

Boost your AI with Azure’s new Phi model, streamlined RAG, and custom generative AI models

As developers continue to develop and deploy AI applications at scale across organizations, Azure is committed to delivering unprecedented choice in models as well as a flexible and comprehensive toolchain to handle the unique, complex and diverse needs of modern enterprises… This powerful combina…
As developers continue to develop and deploy AI applications at scale across organizations, Azure is committed to delivering unprecedented choice in models as well as a flexible and comprehensive toolchain to handle the unique, complex and diverse needs of modern enterprises. This powerful combination of the latest models and cutting-edge tooling empowers developers to create highly-customized solutions grounded in their organization’s data. That’s why we are excited to announce several updates to help developers quickly create AI solutions with greater choice and flexibility leveraging the Azure AI toolchain:
- Improvements to the Phi family of models, including a new Mixture of Experts (MoE) model and 20+ languages.
- AI21 Jamba 1.5 Large and Jamba 1.5 on Azure AI models as a service.
- Integrated vectorization in Azure AI Search to create a streamlined retrieval augmented generation (RAG) pipeline with integrated data prep and embedding.
- Custom generative extraction models in Azure AI Document Intelligence, so you can now extract custom fields for unstructured documents with high accuracy.
- The general availability of Text to Speech (TTS) Avatar, a capability of Azure AI Speech service, which brings natural-sounding voices and photorealistic avatars to life, across diverse languages and voices, enhancing customer engagement and overall experience.
- The general availability of the VS Code extension for Azure Machine Learning.
- The general availability of Conversational PII Detection Service in Azure AI Language.
Use the Phi model family with more languages and higher throughput
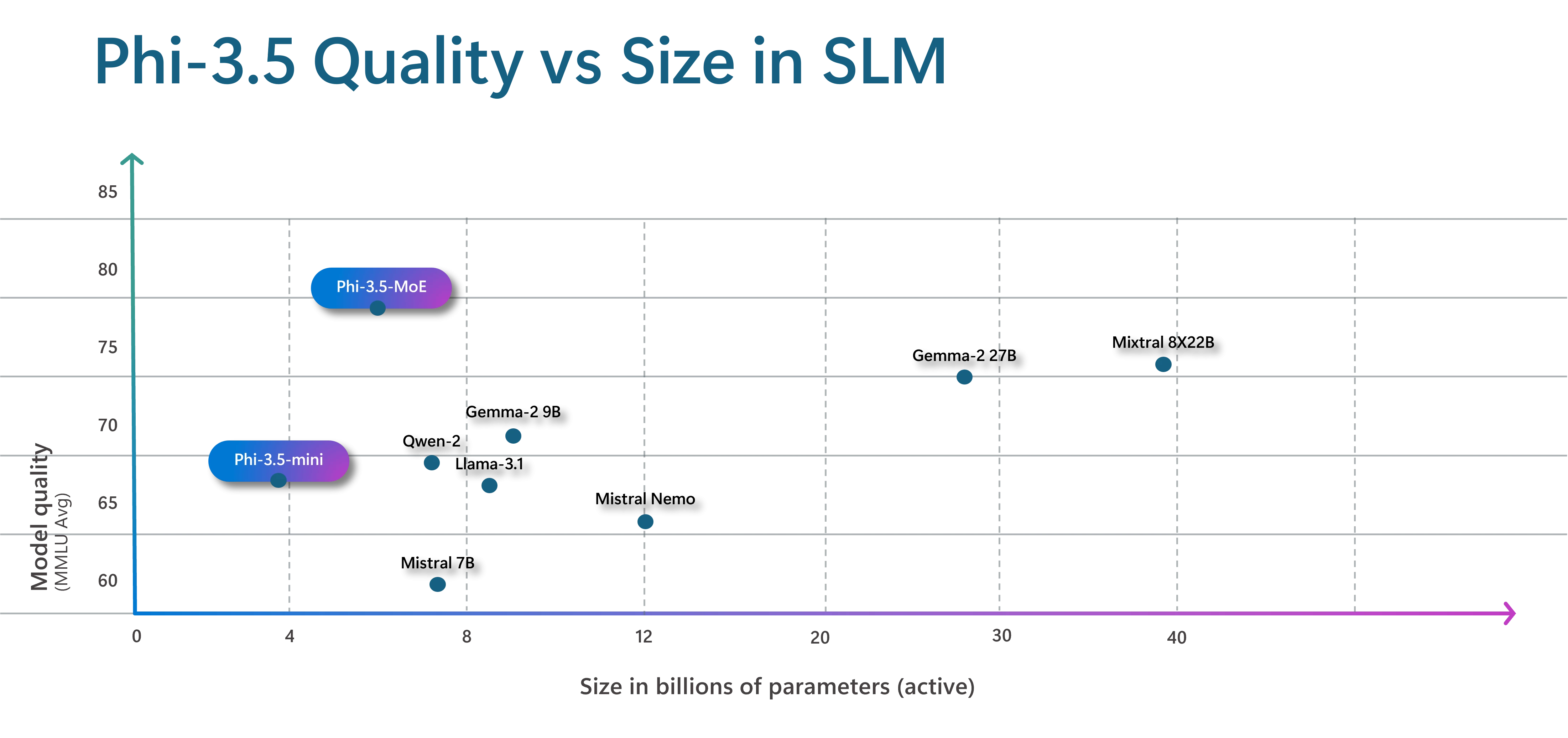
We are introducing a new model to the Phi family, Phi-3.5-MoE, a Mixture of Experts (MoE) model. This new model combines 16 smaller experts into one, which delivers improvements in model quality and lower latency. While the model is 42B parameters, since it is an MoE model it only uses 6.6B active parameters at a time, by being able to specialize a subset of the parameters (experts) during training, and then at runtime use the relevant experts for the task. This approach gives customers the benefit of the speed and computational efficiency of a small model with the domain knowledge and higher quality outputs of a larger model. Read more about how we used a Mixture of Experts architecture to improve Azure AI translation performance and quality.
We are also announcing a new mini model, Phi-3.5-mini. Both the new MoE model and the mini model are multi-lingual, supporting over 20 languages. The additional languages allow people to interact with the model in the language they are most comfortable using.
Even with new languages the new mini model, Phi-3.5-mini, is still a tiny 3.8B parameters.
Companies like CallMiner, a conversational intelligence leader, are selecting and using Phi models for their speed, accuracy, and security.
“CallMiner is constantly innovating and evolving our conversation intelligence platform, and we’re excited about the value Phi models are bringing to our GenAI architecture. As we evaluate different models, we’ve continued to prioritize accuracy, speed, and security... The small size of Phi models makes them incredibly fast, and fine tuning has allowed us to tailor to the specific use cases that matter most to our customers at high accuracy and across multiple languages. Further, the transparent training process for Phi models empowers us to limit bias and implement GenAI securely. We look forward to expanding our application of Phi models across our suite of products“—Bruce McMahon, CallMiner’s Chief Product Officer.
To make outputs more predictable and define the structure needed by an application, we are bringing Guidance to the Phi-3.5-mini serverless endpoint. Guidance is a proven open-source Python library (with 18K plus GitHub stars) that enables developers to express in a single API call the precise programmatic constraints the model must follow for structured output in JSON, Python, HTML, SQL, whatever the use case requires. With Guidance, you can eliminate expensive retries, and can, for example, constrain the model to select from pre-defined lists (e.g., medical codes), restrict outputs to direct quotes from provided context, or follow in any regex. Guidance steers the model token by token in the inference stack, producing higher quality outputs and reducing cost and latency by as much as 30-50% when utilizing for highly structured scenarios.
- Read more about the benefits of Guidance.
We are also updating the Phi vision model with multi-frame support. This means that Phi-3.5-vision (4.2B parameters) allows reasoning over multiple input images unlocking new scenarios like identifying differences between images.


At the core of our product strategy, Microsoft is dedicated to supporting the development of safe and responsible AI, and provides developers with a robust suite of tools and capabilities.
Developers working with Phi models can assess quality and safety using both built-in and custom metrics using Azure AI evaluations, informing necessary mitigations. Azure AI Content Safety provides built-in controls and guardrails, such as prompt shields and protected material detection. These capabilities can be applied across models, including Phi, using content filters or can be easily integrated into applications through a single API. Once in production, developers can monitor their application for quality and safety, adversarial prompt attacks, and data integrity, making timely interventions with the help of real-time alerts.
Introducing AI21 Jamba 1.5 Large and Jamba 1.5 on Azure AI models as a service
Furthering our goal to provide developers with access to the broadest selection of models, we are excited to also announce two new open models, Jamba 1.5 Large and Jamba 1.5, available in the Azure AI model catalog. These models use the Jamba architecture, blending Mamba, and Transformer layers for efficient long-context processing.
According to AI21, the Jamba 1.5 Large and Jamba 1.5 models are the most advanced in the Jamba series. These models utilize the Hybrid Mamba-Transformer architecture, which balances speed, memory, and quality by employing Mamba layers for short-range dependencies and Transformer layers for long-range dependencies. Consequently, this family of models excels in managing extended contexts ideal for industries including financial services, healthcare, and life sciences, as well as retail and CPG.
“We are excited to deepen our collaboration with Microsoft, bringing the cutting-edge innovations of the Jamba Model family to Azure AI users…As an advanced hybrid SSM-Transformer (Structured State Space Model-Transformer) set of foundation models, the Jamba model family democratizes access to efficiency, low latency, high quality, and long-context handling. These models empower enterprises with enhanced performance and seamless integration with the Azure AI platform”— Pankaj Dugar, Senior Vice President and General Manger of North America at AI21
- Learn more on the Jamba model family.
Simplify RAG for generative AI applications
We are streamlining RAG pipelines with integrated, end to end data preparation and embedding. Organizations often use RAG in generative AI applications to incorporate knowledge on private organization specific data, without having to retrain the model. With RAG, you can use strategies like vector and hybrid retrieval to surface relevant, informed information to a query, grounded on your data. However, to perform vector search, significant data preparation is required. Your app must ingest, parse, enrich, embed, and index data of various types, often living in multiple sources, just so that it can be used in your copilot.
Today we are announcing general availability of integrated vectorization in Azure AI Search. Integrated vectorization automates and streamlines these processes all into one flow. With automatic vector indexing and querying using integrated access to embedding models, your application unlocks the full potential of what your data offers.
In addition to improving developer productivity, integration vectorization enables organizations to offer turnkey RAG systems as solutions for new projects, so teams can quickly build an application specific to their datasets and need, without having to build a custom deployment each time.
Customers like SGS & Co, a global brand impact group, are streamlining their workflows with integrated vectorization.
“SGS AI Visual Search is a GenAI application built on Azure for our global production teams to more effectively find sourcing and research information pertinent to their project… The most significant advantage offered by SGS AI Visual Search is utilizing RAG, with Azure AI Search as the retrieval system, to accurately locate and retrieve relevant assets for project planning and production”—Laura Portelli, Product Manager, SGS & Co
- Learn more on vectorization.
Extract custom fields in Document Intelligence
You can now extract custom fields for unstructured documents with high accuracy by building and training a custom generative model within Document Intelligence. This new ability uses generative AI to extract user specified fields from documents across a wide variety of visual templates and document types. You can get started with as few as five training documents. While building a custom generative model, automatic labeling saves time and effort on manual annotation, results will display as grounded where applicable, and confidence scores are available to quickly filter high quality extracted data for downstream processing and lower manual review time.
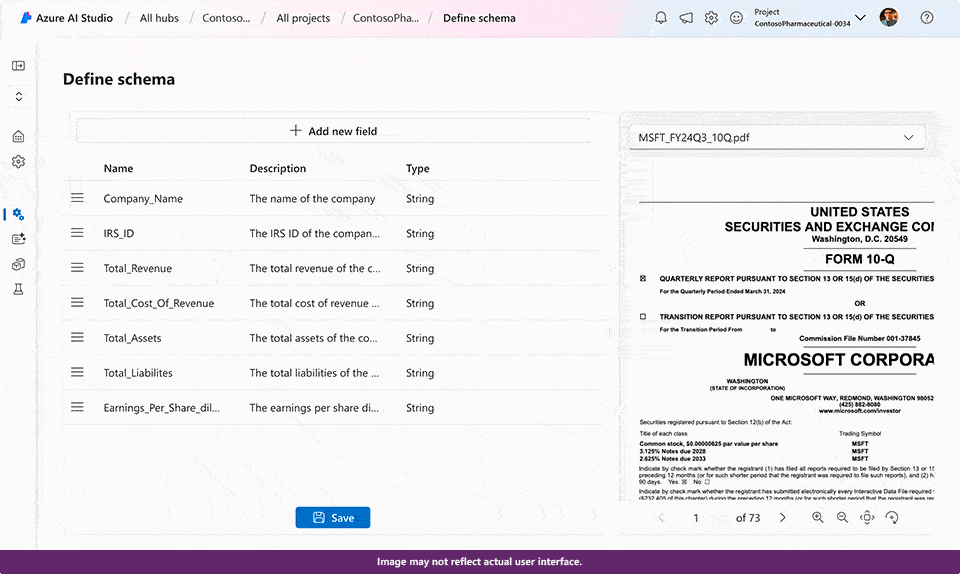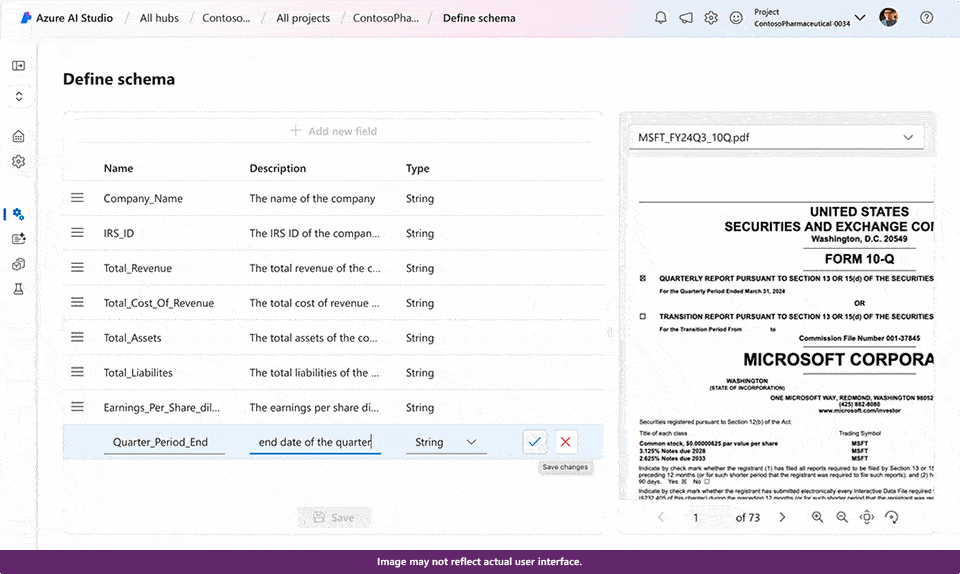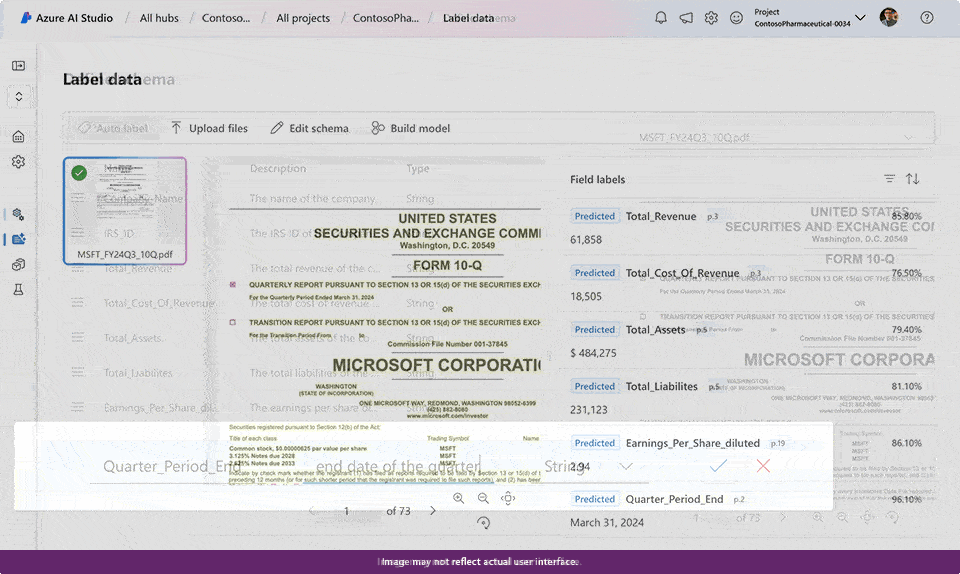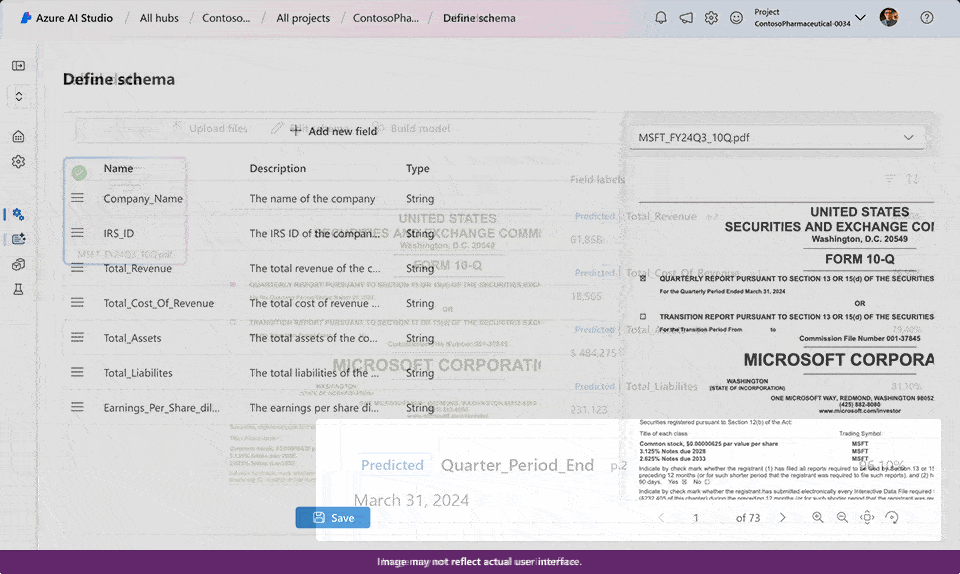
- Learn more on custom field extraction preview.
Create engaging experiences with prebuilt and custom avatars
Today we are excited to announce that Text to Speech (TTS) Avatar, a capability of Azure AI Speech service, is now generally available. This service brings natural-sounding voices and photorealistic avatars to life, across diverse languages and voices, enhancing customer engagement and overall experience. With TTS Avatar, developers can create personalized and engaging experiences for their customers and employees, while also improving efficiency and providing innovative solutions.
The TTS Avatar service provides developers with a variety of pre-built avatars, featuring a diverse portfolio of natural-sounding voices, as well as an option to create custom synthetic voices using Azure Custom Neural Voice. Additionally, the photorealistic avatars can be customized to match a company’s branding. For example, Fujifilm is using TTS Avatar with NURA, the world’s first AI-powered health screening center.
“Embracing the Azure TTS Avatar at NURA as our 24-hour AI assistant marks a pivotal step in healthcare innovation. At NURA, we envision a future where AI-powered assistants redefine customer interactions, brand management, and healthcare delivery. Working with Microsoft, we’re honored to pioneer the next generation of digital experiences, revolutionizing how businesses connect with customers and elevate brand experiences, paving the way for a new era of personalized care and engagement. Let’s bring more smiles together”—Dr. Kasim, Executive Director and Chief Operating Officer, Nura AI Health Screening
As we bring this technology to market, ensuring responsible use and development of AI remains our top priority. Custom Text to Speech Avatar is a limited access service in which we have integrated safety and security features. For example, the system embeds invisible watermarks in avatar outputs. These watermarks allow approved users to verify if a video has been created using Azure AI Speech’s avatar feature. Additionally, we provide guidelines for TTS avatar’s responsible use, including measures to promote transparency in user interactions, identify and mitigate potential bias or harmful synthetic content, and how to integrate with Azure AI Content Safety. In this transparency note, we describe the technology and capabilities for TTS Avatar, its approved use cases, considerations when choosing use cases, its limitations, fairness considerations and best practice for improving system performance. We also require all developers and content creators to apply for access and comply with our code of conduct when using TTS Avatar features including prebuilt and custom avatars.
- Learn more about Azure TTS Avatar.
Use Azure Machine Learning resources in VS Code
We’re thrilled to announce the general availability of the VS Code extension for Azure Machine Learning. The extension allows you to build, train, deploy, debug, and manage machine learning models with Azure Machine Learning directly from your favorite VS Code setup, whether on desktop or web. With features like VNET support, IntelliSense and integration with Azure Machine Learning CLI, the extension is now ready for production use. Read this tech community blog to learn more about the extension.
Customers like Fashable have put this into production.
“We have been using the VS Code extension for Azure Machine Learning since its preview release, and it has significantly streamlined our workflow… The ability to manage everything from building to deploying models directly within our preferred VS Code environment has been a game-changer. The seamless integration and robust features like interactive debugging and VNET support have enhanced our productivity and collaboration. We are thrilled about its general availability and look forward to leveraging its full potential in our AI projects.”—Ornaldo Ribas Fernandes, Co-founder and CEO, Fashable
Protect users’ privacy
Today we are excited to announce the general availability of Conversational PII Detection Service in Azure AI Language, enhancing Azure AI’s ability to identify and redact sensitive information in conversations, starting with English language. This service aims to improve data privacy and security for developers building generative AI apps for their enterprise. The Conversational PII redaction service expands upon the Text PII redaction service, supporting customers looking to identify, categorize, and redact sensitive information such as phone numbers and email addresses in unstructured text. This Conversational PII model is specialized for conversational style inputs, particularly those found in speech transcriptions from meetings and calls.
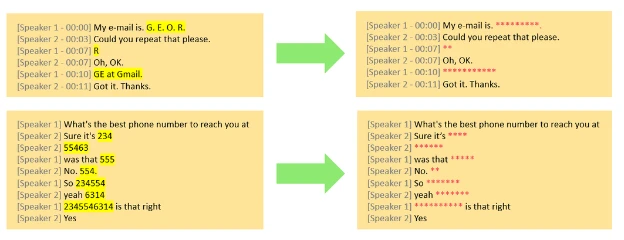
- Learn more on Conversational PII redaction service.
Self-serve your Azure OpenAI Service PTUs
We recently announced updates to Azure OpenAI Service, including the ability to manage your Azure OpenAI Service quota deployments without relying on support from your account team, allowing you to request Provisioned Throughput Units (PTUs) more flexibly and efficiently. We also released OpenAI’s latest model when they made it available on 8/7, which introduced Structured Outputs, like JSON Schemas, for the new GPT-4o and GPT-4o mini models. Structured outputs are particularly valuable for developers who need to validate and format AI outputs into structures like JSON Schemas.
- Read more about Structured Outputs for GPT-4o and GPT-4o mini models on the Azure Blog.
We continue to invest across the Azure AI stack to bring state of the art innovation to our customers so you can build, deploy, and scale your AI solutions safely and confidently. We cannot wait to see what you build next.
Stay up to date with more Azure AI news
- See the latest Azure OpenAI Service news.
- See the latest Azure AI news.
- Read more in our Azure AI services documentation.
- Read the latest AI and machine learning blogs.
The post Boost your AI with Azure’s new Phi model, streamlined RAG, and custom generative AI models appeared first on Microsoft Azure Blog.
Author: Eric Boyd