

AWS CloudHSM architectural considerations for crypto user credential rotation
This blog post provides architectural guidance on AWS CloudHSM crypto user credential rotation and is intended for those using or considering using CloudHSM… CloudHSM is a popular solution for secure cryptographic material management… By using this service, organizations can benefit from a robus…
This blog post provides architectural guidance on AWS CloudHSM crypto user credential rotation and is intended for those using or considering using CloudHSM. CloudHSM is a popular solution for secure cryptographic material management. By using this service, organizations can benefit from a robust mechanism to manage their own dedicated FIPS 140-2 level 3 hardware security module (HSM) cluster in the cloud and a client SDK that enables crypto users to perform cryptographic operations on deployed HSMs.
Credential rotation is an AWS Well-Architected best practice as it helps reduce the risks associated with the use of long-term credentials. Additionally, organizations are often required to rotate crypto user credentials for their HSM clusters to meet compliance, regulatory, or industry requirements. Unlike most AWS services that use AWS Identity and Access Management (IAM) users or IAM policies to access resources within your cluster, HSM users are directly created and maintained on the HSM cluster. As a result, how the credential rotation operation is performed might impact the workload’s availability. Thus, it’s important to understand the available options to perform crypto user credential rotation and the impact each option has in terms of ease of implementation and downtime.
In this post, we dive deep into the different options, steps to implement them, and their related pros and cons. We finish with a matrix of the relative downtime, complexity, and cost of each option so you can choose which best fits your use case.
Solution overview
In this document, we consider three approaches:
Approach 1 — For a workload with a defined maintenance window. You can shut down all client connections to CloudHSM, change the crypto user’s password, and subsequently re-establish connections to CloudHSM. This option is the most straightforward, but requires some application downtime.
Approach 2 — You create an additional crypto user (with access to all cryptographic materials) with a new password and from which new client instances are deployed. When the new user and instances are in place, traffic is rerouted to the new instances through a load balancer. This option involves no downtime but requires additional infrastructure (client instances) and a process to share cryptographic material between the crypto users.
Approach 3 — You run two separate and identical environments, directing traffic to a live (blue) environment while making and testing the changes on a secondary (green) environment before redirecting traffic to the green environment. This option involves no downtime, but requires additional infrastructure (client instances and an additional CloudHSM cluster) to support the blue/green deployment strategy.
Solution prerequisites
- A network path to a CloudHSM cluster. To learn more, see Launch an Amazon Elastic Compute Cloud (Amazon EC2) client instance.
- Install and configure the CloudHSM command line interface(CLI).
- Access to the crypto user password.
Approach 1
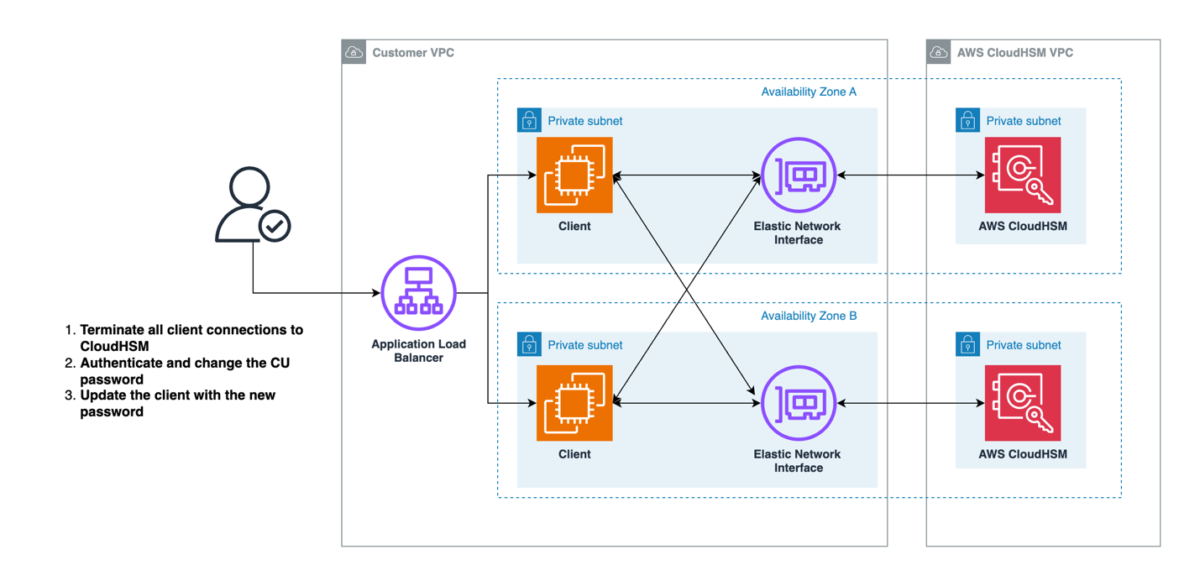
The first approach uses an application’s planned maintenance window to enact necessary crypto user password changes. It’s the most straightforward of the recommended options, with the least amount of complexity because no additional infrastructure is needed to support the password rotation activity. However, it requires downtime (preferably planned) to rotate the password and update the client application instances; depending on how you deploy a client application, you can shorten the downtime by automating the application deployment process. The main steps for this approach are shown in Figure 1:

Figure 1: Approach 1 to update crypto user password
To implement approach 1:
- Terminate all client connections to a CloudHSM cluster. This is necessary because you cannot change a password while a crypto user’s session is active.
- You can query an Amazon CloudWatch log group for your CloudHSM cluster to find out if any user session is active. Additionally, you can audit Amazon Virtual Private Cloud (Amazon VPC) Flow Logs by enabling them for the elastic network interfaces (ENIs) related to the CloudHSM cluster. See where the traffic is coming from and link that to the applications.
- Change the crypto user password
- Use the following command to start CloudHSM CLI interactive mode.
Windows: C:Program FilesAmazonCloudHSMbin> .cloudhsm-cli.exe interactiveLinux: $ /opt/cloudhsm/bin/cloudhsm-cli interactive
- Use the login command and log in as the user with the password you want to change.
aws-cloudhsm > login --username <USERNAME> --role <ROLE> - Enter the user’s password.
- Enter the user change-password command.
aws-cloudhsm > user change-password --username <USERNAME> --role <ROLE> - Enter the new password.
- Re-enter the new password.
- Use the following command to start CloudHSM CLI interactive mode.
- Update the client connecting to CloudHSM to use the new credentials. Follow the SDK documentation for detailed steps if you are using PKCS # 11, OpenSSL Dynamic Engine, JCE provider or KSP and CNG provider.
- Resume all client connections to CloudHSM cluster
Approach 2
The second approach employs two crypto users and a blue/green deployment strategy, that is, a deployment strategy in which you create two separate but identical client environments. One environment (blue) runs the current application version with crypto user 1 (CU1) and handles live traffic, while the other environment (green) runs a new application version with the updated crypto user 2 (CU2) password. After testing is complete on the green environment, traffic is directed to the green environment and the blue environment is deprecated. In this approach, both crypto users have access to the required cryptographic material. When rotating the crypto user password, you spin up new client instances and swap connection credentials to use the second crypto user. Because the client application only uses one crypto user at a time, the second user can remain dormant and be reused in the future as well. When compared to the first approach, this approach adds complexity to your architecture so that you can redirect live application traffic to the new environment by deploying additional client instances without having to restart. You also need to be aware that a shared user can only perform sign, encrypt, decrypt, verify, and HMAC operations with the shared key. Currently, export, wrap, modify, delete, and derive operations aren’t allowed with a shared user. This approach has the advantages of a classic blue/green deployment (no downtime and low risk), in addition to adding redundancy at the user management level by having multiple crypto users with access to the required cryptographic material. Figure 2 depicts a possible architecture:

Figure 2: Approach 2 to update crypto user password
To implement Approach 2:
- Set up two crypto users on the CloudHSM cluster, for example CU1 and CU2.
- Create cryptographic material required by your application.
- Use the key share command to share the key with the other user so that both users have access to all the keys.
- Start by running the key list command with a filter to return a specific key.
- View the
shared-usersoutput to identify whom the key is currently shared with. - To share this key with a crypto user, enter the following command:
aws-cloudhsm > aws-cloudhsm > key share --filter attr.label="rsa_key_to_share" attr.class=private-key --username <USERNAME> --role crypto-user
- If CU1 is used to make client (that is, blue environment) connections to a CloudHSM cluster then change the password for CU2.
- Follow the instructions in To change HSM user passwords or step 2 of Approach 1 to change the password assigned to CU2.
- Spin up new client instances and use CU2 to configure the connection credentials (that is, green environment).
- Add the new client instances to a new target group for the existing Application Load Balancer (ALB).
- Next use the weighted target groups routing feature of ALB to route traffic to the newly configured environment.
- You can use forward actions of the ALB listener rules setting to route requests to one or more target groups.
- If you specify multiple target groups for a forward action, you must specify a weight for each target group. Each target group weight is a value from 0 to 999. Requests that match a listener rule with weighted target groups are distributed to these target groups based on their weights. For example, if you specify one with a weight of 10 and the other with a weight of 20, the target group with a weight of 20 receives twice as many requests as the other target group.
- You can make these changes to the ALB setting using the AWS Command Line Interface (AWS CLI), AWS Management Console, or supported infrastructure as code (IaC) tools.
- For more information, see Fine-tuning blue/green deployments on application load balancer.
- For the next password rotation iteration, you can switch back to using CU1 with updated credentials by updating your client instances and redeploying using steps 6 and 7.
Approach 3
The third approach is a variation of the previous approach as you build an identical environment (blue/green deployment) and change the crypto user password on the new environment to achieve zero downtime for the workload. You create two separate but identical CloudHSM clusters, with one serving as the live (blue) environment, and another as the test (green) environment in which changes are tested prior to deployment. After testing is complete in the green environment, production traffic is directed to the green environment and the blue environment is deprecated. Again, this approach adds complexity to your architecture so that you can redirect live application traffic to the new environment by deploying additional client instances and a CloudHSM cluster during the deployment and cutover window without having to restart. Additionally, changes made to the blue cluster after the green cluster was created won’t be available in the green cluster—something that can be mitigated by a brief embargo on changes while this cutover process is in progress. A key advantage to this approach is that it increases application availability without the need for a second crypto user, while still reducing deployment risk and simplifying the rollback process if a deployment fails. Such a deployment pattern is typically automated using continuous integration and continuous delivery (CI/CD) tools such as AWS CodeDeploy. For detailed deployment configuration options, see deployment configurations in CodeDeploy. Figure 3 depicts a possible architecture:

Figure 3: Approach 3 to update crypto user password
To implement approach 3:
- Create a cluster from backup. Make sure you restore the new cluster in the same Availability Zone as the existing CloudHSM cluster. This will be your green environment.
- Spin up new application instances (green environment) and configure them to connect to the new CloudHSM cluster.
- Take note of the new CloudHSM cluster security group and attach it to the new client instances.
- Follow the steps in To change HSM user passwords or Approach 1 step 2 to change the crypto user password on the new cluster.
- Update the client connecting to CloudHSM with the new password.
- Add the new client to the existing Application Load Balancer by following Approach 2 steps 6 and 7.
- After the deployment is complete, you can delete the old cluster and client instances (blue environment).
- To delete the CloudHSM cluster using the console.
- Open the AWS CloudHSM console.
- Select the old cluster and then choose Delete cluster.
- Confirm that you want to delete the cluster, then choose Delete.
- To delete the cluster using the AWS Command Line Interface (AWS CLI), use the following command:
aws cloudhsmv2 delete-cluster --cluster-id <cluster ID>
- To delete the CloudHSM cluster using the console.
How to choose an approach
To better understand which approach is the best fit for your use case, consider the following criteria:
- Downtime: What is the acceptable amount of downtime for your workload?
- Implementation complexity: Do you need to make architecture changes to your workload and how complex is the implementation effort?
- Cost: Is the additional cost required for the approach acceptable to the business?
| Downtime | Relative Implementation complexity | Relative infrastructure cost | |
| Approach 1 | Yes | Low | None |
| Approach 2 | No | Medium | Medium |
| Approach 3 | No | Medium | High |
Approach 1 — especially when run within a scheduled maintenance window—is the most straightforward of the three approaches because there’s no additional infrastructure required, and workload downtime is the only tradeoff. This is best suited for applications where planned downtime is acceptable and you need to keep solution complexity low.
Approach 2 involves no downtime for the workload and the second crypto user serves as a backup for future password updates (such as if credentials are lost, or in case there are personnel changes). The downside is the initial planning required to set up the workload to handle multiple CUs, share all keys among the crypto users, and the additional cost. This is best suited for workloads that require zero downtime and an architecture that supports hot swapping of incoming traffic.
Approach 3 also supports zero downtime for the workload, with a complex implementation and some cost to set up additional infrastructure. This is best suited for workloads that have require zero downtime, have an architecture supports hot swapping of incoming traffic, and you don’t want to maintain a second crypto user that has shared access to all required cryptographic material.
Conclusion
In this post, we covered three approaches you can take to rotate the crypto user password on your CloudHSM cluster to align with AWS security best practices of the Well-Architected Framework and to meet your compliance, regulatory, or industry requirements. Each has considerations in terms of relative cost, complexity, and downtime. We recommend carefully considering mapping them to your workload and picking the approach best suited for your business and workload needs.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on the AWS CloudHSM re:Post or contact AWS Support.
Author: Shankar Rajagopalan