

Best practices for Amazon SageMaker HyperPod task governance
Administrators can use SageMaker HyperPod task governance to govern allocation of accelerated compute to teams and projects, and enforce policies that determine the priorities across different types of tasks… The resulting improvement in utilization of compute resources enables organizations to f…
At AWS re:Invent 2024, we launched a new innovation in Amazon SageMaker HyperPod on Amazon Elastic Kubernetes Service (Amazon EKS) that enables you to run generative AI development tasks on shared accelerated compute resources efficiently and reduce costs by up to 40%. Administrators can use SageMaker HyperPod task governance to govern allocation of accelerated compute to teams and projects, and enforce policies that determine the priorities across different types of tasks. The resulting improvement in utilization of compute resources enables organizations to focus on accelerating their generative AI innovation and time to market, instead of spending time coordinating resource allocation and continuously replanning their generative AI development tasks.
In this post, we provide best practices to maximize the value of SageMaker HyperPod task governance and make the administration and data science experiences seamless. We also discuss common governance scenarios when administering and running generative AI development tasks.
Prerequisites
To get started with SageMaker HyperPod task governance on an existing SageMaker HyperPod cluster orchestrated by Amazon EKS, make sure you uninstall any existing Kueue installations, and have a Kubernetes cluster running version 1.30+.
Administration experience
Administrators are the first persona interacting with SageMaker HyperPod task governance. They are responsible for managing the cluster compute allocation according to the organization’s priorities and goals.
Managing compute
The first step to managing capacity across teams is to set up compute allocations. When setting up a compute allocation, keep in mind the following considerations:
- What type of tasks does this team typically run?
- Does this team constantly run tasks and require reserved capacity?
- What is this team’s priority relative to other teams?
When setting up a compute allocation, an administrator sets the team’s fair-share weight, which provides relative prioritization comparative to other teams when vying for the same idle compute. Higher weight enables a team to access unutilized resources within shared capacity sooner. As a best practice, set the fair-share weight higher for teams that will require access to capacity sooner than other teams.
After the fair-share weight is set, the administrator then sets up the quota and borrowing strategy. Quota determines the allocation per instance type within the cluster’s instance groups. Borrowing strategy determines whether a team will share or reserve their allotted capacity. To enforce proper quota management, the total reserved quota should not surpass the cluster’s available capacity for that resource. For instance, if a cluster comprises 20 ml.c5.2xlarge instances, the cumulative quota assigned to teams should remain under 20.
If the compute allocations for teams allow for “Lend and Borrow” or “Lend,” the idle capacity is shared between these teams. For example, if Team A has a quota of 6 but is using only 2 for its tasks, and Team B has a quota of 5 and is using 4 for its tasks, and a task that is submitted to Team B requiring 4 resources, 3 will be borrowed from Team A based on its “Lend and Borrow” settings. If any team’s compute allocations setting is set to “Don’t Lend,” the team will not be able to borrow any additional capacity beyond its reserved capacity.
To maintain a pool or a set of resources that all teams can borrow from, users can set up a dedicated team with resources that bridge the gap between other teams’ allocations and the total cluster capacity. Make sure that this cumulative resource allocation includes the appropriate instance types and doesn’t exceed the total cluster capacity. To make sure that these resources can be shared among teams, enable the participating teams to have their compute allocations set to “Lend and Borrow” or “Lend” for this common pool of resources. In addition, every time new teams are introduced, or quota allocations are changed or there are any changes to the cluster capacity, revisit the quota allocations of all the teams, to make sure the cumulative quota remains at or below cluster capacity.
After compute allocations have been set, the administrator will also need to set a cluster policy, which is comprised of two components: task prioritization and idle compute allocation. Administrators will set up a task prioritization, which determines the priority level for tasks running in a cluster. Next, an administrator will set idle compute allocation setting to either “first come, first serve,” in which tasks are not prioritized, or “fair-share allocation,” in which idle compute is distributed to teams based on their fair-share weight.
Observability
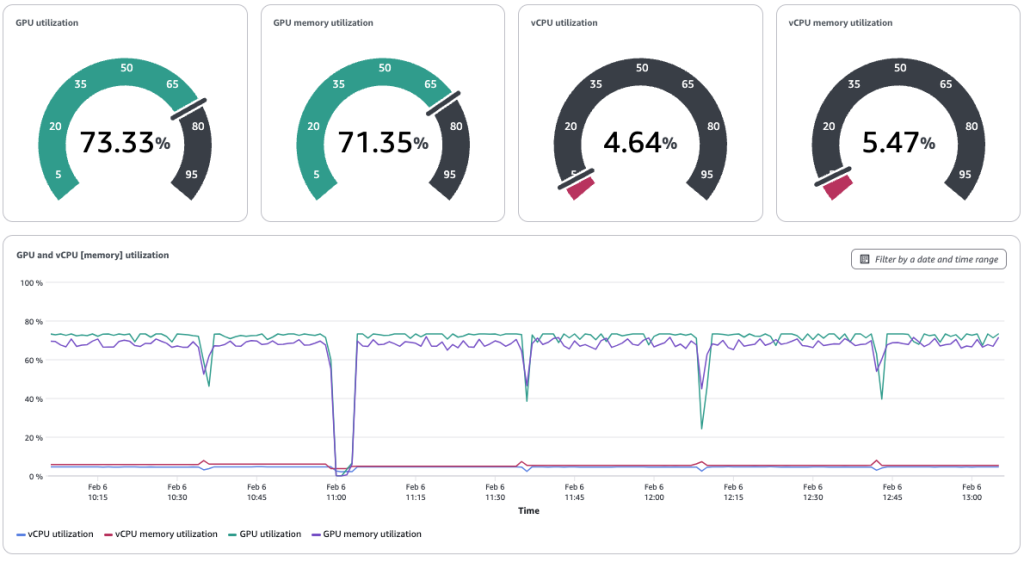
To get started with observability, install the Amazon CloudWatch Observability add-on with Kueue metrics selected. The SageMaker HyperPod task governance dashboard provides a single pane of glass view for cluster utilization across teams. At present, you can view tasks running for PyTorch, TensorFlow, and MPI tasks. Administrators can analyze the graphs within the dashboard to understand equity in resource sharing and utilization of resources.
To view utilization of resources, users can see the following dashboard showing GPU and vCPU utilization. These graphs inform administrators where teams can further maximize their GPU utilization. In this example, administrators observe GPU utilization around 52%

Administrators have a real-time view of utilization of instances as tasks are running or moved to pending during preemption. In this example, the ML engineering team is borrowing 5 GPUs for their training task


With SageMaker HyperPod, you can additionally set up observability tools of your choice. In our public workshop, we have steps on how to set up Amazon Managed Prometheus and Grafana dashboards.
Data scientist experience
Data scientists are the second persona interacting with SageMaker HyperPod clusters. Data scientists are responsible for the training, fine-tuning, and deployment of models on accelerated compute instances. It’s important to make sure data scientists have the necessary capacity and permissions when interacting with clusters of GPUs.
Access control
When working with SageMaker HyperPod task governance, data scientists will assume their specific role. Each data science team will need to have their own role and associated role-based access control (RBAC) on the cluster. RBAC prevents data scientists from submitting tasks to teams in which they do not belong. For more information about data science role permissions, see AWS Identity and Access Management for SageMaker HyperPod. As a best practice, administrators should limit data scientists according to the principle of least privilege. After roles and access entries are set up, data scientists can assume their associated AWS Identity and Access Management (IAM) role to submit tasks to corresponding namespaces. It’s important to note that users interacting with the console dashboard who didn’t create the associated EKS cluster will need to have their role added to the AccessEntry list for the EKS cluster.
Submitting tasks
There are two ways to submit tasks on Amazon EKS orchestrated SageMaker HyperPod clusters: kubectl and the SageMaker HyperPod CLI. With both options, data scientists will need to reference their team’s namespace and task priority class in the task configuration file in order to use their allocated quota with appropriate prioritization. If the user doesn’t a specify priority class, then SageMaker HyperPod task governance will automatically assume the lowest priority.
In the following code snippet, we show the labels required in a kubectl manifest file for the researchers namespace with inference priority. Priority classes will have -priority appended to the name set in the cluster policy. For further guidance on submitting tasks to SageMaker HyperPod task governance, follow the documentation here.
metadata:
name: job-name
namespace: hyperpod-ns-researchers
labels:
kueue.x-k8s.io/queue-name: hyperpod-ns-researchers-localqueue
kueue.x-k8s.io/priority-class: inference-priorityHyperPod CLI
The HyperPod CLI was created to abstract the complexities of working with kubectl and enable developers using SageMaker HyperPod to iterate faster with custom commands. HyperPod CLI v2.0.0 introduces a new default scheduler type with autofill commands, auto discovery of namespaces, improved cluster and task management features, and enhanced visibility into task priorities and accelerator quota allocations. Data scientists can use the new HyperPod CLI to quickly submit tasks, iterate, and experiment in their generative AI development lifecycle.
Sample commands
The following is a short reference guide for helpful commands when interacting with SageMaker HyperPod task governance:
- Describing cluster policy with the AWS CLI – This AWS Command Line Interface (AWS CLI) command is useful to view the cluster policy settings for your cluster.
- List compute quota allocations with the AWS CLI – This AWS CLI command is useful to view the different teams and set up task governance and their respective quota allocation settings.
- HyperPod CLI – The HyperPod CLI abstracts common kubectl commands used to interact with SageMaker HyperPod clusters such as submitting, listing, and cancelling tasks. Refer to the for a full list of commands.
- kubectl – You can also use kubectl to interact with task governance with the following example commands:
kubectl get pytorchjobs -n hyperpod-ns-<team-name>This command shows you the PyTorch tasks running in the specified team namespace.kubectl get workloads -n hyperpod-ns-<team-name>/kubectl describe workload <workload-name> -n hyperpod-ns-<team-name>– These commands show the workloads running in your cluster per namespace and provide detailed reasonings on Kueue Admission. You can use these commands to answer questions such as “Why was my task preempted?” or “Why did my task get admitted?”
Common scenarios
SageMaker HyperPod task governance enables allocating compute quota to teams, increasing utilization of compute resources, reducing costs, and accelerating waiting tasks by priority and in turn accelerating time to market. To relate these value propositions to real work scenarios, we will talk about a enterprise and a startup situation.
Enterprises have different teams working towards various business goals, each with budgets that limit their compute access. To maximize resource utilization within budget constraints, SageMaker HyperPod task governance allows enterprises to allocate compute quotas to teams for artificial intelligence and machine learning (AI/ML) tasks. When teams use up their allocation, they can access idle compute from other teams to accelerate waiting tasks, providing optimal resource utilization across the organization.
Startups aim to maximize compute resource utilization while achieving timely allocation for high-priority tasks. SageMaker HyperPod task governance’s prioritization feature allows you to assign priorities to different task types, such as prioritizing inference over training. This makes sure that high-priority tasks receive necessary compute resources before lower-priority ones, optimizing overall resource allocation.
Now we will walk you through two common scenarios for users interacting with SageMaker HyperPod task governance.
Scenario 1: Enterprise
In the first scenario, we have an enterprise company who wants to manage compute allocations to optimize for cost. This company has five teams sharing 80 GPUs, with the following configuration:
- Team 1 – Compute allocation: 20; Strategy: Don’t Lend
- Team 2 – Compute allocation: 20; Strategy: Don’t Lend
- Team 3 – Compute allocation: 5; Strategy: Lend & Borrow at 150%; Fair-share weight: 100
- Team 4 – Compute allocation: 10; Strategy: Lend & Borrow at 100%; Fair-share weight: 75
- Team 5 – Compute allocation: 25; Strategy: Lend & Borrow at 50%; Fair-share weight: 50
This sample configuration reserves capacity to teams that will be constantly using instances for high-priority tasks. In addition, a few teams have the option to lend and borrow idle compute from other teams—this improves cost optimization by reserving capacity as needed and allowing non-consistent workloads to run using available idle compute with prioritization.
Scenario 2: Startup
In the second scenario, we have a startup customer who wants to provide equitable compute allocation for members of their engineering and research teams. This company has three teams sharing 15 GPUs:
- Team 1 (ML engineering) – Compute allocation: 6; Strategy: Lend & Borrow at 50%; Fair-share weight: 100
- Team 2 (Researchers) – Compute allocation: 5; Strategy: Lend & Borrow at 50%; Fair-share weight: 100
- Team 3 (Real-time chatbot) – Compute allocation: 4; Strategy: Don’t Lend; Fair-share weight: 100
This sample configuration promotes equitable compute allocation across the company because all teams have the same fair-share weight and are able to preempt tasks with lower priority.

Conclusion
In this post, we discussed best practices for efficient use of SageMaker HyperPod task governance. We also provided certain patterns that you can adopt while administering generative AI tasks, whether you are aiming to optimize for cost or optimize for equitable compute allocation. To get started with SageMaker HyperPod task governance, refer to the Amazon EKS Support in Amazon SageMaker HyperPod workshop and SageMaker HyperPod task governance.
About the Author
 Nisha Nadkarni is a Senior GenAI Specialist Solutions Architect at AWS, where she guides companies through best practices when deploying large scale distributed training and inference on AWS. Prior to her current role, she spent several years at AWS focused on helping emerging GenAI startups develop models from ideation to production.
Nisha Nadkarni is a Senior GenAI Specialist Solutions Architect at AWS, where she guides companies through best practices when deploying large scale distributed training and inference on AWS. Prior to her current role, she spent several years at AWS focused on helping emerging GenAI startups develop models from ideation to production.
 Chaitanya Hazarey leads software development for SageMaker HyperPod task governance at Amazon, bringing extensive expertise in full-stack engineering, ML/AI, and data science. As a passionate advocate for responsible AI development, he combines technical leadership with a deep commitment to advancing AI capabilities while maintaining ethical considerations. His comprehensive understanding of modern product development drives innovation in machine learning infrastructure.
Chaitanya Hazarey leads software development for SageMaker HyperPod task governance at Amazon, bringing extensive expertise in full-stack engineering, ML/AI, and data science. As a passionate advocate for responsible AI development, he combines technical leadership with a deep commitment to advancing AI capabilities while maintaining ethical considerations. His comprehensive understanding of modern product development drives innovation in machine learning infrastructure.
 Kareem Syed-Mohammed is a Product Manager at AWS. He is focused on compute optimization and cost governance. Prior to this, at Amazon QuickSight, he led embedded analytics, and developer experience. In addition to QuickSight, he has been with AWS Marketplace and Amazon retail as a Product Manager. Kareem started his career as a developer for call center technologies, Local Expert and Ads for Expedia, and management consultant at McKinsey.
Kareem Syed-Mohammed is a Product Manager at AWS. He is focused on compute optimization and cost governance. Prior to this, at Amazon QuickSight, he led embedded analytics, and developer experience. In addition to QuickSight, he has been with AWS Marketplace and Amazon retail as a Product Manager. Kareem started his career as a developer for call center technologies, Local Expert and Ads for Expedia, and management consultant at McKinsey.
Author: Nisha Nadkarni