weekly, or otherwise. You may also elect not to create a predictor each cycle and rely on predictor monitoring to guide you when to create one. The following figure visualizes the process of creating a production-ready Forecast predictor.

To create a new predictor, complete the following steps:
- On the Step Functions console, locate the state machine containing
Create-Predictor. - On the state machine detail page, choose Start Execution.
- Choose Start execution again to confirm.
The amount of runtime can depend on the dataset being processed. This could take up to an hour or more to complete. - While this is running, in your browser, open another tab and navigate to the Forecast console.
- On the Forecast console, choose View dataset groups and navigate to the dataset group with the name specified for
DataGroupNamefrom your workload stack. - Choose View predictors.
You should see the predictor training in progress (Training status shows “Create in progress…”).

When the state machine for Create-Predictor is complete, you can evaluate its performance.
As part of the state machine, the system creates a predictor and also runs a BacktestExport job that writes out time series-level predictor metrics to Amazon S3. These are files located in two S3 folders under the backtest-export folder:
- accuracy-metrics-values – Provides item-level accuracy metric computations so you can understand the performance of a single time series. This allows you to investigate the spread rather than focusing on the global metrics alone.
- forecasted-values – Provides step-level predictions for each time series in the backtest window. This enables you to compare the actual target value from a holdout test set to the predicted quantile values. Reviewing this helps formulate ideas on how to provide additional data features in RTS or item metadata to help better estimate future values, further reducing loss. You may download
backtest-exportfiles from Amazon S3 or query them in place with Athena.

With your own data, you need to closely inspect the predictor outcomes and ensure the metrics meet your expected results by using the backtest export data. When satisfied, you can begin generating future-dated predictions as described in the next section.
Generate a forecast (inference about future time horizons)
This section describes how to generate forecast data points with Forecast. Going forward, you should harvest new data from the source system, import the data into Forecast, and then generate forecast data points. Optionally, you may also insert a new predictor creation after import and before forecast. The following figure visualizes the process of creating production time series forecasts using Forecast.

Complete the following steps:
- On the Step Functions console, locate the state machine containing
Create-Forecast. - On the state machine detail page, choose Start Execution.
- Choose Start execution again to confirm.
This state machine finishes very quickly because the system isn’t configured to generate a forecast. It doesn’t know which predictor model you have approved for inference.
Let’s configure the system to use your trained predictor. - On the Forecast console, locate the ARN for your predictor.
- Copy the ARN to use in a later step.

- In your browser, open another tab and navigate to the Systems Manager console.
- On the Systems Manager console, choose Parameter Store in the navigation pane.
- Locate the parameter related to your stack (
/forecast/<StackName>/Forecast/PredictorArn). - Enter the ARN you copied for your predictor.
This is how you associate a trained predictor with the inference function of Forecast. - Locate the parameter
/forecast/<StackName>/Forecast/Generateand edit the value, replacingFALSEwithTRUE.
Now you’re ready to run a forecast job for this dataset group. - On the Step Functions console, run the
Create-Forecaststate machine.

This time, the job runs as expected. As part of the state machine, the system creates a forecast and a ForecastExport job, which writes out time series predictions to Amazon S3. These files are located in the forecast folder

Inside the forecast folder, you will find predictions for your items, located in many CSV or Parquet files, depending on your selection. The predictions for each time step and selected time series exist with all your chosen quantile values per record. You may download these files from Amazon S3, query them in place with Athena, or choose another strategy to use the data.
This wraps up the entire workflow. You can now visualize your output using any visualization tool of your choice, such as Amazon QuickSight. Alternatively, data scientists can use pandas to generate their own plots. If you choose to use QuickSight, you can connect your forecast results to QuickSight to perform data transformations, create one or more data analyses, and create visualizations.
This process provides a template to follow. You will need to adapt the sample to your schema, set the forecast horizon, time resolution, and so forth according to your use case. You will also need to set a recurring schedule where data is harvested from the source system, import the data, and produce forecasts. If desired, you may insert a predictor task between the import and forecast steps.
Retrain the predictor
We have walked through the process of training a new predictor, but what about retraining a predictor? Retraining a predictor is one way to reduce the cost and time involved with training a predictor on the latest available data. Rather than create a new predictor and train it on the entire dataset, we can retrain the existing predictor by providing only the new incremental data made available since the predictor was last trained. Let’s walk through how to retrain a predictor using the automation solution:
- On the Forecast console, choose View dataset groups.
- Choose the dataset group associated with the predictor you want to retrain.
- Choose View predictors, then chose the predictor you want to retrain.
- On the Settings tab, copy the predictor ARN.
We need to update a parameter used by the workflow to identify the predictor to retrain. - On the Systems Manager console, choose Parameter Store in the navigation pane.
- Locate the parameter
/forecast/<STACKNAME>/Forecast/Predictor/ReferenceArn. - On the parameter detail page, choose Edit.
- For Value, enter the predictor ARN.
This identifies the correct predictor for the workflow to retrain. Next, we need to update a parameter used by the workflow to change the training strategy. - Locate the parameter
/forecast/<STACKNAME>/Forecast/Predictor/Strategy. - On the parameter detail page, choose Edit.
- For Value, enter
RETRAIN.
The workflow defaults to training a new predictor; however, we can modify that behavior to retrain an existing predictor or simply reuse an existing predictor without retraining by setting this value toNONE. You may want to forego training if your data is relatively stable or you’re using automated predictor monitoring to decide when retraining is necessary. - Upload the incremental training data to the S3 bucket.
- On the Step Functions console, locate the state machine
<STACKNAME>-Create-Predictor. - On the state machine detail page, choose Start execution to begin the retraining.
When the retraining is complete, the workflow will end and you will receive an SNS email notification to the email address provided in the workload template parameters.
Clean up
When you’re done with this solution, follow the steps in this section to delete related resources.
Delete the S3 bucket
- On the Amazon S3 console, choose Buckets in the navigation pane.
- Select the bucket where data was uploaded and choose Empty to delete all data associated with the solution, including source data.
- Enter
permanently deleteto delete the bucket contents permanently. - On the Buckets page, select the bucket and choose Delete.
- Enter the name of the bucket to confirm the deletion and choose Delete bucket.
Delete Forecast resources
- On the Forecast console, choose View dataset groups.
- Select the dataset group name associated with the solution, then choose Delete.
- Enter
deleteto delete the dataset group and associated predictors, predictor backtest export jobs, forecasts, and forecast export jobs. - Choose Delete to confirm.
Delete the CloudFormation stacks
- On the AWS CloudFormation console, choose Stacks in the navigation pane.
- Select the workload stack and choose Delete.
- Choose Delete stack to confirm deletion of the stack and all associated resources.
- When the deletion is complete, select the dependencies stack and choose Delete.
- Choose Delete to confirm.
Conclusion
In this post, we discussed some different ways to get started using Forecast. We walked through an automated forecasting solution based on AWS CloudFormation for a rapid, repeatable solution deployment of a Forecast pipeline from data ingestion to inference, with little infrastructure knowledge required. Finally, we saw how we can use Lambda to automate model retraining, reducing cost and training time.
There’s no better time than the present to start forecasting with Forecast. To start building and deploying an automated workflow, visit Amazon Forecast resources. Happy forecasting!
About the Authors
 Aaron Fagan is a Principal Specialist Solutions Architect at AWS based in New York. He specializes in helping customers architect solutions in machine learning and cloud security.
Aaron Fagan is a Principal Specialist Solutions Architect at AWS based in New York. He specializes in helping customers architect solutions in machine learning and cloud security.
 Raju Patil is a Data Scientist in AWS Professional Services. He builds and deploys AI/ML solutions to assist AWS customers in overcoming their business challenges. His AWS engagements have covered a wide range of AI/ML use cases such as computer vision, time-series forecasting, and predictive analytics, etc., across numerous industries, including financial services, telecom, health care, and more. Prior to this, he has led Data Science teams in Advertising Technology, and made significant contributions to numerous research and development initiatives in computer vision and robotics. Outside of work, he enjoys photography, hiking, travel, and culinary explorations.
Raju Patil is a Data Scientist in AWS Professional Services. He builds and deploys AI/ML solutions to assist AWS customers in overcoming their business challenges. His AWS engagements have covered a wide range of AI/ML use cases such as computer vision, time-series forecasting, and predictive analytics, etc., across numerous industries, including financial services, telecom, health care, and more. Prior to this, he has led Data Science teams in Advertising Technology, and made significant contributions to numerous research and development initiatives in computer vision and robotics. Outside of work, he enjoys photography, hiking, travel, and culinary explorations.
Author: Aaron Fagan