

Build a contextual text and image search engine for product recommendations using Amazon Bedrock and Amazon OpenSearch Serverless
In this post, we show how to build a contextual text and image search engine for product recommendations using the Amazon Titan Multimodal Embeddings model, available in Amazon Bedrock, with Amazon OpenSearch Serverless… A multimodal embeddings model is designed to learn joint representations o…
The rise of contextual and semantic search has made ecommerce and retail businesses search straightforward for its consumers. Search engines and recommendation systems powered by generative AI can improve the product search experience exponentially by understanding natural language queries and returning more accurate results. This enhances the overall user experience, helping customers find exactly what they’re looking for.
Amazon OpenSearch Service now supports the cosine similarity metric for k-NN indexes. Cosine similarity measures the cosine of the angle between two vectors, where a smaller cosine angle denotes a higher similarity between the vectors. With cosine similarity, you can measure the orientation between two vectors, which makes it a good choice for some specific semantic search applications.
In this post, we show how to build a contextual text and image search engine for product recommendations using the Amazon Titan Multimodal Embeddings model, available in Amazon Bedrock, with Amazon OpenSearch Serverless.
A multimodal embeddings model is designed to learn joint representations of different modalities like text, images, and audio. By training on large-scale datasets containing images and their corresponding captions, a multimodal embeddings model learns to embed images and texts into a shared latent space. The following is a high-level overview of how it works conceptually:
- Separate encoders – These models have separate encoders for each modality—a text encoder for text (for example, BERT or RoBERTa), image encoder for images (for example, CNN for images), and audio encoders for audio (for example, models like Wav2Vec). Each encoder generates embeddings capturing semantic features of their respective modalities
- Modality fusion – The embeddings from the uni-modal encoders are combined using additional neural network layers. The goal is to learn interactions and correlations between the modalities. Common fusion approaches include concatenation, element-wise operations, pooling, and attention mechanisms.
- Shared representation space – The fusion layers help project the individual modalities into a shared representation space. By training on multimodal datasets, the model learns a common embedding space where embeddings from each modality that represent the same underlying semantic content are closer together.
- Downstream tasks – The joint multimodal embeddings generated can then be used for various downstream tasks like multimodal retrieval, classification, or translation. The model uses correlations across modalities to improve performance on these tasks compared to individual modal embeddings. The key advantage is the ability to understand interactions and semantics between modalities like text, images, and audio through joint modeling.
Solution overview
The solution provides an implementation for building a large language model (LLM) powered search engine prototype to retrieve and recommend products based on text or image queries. We detail the steps to use an Amazon Titan Multimodal Embeddings model to encode images and text into embeddings, ingest embeddings into an OpenSearch Service index, and query the index using the OpenSearch Service k-nearest neighbors (k-NN) functionality.
This solution includes the following components:
- Amazon Titan Multimodal Embeddings model – This foundation model (FM) generates embeddings of the product images used in this post. With Amazon Titan Multimodal Embeddings, you can generate embeddings for your content and store them in a vector database. When an end-user submits any combination of text and image as a search query, the model generates embeddings for the search query and matches them to the stored embeddings to provide relevant search and recommendations results to end-users. You can further customize the model to enhance its understanding of your unique content and provide more meaningful results using image-text pairs for fine-tuning. By default, the model generates vectors (embeddings) of 1,024 dimensions, and is accessed via Amazon Bedrock. You can also generate smaller dimensions to optimize for speed and performance
- Amazon OpenSearch Serverless – It is an on-demand serverless configuration for OpenSearch Service. We use Amazon OpenSearch Serverless as a vector database for storing embeddings generated by the Amazon Titan Multimodal Embeddings model. An index created in the Amazon OpenSearch Serverless collection serves as the vector store for our Retrieval Augmented Generation (RAG) solution.
- Amazon SageMaker Studio – It is an integrated development environment (IDE) for machine learning (ML). ML practitioners can perform all ML development steps—from preparing your data to building, training, and deploying ML models.
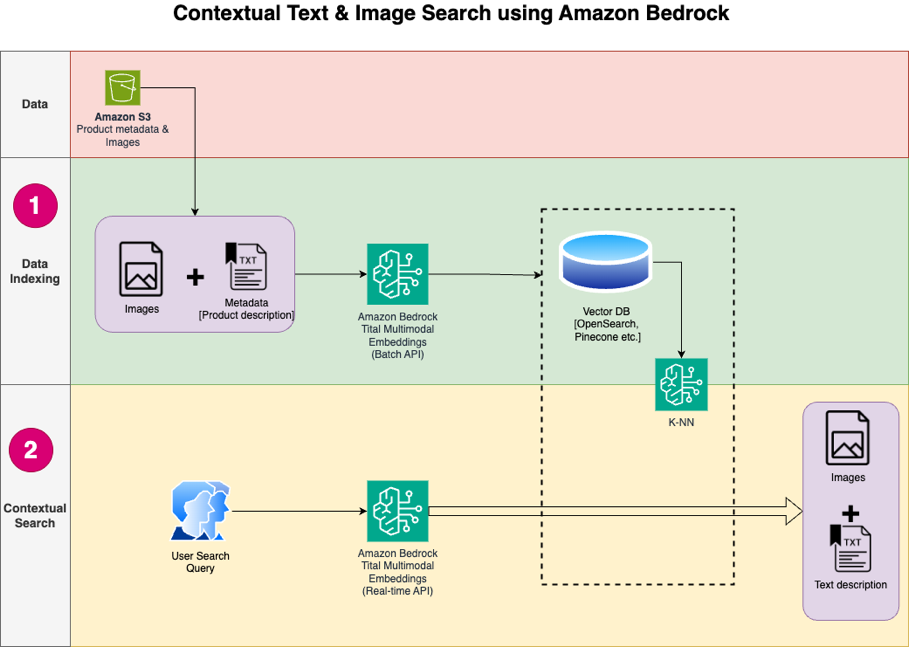
The solution design consists of two parts: data indexing and contextual search. During data indexing, you process the product images to generate embeddings for these images and then populate the vector data store. These steps are completed prior to the user interaction steps.
In the contextual search phase, a search query (text or image) from the user is converted into embeddings and a similarity search is run on the vector database to find the similar product images based on similarity search. You then display the top similar results. All the code for this post is available in the GitHub repo.
The following diagram illustrates the solution architecture.

The following are the solution workflow steps:
- Download the product description text and images from the public Amazon Simple Storage Service (Amazon S3) bucket.
- Review and prepare the dataset.
- Generate embeddings for the product images using the Amazon Titan Multimodal Embeddings model (amazon.titan-embed-image-v1). If you have a huge number of images and descriptions, you can optionally use the Batch inference for Amazon Bedrock.
- Store embeddings into the Amazon OpenSearch Serverless as the search engine.
- Finally, fetch the user query in natural language, convert it into embeddings using the Amazon Titan Multimodal Embeddings model, and perform a k-NN search to get the relevant search results.
We use SageMaker Studio (not shown in the diagram) as the IDE to develop the solution.
These steps are discussed in detail in the following sections. We also include screenshots and details of the output.
Prerequisites
To implement the solution provided in this post, you should have the following:
- An AWS account and familiarity with FMs, Amazon Bedrock, Amazon SageMaker, and OpenSearch Service.
- The Amazon Titan Multimodal Embeddings model enabled in Amazon Bedrock. You can confirm it’s enabled on the Model access page of the Amazon Bedrock console. If Amazon Titan Multimodal Embeddings is enabled, the access status will show as Access granted, as shown in the following screenshot.

If the model is not available, enable access to the model by choosing Manage model access, selecting Amazon Titan Multimodal Embeddings G1, and choosing Request model access. The model is enabled for use immediately.

- You also need a SageMaker Studio domain. If you don’t have a SageMaker Studio domain already configured, refer to Amazon SageMaker simplifies the Amazon SageMaker Studio setup for individual users for steps to create one.
Set up the solution
When the prerequisite steps are complete, you’re ready to set up the solution:
- In your AWS account, open the SageMaker console and choose Studio in the navigation pane.
- Choose your domain and user profile, then choose Open Studio.
Your domain and user profile name may be different.

- Choose System terminal under Utilities and files.
- Run the following command to clone the GitHub repo to the SageMaker Studio instance:
- Navigate to the
multimodal/Titan/titan-multimodal-embeddings/amazon-bedrock-multimodal-oss-searchengine-e2efolder. - Open the
titan_mm_embed_search_blog.ipynbnotebook.
Run the solution
Open the file titan_mm_embed_search_blog.ipynb and use the Data Science Python 3 kernel. On the Run menu, choose Run All Cells to run the code in this notebook.
This notebook performs the following steps:
- Install the packages and libraries required for this solution.
- Load the publicly available Amazon Berkeley Objects Dataset and metadata in a pandas data frame.
The dataset is a collection of 147,702 product listings with multilingual metadata and 398,212 unique catalogue images. For this post, you only use the item images and item names in US English. You use approximately 1,600 products.

- Generate embeddings for the item images using the Amazon Titan Multimodal Embeddings model using the
get_titan_multomodal_embedding()function. For the sake of abstraction, we have defined all important functions used in this notebook in theutils.pyfile.

Next, you create and set up an Amazon OpenSearch Serverless vector store (collection and index).
- Before you create the new vector search collection and index, you must first create three associated OpenSearch Service policies: the encryption security policy, network security policy, and data access policy.


- Finally, ingest the image embedding into the vector index.

Now you can perform a real-time multimodal search.
Run a contextual search
In this section, we show the results of contextual search based on a text or image query.
First, let’s perform an image search based on text input. In the following example, we use the text input “drinkware glass” and send it to the search engine to find similar items.

The following screenshot shows the results.

Now let’s look at the results based on a simple image. The input image gets converted into vector embeddings and, based on the similarity search, the model returns the result.
You can use any image, but for the following example, we use a random image from the dataset based on item ID (for example, item_id = “B07JCDQWM6”), and then send this image to the search engine to find similar items.

The following screenshot shows the results.

Clean up
To avoid incurring future charges, delete the resources used in this solution. You can do this by running the cleanup section of the notebook.

Conclusion
This post presented a walkthrough of using the Amazon Titan Multimodal Embeddings model in Amazon Bedrock to build powerful contextual search applications. In particular, we demonstrated an example of a product listing search application. We saw how the embeddings model enables efficient and accurate discovery of information from images and textual data, thereby enhancing the user experience while searching for the relevant items.
Amazon Titan Multimodal Embeddings helps you power more accurate and contextually relevant multimodal search, recommendation, and personalization experiences for end-users. For example, a stock photography company with hundreds of millions of images can use the model to power its search functionality, so users can search for images using a phrase, image, or a combination of image and text.
The Amazon Titan Multimodal Embeddings model in Amazon Bedrock is now available in the US East (N. Virginia) and US West (Oregon) AWS Regions. To learn more, refer to Amazon Titan Image Generator, Multimodal Embeddings, and Text models are now available in Amazon Bedrock, the Amazon Titan product page, and the Amazon Bedrock User Guide. To get started with Amazon Titan Multimodal Embeddings in Amazon Bedrock, visit the Amazon Bedrock console.
Start building with the Amazon Titan Multimodal Embeddings model in Amazon Bedrock today.
About the Authors
 Sandeep Singh is a Senior Generative AI Data Scientist at Amazon Web Services, helping businesses innovate with generative AI. He specializes in Generative AI, Artificial Intelligence, Machine Learning, and System Design. He is passionate about developing state-of-the-art AI/ML-powered solutions to solve complex business problems for diverse industries, optimizing efficiency and scalability.
Sandeep Singh is a Senior Generative AI Data Scientist at Amazon Web Services, helping businesses innovate with generative AI. He specializes in Generative AI, Artificial Intelligence, Machine Learning, and System Design. He is passionate about developing state-of-the-art AI/ML-powered solutions to solve complex business problems for diverse industries, optimizing efficiency and scalability.
 Mani Khanuja is a Tech Lead – Generative AI Specialists, author of the book Applied Machine Learning and High Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach.
Mani Khanuja is a Tech Lead – Generative AI Specialists, author of the book Applied Machine Learning and High Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach.
 Rupinder Grewal is a Senior AI/ML Specialist Solutions Architect with AWS. He currently focuses on serving of models and MLOps on Amazon SageMaker. Prior to this role, he worked as a Machine Learning Engineer building and hosting models. Outside of work, he enjoys playing tennis and biking on mountain trails.
Rupinder Grewal is a Senior AI/ML Specialist Solutions Architect with AWS. He currently focuses on serving of models and MLOps on Amazon SageMaker. Prior to this role, he worked as a Machine Learning Engineer building and hosting models. Outside of work, he enjoys playing tennis and biking on mountain trails.
Author: Sandeep Singh