

Build a multi-tenant generative AI environment for your enterprise on AWS
To move faster, enterprises need robust operating models and a holistic approach that simplifies the generative AI lifecycle… In the first part of the series, we showed how AI administrators can build a generative AI software as a service (SaaS) gateway to provide access to foundation models (FMs…
While organizations continue to discover the powerful applications of generative AI, adoption is often slowed down by team silos and bespoke workflows. To move faster, enterprises need robust operating models and a holistic approach that simplifies the generative AI lifecycle. In the first part of the series, we showed how AI administrators can build a generative AI software as a service (SaaS) gateway to provide access to foundation models (FMs) on Amazon Bedrock to different lines of business (LOBs). In this second part, we expand the solution and show to further accelerate innovation by centralizing common Generative AI components. We also dive deeper into access patterns, governance, responsible AI, observability, and common solution designs like Retrieval Augmented Generation.
Our solution uses Amazon Bedrock, a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies such as AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API via a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. It also uses a number of other AWS services such as Amazon API Gateway, AWS Lambda, and Amazon SageMaker.
Architecting a multi-tenant generative AI environment on AWS
A multi-tenant, generative AI solution for your enterprise needs to address the unique requirements of generative AI workloads and responsible AI governance while maintaining adherence to corporate policies, tenant and data isolation, access management, and cost control. As a result, building such a solution is often a significant undertaking for IT teams.
In this post, we discuss the key design considerations and present a reference architecture that:
- Accelerates generative AI adoption through quick experimentation, unified model access, and reusability of common generative AI components
- Offers tenants the flexibility to choose the optimal design and technical implementation for their use case
- Implements centralized governance, guardrails, and controls
- Allows for tracking and auditing model usage and cost per tenant, line of business (LOB), or FM provider
Solution overview
The proposed solution consists of two parts:
- The generative AI gateway and
- The tenant
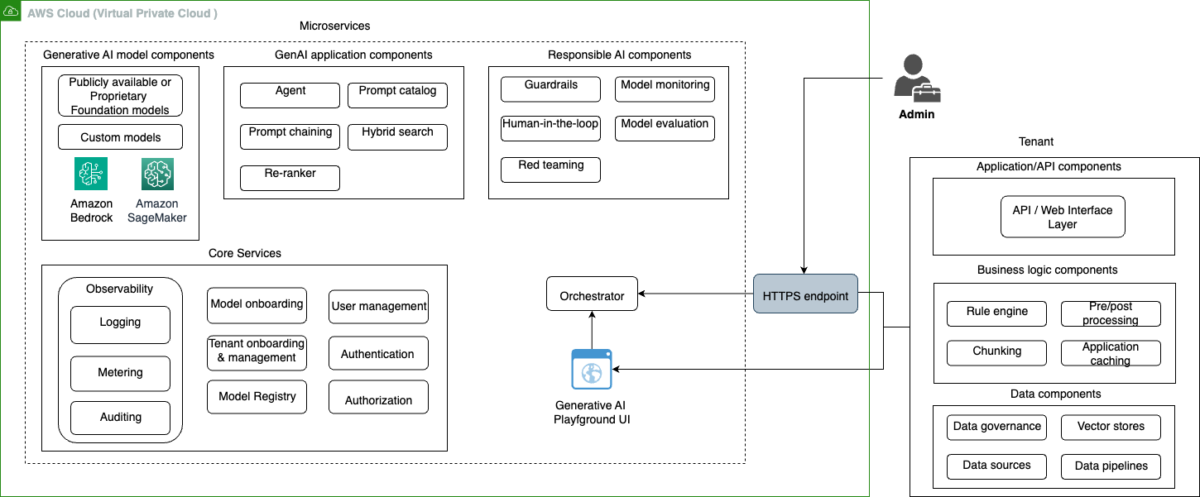
The following diagram illustrates an overview of the solution.

Generative AI gateway
Shared components lie in this part. Shared components refer to the functionality and features shared by all tenants. Each component in the previous diagram can be implemented as a microservice and is multi-tenant in nature, meaning it stores details related to each tenant, uniquely represented by a tenant_id. Some components are categorized in groups based on the type of functionality they exhibit.
The standalone components are:
- The HTTPS endpoint is the entry point to the gateway. Interactions with the shared services goes through this HTTPS endpoint. This is the only entry point of the solution.
- The orchestrator is responsible for receiving the requests forwarded by the HTTPS endpoint and invoking relevant microservices, based on the task at hand. This in itself is a microservice, inspired the Orchestrator Saga pattern in microservices.
- The generative AI playground is a UI provided to tenants where they can run their one-time experiments, chat with several FMs, and manually test capabilities such as guardrails or model evaluation for exploration purposes.
The component groups are as follows.
- Core services is primarily targeted to the environment administrator. It contains services used to onboard, manage, and operate the environment, for example, to onboard and off-board tenants, users, and models, assign quotas to different tenants, and authentication and authorization microservices. It also contains observability components for cost tracking, budgeting, auditing, logging, etc.
- Generative AI model components contain microservices for foundation and custom model invocation operations. These microservices abstract communication to FMs served through Amazon Bedrock, Amazon SageMaker, or a third-party model provider.
- Generative AI components provide functionalities needed to build a generative AI application. Capabilities such as prompt caching, prompt chaining, agents, or hybrid search are part of these microservices.
- Responsible AI components promote the safe and responsible development of AI across tenants. They include features such as guardrails, red teaming, and model evaluation.
Tenant
This part represents the tenants using the AI gateway capabilities. Each tenant has different requirements and needs and their own application stack. They can integrate their application with the generative AI gateway to embed generative AI capabilities in their application. The environment Admin has access to the generative AI gateway and interacts with the core services.
Solution walkthrough
The following sections examine each part of the solution in more depth.
HTTPS endpoint
This serves as the entry point for the generative AI gateway. Incoming requests to the gateway go through this point. There are different approaches you can follow when designing the endpoint:
- REST API endpoint – You can set up a REST API endpoint using services such as API Gateway where you can apply all authentication, authorization, and throttling mechanisms. API Gateway is serverless and hence automatically scales with traffic.
- WebSockets – For long-running connections, you can use WebSockets instead of a REST interface. This implementation overcomes timeout limitations in synchronous REST requests. A WebSockets implementation keeps the connection open for multiturn or long-running conversations. API Gateway also provides a WebSocket API.
- Load balancer – Another option is to use a load balancer that exposes an HTTPS endpoint and routes the request to the orchestrator. You can use AWS services such as Application Load Balancer to implement this approach. The advantage of using Application Load Balancer is that it can seamlessly route the request to virtually any managed, serverless or self-hosted component and can also scale well.
Tenants and access patterns
Tenants, such as LOBs or teams, use the shared services to access APIs and integrate generative AI capabilities into their applications. They can also use the playground UI to assess the suitability of generative AI for their specific use case before diving into full-fledged application development.
Here you also have the data sources, processing pipelines, vector stores, and data governance mechanisms that allow tenants to securely discover, access, andthe data they need for their specific use case. At this point, you need to consider the use case and data isolation requirements. Some applications may need to access data with personal identifiable information (PII) while others may rely on noncritical data. You also need to consider the operational characteristics and noisy neighbor risks.
Take Retrieval Augmented Generation (RAG) as an example. Depending on the use case and data isolation requirements, tenants can have a pooled knowledge base or a siloed one and implement item-level isolation or resource level isolation for the data respectively. Tenants can select data from the data sources they have access to, choose the right chunking strategy for their application, use the shared generative AI FMs for converting the data into embeddings, and store the embeddings in their vector store.
To answer user questions in real time, tenants can implement caching mechanisms to reduce latency and costs for frequent queries. Additionally, they can implement custom logic to retrieve information about previous sessions, the state of the interaction, and information specific to the end user. To generate the final response, they can again access the models and re-ranking functionality available through the gateway.
The following diagram illustrates a potential implementation of a chat-based assistant application with this approach. The tenant application uses FMs available through the generative AI gateway and its own vector store to provide personalized, relevant responses to the end user.

Shared services
The following section describes the shared services groups.
Model components
The goal of this component group is to expose a unified API to tenants for accessing underlying models irrespective of where these are hosted. It abstracts invocation details and accelerates application development. It consists of one or more components depending on the number of FM providers and number and types of custom models used. These components are illustrated in the following diagram.

In terms of how to offer FMs to your tenants, with AWS you have several options:
- Amazon Bedrock is a fully managed service that offers a choice of FMs from AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API. It’s serverless so you don’t have to manage the infrastructure. You can also bring your own customized models and deploy them to Amazon Bedrock for supported architectures.
- SageMaker JumpStart is a machine learning (ML) hub that provides a wide range of publicly available and proprietary FMs from providers such as AI21 Labs, Cohere, Hugging Face, Meta, and Stability AI, which you can deploy to SageMaker endpoints in your own AWS account.
- SageMaker offers SageMaker endpoints for inference where you can deploy a publicly available model, such as models from HuggingFace, or your own model.
- You can also deploy models on AWS compute using container services such as Amazon Elastic Kubernetes Service (Amazon EKS) or self-managed approaches.
With AWS PrivateLink, you can create a private connection between your virtual private cloud (VPC) and Amazon Bedrock and SageMaker endpoints.
Generative AI application components
This group contains components linked to the unique requirements of generative AI applications. They’re illustrated in the following figure.

- Prompt catalog – Crafting effective prompts is important for guiding large language models (LLMs) to generate the desired outputs. Prompt engineering is typically an iterative process, and teams experiment with different techniques and prompt structures until they reach their target outcomes. Having a centralized prompt catalog is essential for storing, versioning, tracking, and sharing prompts. It also lets you automate your evaluation process in your pre-production environments. When a new prompt is added to the catalog, it triggers the evaluation pipeline. If it leads to better performance, your existing default prompt in the application is overridden with the new one. When you use Amazon Bedrock, Amazon Bedrock Prompt Management allows you to create and save your own prompts so you can save time by applying the same prompt to different workflows. Alternatively, you can use Amazon DynamoDB, a serverless, fully managed NoSQL database, to store your prompts.
- Prompt chaining – Generative AI developers often use prompt chaining techniques to break complex tasks into subtasks before sending them to an LLM. A centralized service that exposes APIs for common prompt-chaining architectures to your tenants can accelerate development. You can use AWS Step Functions to orchestrate the chaining workflows and Amazon EventBridge to listen to task completion events and trigger the next step. Refer to Perform AI prompt-chaining with Amazon Bedrock for more details.
- Agent – Tenants also often employ autonomous agents to complete complex tasks. Such agents orchestrate interactions between models, data sources, APIs, and applications. The agents component allows them to create, manage, access, and share agent implementations. On AWS, you can use the fully managed Amazon Bedrock Agents or tools of your choice such as LangChain agents or LlamaIndex agents.
- Re-ranker – In the RAG design, a search in internal company data often returns multiple candidate outputs. A re-ranker, such as a Cohere Rerank 2 model, helps identify the best candidates based on predefined criteria. If your tenants prefer to use the capabilities of managed services such as Amazon OpenSearch Service or Amazon Kendra, this component isn’t needed.
- Hybrid search – In RAG, you may also optionally want to implement and expose different templates for performing hybrid search that help improve the quality of the retrieved documents. This logic sits in a hybrid search component. If you use managed services such as Amazon OpenSearch Service, this component is also not required.
Responsible AI components
This group contains key components for Responsible AI, as shown in the following diagram.

- Guardrails – Guardrails help you implement safeguards in addition to the FM built-in protections. They can be applied as generic defaults for users in your organization or can be specific to each use case. You can use Amazon Bedrock Guardrails to implement such safeguards based on your application requirements and responsible AI policies. With Amazon Bedrock Guardrails, you can block undesirable topics, filter harmful content, and redact or block sensitive information such as PII and custom regular expression to protect privacy. Additionally, contextual grounding checks can help detect hallucinations in model responses based on a reference source and a user query. The ApplyGuardrail API can evaluate input prompts and model responses for FMs on Amazon Bedrock, custom FMs, and third-party FMs, enabling centralized governance across your generative AI applications.
- Red teaming – Red teaming helps reveal model limitations that can cause bad user experiences or enable malicious intentions. LLMs can be vulnerable to security and privacy attacks such as backdoor attacks, poisoning attacks, prompt injection, jailbreaking, PII leakage attacks, membership inference attacks or gradient leakage attacks. You can set up a test application and a red team with your own employees or automate it against a known set of vulnerabilities. For example, you can test the application with known jailbreaking datasets such as these You can use the results to tailor your Amazon Bedrock Guardrails to block undesirable topics, filter harmful content, and redact or block sensitive information.
- Human in the loop – The human-in-the-loop approach is the process of collecting human inputs across the ML lifecycle to improve the accuracy and relevancy of models. Humans can perform a variety of tasks, from data generation and annotation to model review, customization, and evaluation. With SageMaker Ground Truth, you have a self-service offering and an AWS managed In the self-service offering, your data annotators, content creators, and prompt engineers (in-house, vendor-managed, or using the public crowd) can use the low-code UI to accelerate human-in-the-loop tasks. The AWS managed offering (SageMaker Ground Truth Plus) designs and customizes an end-to-end workflow and provides a skilled AWS managed team that is trained on specific tasks and meets your data quality, security, and compliance requirements. With model evaluation in Amazon Bedrock, you can set up FM evaluation jobs that use human workers to evaluate the responses from multiple models and compare them with a ground truth response. You can set up different methods including thumbs up or down, 5-point Likert scales, binary choice buttons, or ordinal ranking.
- Model evaluation – Model evaluation allows you to compare model outputs and choose the model best suited for downstream generative AI applications. You can use automatic model evaluations, human-in-the-loop evaluations or both. Model evaluation in Amazon Bedrock allows you to set up automatic evaluation jobs and evaluation jobs that use human workers. You can choose existing datasets or provide your own custom prompt dataset. With Amazon SageMaker Clarify, you can evaluate FMs from Amazon SageMaker JumpStart. You can set up model evaluation for different tasks such as text generation, summarization, classification, and question and answering, across different dimensions including prompt stereotyping, toxicity, factual knowledge, semantic robustness, and accuracy. Finally, you can build your own evaluation pipelines and use tools such as fmeval.
- Model monitoring – The model monitoring service allows tenants to evaluate model performance against predefined metrics. A model monitoring solution gathers request and response data, runs evaluation jobs to calculate performance metrics against preset baselines, saves the outputs, and sends an alert in case of issues.
If you use Amazon Bedrock, you can enable model invocation logging to collect input and output data and use Amazon Bedrock evaluation to run model evaluation jobs. Alternatively, you can use AWS Lambda and implement your own logic, or use open source tools such as fmeval. In SageMaker, you can enable data capture for your SageMaker real-time endpoint and use SageMaker Clarify to run the model evaluation jobs or implement your own evaluation logic. Both Amazon Bedrock and SageMaker integrate with SageMaker Ground Truth, which helps you gather ground truth data and human feedback for model responses. AWS Step Functions can help you orchestrate the end-to-end monitoring workflow.
Core services
Core services represent a collection of administrative and management components or modules. These components are designed to provide oversight, control, and governance over various aspects of the system’s operation, resource management, user and tenant administration, and model management. These are illustrated in the following diagram.

Tenant management and identity
Tenant management is a crucial aspect of multi-tenant systems, where a single instance of an application or environment serves multiple tenants or customers, each with their own isolated and secure environment. The tenant management component is responsible for managing and administering these tenants within the system.
- Tenant onboarding and provisioning – This helps with creating a repeatable onboarding process for new tenants. It involves creating tenant-specific environments, allocating resources, and configuring access controls based on the tenant’s requirements.
- Tenant configuration and customization – Many multi-tenant systems allow tenants to customize certain aspects of the application or environment to suit their specific needs. The tenant management component may provide interfaces or tools for tenants to configure settings, branding, workflows, or other customizable features within their isolated environments.
- Tenant monitoring and reporting – This component is directly linked to the monitor and metering component and reports on tenant-specific usage, performance, and resource consumption. It can provide insights into tenant activity, identify potential issues, and facilitate capacity planning and resource allocation for each tenant.
- Tenant billing and subscription management – In solutions with different pricing models or subscription plans, the tenant management component can handle billing and subscription management for each tenant based on their usage, resource consumption, or contracted service levels.
In the proposed solution, you also need an authorization flow that establishes the identity of the user making the request. With AWS IAM Identity Center, you can create or connect workforce users and centrally manage their access across their AWS accounts and applications. With Amazon Cognito, you can authenticate and authorize users from the built-in user directory, from your enterprise directory, and from other consumer identity providers. AWS Identity and Access Management (IAM) provides fine-grained access control. You can use IAM to specify who can access which FMs and resources to maintain least privilege permissions.
For example, in one common scenario with Cognito that accesses resources with API Gateway and Lambda with a user pool. In the following diagram, when your user signs in to an Amazon Cognito user pool, your application receives JSON Web Tokens (JWTs). You can use groups in a user pool to control permissions with API Gateway by mapping group membership to IAM roles. You can submit your user pool tokens with a request to API Gateway for verification by an Amazon Cognito authorizer Lambda function. For more information, see Using API Gateway with Amazon Cognito user pools.

It is recommended that you don’t use API keys for authentication or authorization to control access to your APIs. Instead, use an IAM role, a Lambda authorizer, or an Amazon Cognito user pool.
Model onboarding
A key aspect of the generative AI gateway is allowing controlled access to foundation and custom models across tenants. For FMs available through Amazon Bedrock, the model onboarding component maintains an allowlist of approved models that tenants can access. You can use a service such as Amazon DynamoDB to track allowlisted models. Similarly, for custom models deployed on Amazon SageMaker, the component tracks which tenants have access to which model versions through entries in the DynamoDB registry table.
To enforce access control, you can use AWS Lambda authorizers with Amazon API Gateway. When a tenant application calls the model invocation API, the Lambda authorizer verifies the tenant’s identity and checks if they have permission to access the requested model based on the DynamoDB registry table. If access is permitted, temporary credentials are issued, which scope down the tenant’s permissions to just the allowed model(s). This prevents tenants from accessing models they shouldn’t have access to. The authorizer logic can be customized based on an organization’s model access policies and governance requirements.
This approach supports model end of life. By managing the model from the allowlist in the DynamoDB registry table for all or selected tenants, models not included aren’t usable automatically, with no further code changes required in the solution.
Model registry
A model registry helps manage and track different versions of custom models. Services such as Amazon SageMaker Model Registry and Amazon DynamoDB help track available models, associated generated model artifacts, and lineage. A model registry offers the following:
- Version control – To track different versions of the generative AI models.
- Model lineage and provenance – To track the lineage and provenance of each model version, including information about the training data, hyperparameters, model architecture, and other relevant metadata that describes the model’s origin and characteristics.
- Model deployment and rollback – To facilitate the deployment and usage of new model versions into production environments and the rollback to previous versions if necessary. This makes sure that models can be updated or reverted seamlessly without disrupting the system’s operation.
- Model governance and compliance – To verify that model versions are properly documented, audited, and conform to relevant policies or regulations. This is particularly useful in regulated industries or environments with strict compliance requirements.
Observability
Observability is crucial for monitoring the health of your application, troubleshooting issues, usage of FMs, and optimizing performance and costs.

Logging and monitoring
Amazon CloudWatch is a powerful monitoring and observability service that allows you to collect and analyze logs from your application components, including API Gateway, Amazon Bedrock, Amazon SageMaker, and custom services. Using CloudWatch to capture tenant identity in the logs across the whole stack helps you gain insights into the performance and health of your generative AI gateway down to the tenant level and proactively identify and resolve issues before they escalate. You can also set up alarms to get notified in case of unexpected behavior. Both Amazon SageMaker and Amazon Bedrock are integrated with AWS CloudTrail.
Metering
Metering helps collect, aggregate, and analyze operational and usage data and performance metrics from different parts of the solution. In systems that offer pay-per-use or subscription-based models, metering is crucial for accurately measuring and reporting resource consumption for billing purposes across the different tenants.
In this solution, you need to track the usage of FMs to effectively manage costs and optimize resource utilization. Collecting information related to the models used, number of tokens provided as input, tokens generated as output, AWS Region used, and applying tags related to the team helps you streamline the cost allocation and billing processes. You can log structured data during interactions with the FMs and collect this usage information. The following diagram shows an implementation where the Lambda function logs per tenant information in Amazon CloudWatch and invokes Amazon Bedrock. The invocation generates an AWS CloudTrail event.

Auditing
You can use an AWS Lambda function to aggregate the data from Amazon CloudWatch and store it in S3 buckets for long-term storage and further analysis. Amazon S3 provides a highly durable, scalable, and cost-effective object storage solution, making it an ideal choice for storing large volumes of data. For implementation details, refer to part 1 of this series, Build an internal SaaS service with cost and usage tracking for foundation models on Amazon Bedrock.

Once the data is in Amazon S3, you can use AWS analytics services such as Amazon Athena, AWS Glue Data Catalog, and Amazon QuickSight to uncover patterns in the cost and usage data, generate reports, visualize trends, and make informed decisions about resource allocation, budget forecasting, and cost optimization strategies. With AWS Glue Data Catalog, a centralized metadata repository, and Amazon Athena, an interactive query service, you can run one-time SQL queries directly on the data stored in Amazon S3. The following example describes usage and cost per model per tenant in Athena.

Scaling across the enterprise
The following are some design considerations for when you scale this solution across hundreds of LOBs and teams within an organization.
- Account limits – So far, we have discussed how to deploy the gateway solution in a single AWS account. As teams rapidly onboard to the gateway and expand their usage of LLMs, this might result in various components hitting their AWS account limits and can quickly become a bottleneck. We recommend deploying the generative AI gateway to more than one AWS accounts where each AWS account corresponds to one LOB. The reasoning behind this suggestion is, generally, the LOBs in large enterprises are quite autonomous and can each have tens to hundreds of teams. In addition, they may have strict data privacy policies which restricts them from sharing the data with other LOBs. In addition to this account, each LOB may have their non-prod AWS account as well where this gateway solution is deployed for testing and integration purposes.
- Production and non-production workloads – In most cases, tenant teams will want to use this gateway across their development, test, and production environments. Although it largely depends on an organization’s operating model, our recommendation is to have a dedicated development, test, and production environment for the gateway as well, so the teams can experiment freely without overloading the production gateway or polluting it with non-production data. This offers the additional benefit that you can set the limits for non-production gateways lower than those in production.
- Handling RAG data components – For implementing RAG solutions, we suggest keeping all the data-related components on the tenant’s end. Every tenant will have their own data constraints, update cycle, format, terminologies, and permission groups. Assigning the responsibility of managing data sources to the gateway may hinder scalability because the gateway can’t accommodate the unique requirements of each tenant’s data sources and most likely will end up serving the lowest common denominator. Hence, we recommend having the data sources and related components managed on the tenant’s side.
- Avoid reinventing the wheel – With this solution, you can build and manage your own components for model evaluation, guardrails, prompt catalogue, monitoring, and more. Services such as Amazon Bedrock provide the capabilities you need to build generative AI applications with security, privacy, and responsible AI right from the start. Our recommendation is to take a balanced approach and, wherever possible, use AWS native capabilities to reduce operational costs.
- Keeping the generative AI gateway thin – Our suggestion is to keep this gateway thin in terms of storing business logic. The gateway shouldn’t add any business rules for any specific tenant and should avoid storing any kind of tenant specific data apart from operational data already discussed in the post.
Conclusion
A generative AI multi-tenant architecture helps you maintain security, governance, and cost controls while scaling the use of generative AI across multiple use cases and teams. In this post, we presented a reference multi-tenant architecture to help you accelerate generative AI adoption. We showed how to standardize common generative AI components and how to expose them as shared services. The proposed architecture also addressed key aspects of governance, security, observability, and responsible AI. Finally, we discussed key considerations when scaling this architecture to hundreds of teams.
If you want to read more about this topic, check out also the following resources:
- Establishing an AI/ML Center of Excellence
- Create a Generative AI Gateway to allow secure and compliant consumption of foundation models
Let us know what you think in the comments section!
About the authors

Anastasia Tzeveleka is a Senior Generative AI/ML Specialist Solutions Architect at AWS. As part of her work, she helps customers across EMEA build foundation models and create scalable generative AI and machine learning solutions using AWS services.

Hasan Poonawala is a Senior AI/ML Specialist Solutions Architect at AWS, working with Healthcare and Life Sciences customers. Hasan helps design, deploy and scale Generative AI and Machine learning applications on AWS. He has over 15 years of combined work experience in machine learning, software development and data science on the cloud. In his spare time, Hasan loves to explore nature and spend time with friends and family.

Bruno Pistone is a Senior Generative AI and ML Specialist Solutions Architect for AWS based in Milan. He works with large customers helping them to deeply understand their technical needs and design AI and Machine Learning solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. His expertise include: Machine Learning end to end, Machine Learning Industrialization, and Generative AI. He enjoys spending time with his friends and exploring new places, as well as travelling to new destinations

Vikesh Pandey is a Principal Generative AI/ML Solutions architect, specialising in financial services where he helps financial customers build and scale Generative AI/ML platforms and solution which scales to hundreds to even thousands of users. In his spare time, Vikesh likes to write on various blog forums and build legos with his kid.

Antonio Rodriguez is a Principal Generative AI Specialist Solutions Architect at Amazon Web Services. He helps companies of all sizes solve their challenges, embrace innovation, and create new business opportunities with Amazon Bedrock. Apart from work, he loves to spend time with his family and play sports with his friends.
Author: Anastasia Tzeveleka