

Build a multilingual automatic translation pipeline with Amazon Translate Active Custom Translation
ai used to address this challenge by using the Active Custom Translation (ACT) feature of Amazon Translate and building a multilingual automatic translation pipeline… We demonstrate how to use the AWS Management Console and Amazon Translate public API to deliver automatic machine batch translatio…
Dive into Deep Learning (D2L.ai) is an open-source textbook that makes deep learning accessible to everyone. It features interactive Jupyter notebooks with self-contained code in PyTorch, JAX, TensorFlow, and MXNet, as well as real-world examples, exposition figures, and math. So far, D2L has been adopted by more than 400 universities around the world, such as the University of Cambridge, Stanford University, the Massachusetts Institute of Technology, Carnegie Mellon University, and Tsinghua University. This work is also made available in Chinese, Japanese, Korean, Portuguese, Turkish, and Vietnamese, with plans to launch Spanish and other languages.
It is a challenging endeavor to have an online book that is continuously kept up to date, written by multiple authors, and available in multiple languages. In this post, we present a solution that D2L.ai used to address this challenge by using the Active Custom Translation (ACT) feature of Amazon Translate and building a multilingual automatic translation pipeline.
We demonstrate how to use the AWS Management Console and Amazon Translate public API to deliver automatic machine batch translation, and analyze the translations between two language pairs: English and Chinese, and English and Spanish. We also recommend best practices when using Amazon Translate in this automatic translation pipeline to ensure translation quality and efficiency.
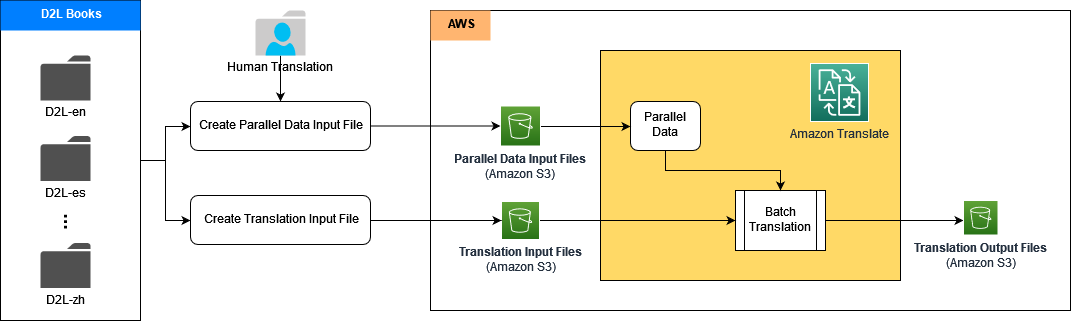
Solution overview
We built automatic translation pipelines for multiple languages using the ACT feature in Amazon Translate. ACT allows you to customize translation output on the fly by providing tailored translation examples in the form of parallel data. Parallel data consists of a collection of textual examples in a source language and the desired translations in one or more target languages. During translation, ACT automatically selects the most relevant segments from the parallel data and updates the translation model on the fly based on those segment pairs. This results in translations that better match the style and content of the parallel data.
The architecture contains multiple sub-pipelines; each sub-pipeline handles one language translation such as English to Chinese, English to Spanish, and so on. Multiple translation sub-pipelines can be processed in parallel. In each sub-pipeline, we first build the parallel data in Amazon Translate using the high-quality dataset of tailed translation examples from the human-translated D2L books. Then we generate the customized machine translation output on the fly at run time, which achieves better quality and accuracy.

In the following sections, we demonstrate how to build each translation pipeline using Amazon Translate with ACT, along with Amazon SageMaker and Amazon Simple Storage Service (Amazon S3).
First, we put the source documents, reference documents, and parallel data training set in an S3 bucket. Then we build Jupyter notebooks in SageMaker to run the translation process using Amazon Translate public APIs.
Prerequisites
To follow the steps in this post, make sure you have an AWS account with the following:
- Access to AWS Identity and Access Management (IAM) for role and policy configuration
- Access to Amazon Translate, SageMaker, and Amazon S3
- An S3 bucket to store the source documents, reference documents, parallel data dataset, and output of translation
Create an IAM role and policies for Amazon Translate with ACT
Our IAM role needs to contain a custom trust policy for Amazon Translate:
This role must also have a permissions policy that grants Amazon Translate read access to the input folder and subfolders in Amazon S3 that contain the source documents, and read/write access to the output S3 bucket and folder that contains the translated documents:
To run Jupyter notebooks in SageMaker for the translation jobs, we need to grant an inline permission policy to the SageMaker execution role. This role passes the Amazon Translate service role to SageMaker that allows the SageMaker notebooks to have access to the source and translated documents in the designated S3 buckets:
Prepare parallel data training samples
The parallel data in ACT needs to be trained by an input file consisting of a list of textual example pairs, for instance, a pair of source language (English) and target language (Chinese). The input file can be in TMX, CSV, or TSV format. The following screenshot shows an example of a CSV input file. The first column is the source language data (in English), and the second column is the target language data (in Chinese). The following example is extracted from D2L-en book and D2L-zh book.

Perform custom parallel data training in Amazon Translate
First, we set up the S3 bucket and folders as shown in the following screenshot. The source_data folder contains the source documents before the translation; the generated documents after the batch translation are put in the output folder. The ParallelData folder holds the parallel data input file prepared in the previous step.

After uploading the input files to the source_data folder, we can use the CreateParallelData API to run a parallel data creation job in Amazon Translate:
To update existing parallel data with new training datasets, we can use the UpdateParallelData API:
S3_BUCKET = “YOUR-S3_BUCKET-NAME”
pd_name = “pd-d2l-short_test_sentence_enzh_all”
pd_description = “Parallel Data for English to Chinese”
pd_fn = “d2l_short_test_sentence_enzh_all.csv”
response_t = translate_client.update_parallel_data(
Name=pd_name, # pd_name is the parallel data name
Description=pd_description, # pd_description is the parallel data description
ParallelDataConfig={
'S3Uri': 's3://'+S3_BUCKET+'/Paralleldata/'+pd_fn, # S3_BUCKET is the S3 bucket name defined in the previous step
'Format': 'CSV'
},
)
print(pd_name, ": ", response_t['Status'], " updated.")
We can check the training job progress on the Amazon Translate console. When the job is complete, the parallel data status shows as Active and is ready to use.

Run asynchronized batch translation using parallel data
The batch translation can be conducted in a process where multiple source documents are automatically translated into documents in target languages. The process involves uploading the source documents to the input folder of the S3 bucket, then applying the StartTextTranslationJob API of Amazon Translate to initiate an asynchronized translation job:
We selected five source documents in English from the D2L book (D2L-en) for the bulk translation. On the Amazon Translate console, we can monitor the translation job progress. When the job status changes into Completed, we can find the translated documents in Chinese (D2L-zh) in the S3 bucket output folder.

Evaluate the translation quality
To demonstrate the effectiveness of the ACT feature in Amazon Translate, we also applied the traditional method of Amazon Translate real-time translation without parallel data to process the same documents, and compared the output with the batch translation output with ACT. We used the BLEU (BiLingual Evaluation Understudy) score to benchmark the translation quality between the two methods. The only way to accurately measure the quality of machine translation output is to have an expert review and grade the quality. However, BLEU provides an estimate of relative quality improvement between two output. A BLEU score is typically a number between 0–1; it calculates the similarity of the machine translation to the reference human translation. The higher score represents better quality in natural language understanding (NLU).
We have tested a set of documents in four pipelines: English into Chinese (en to zh), Chinese into English (zh to en), English into Spanish (en to es), and Spanish into English (es to en). The following figure shows that the translation with ACT produced a higher average BLEU score in all the translation pipelines.

We also observed that, the more granular the parallel data pairs are, the better the translation performance. For example, we use the following parallel data input file with pairs of paragraphs, which contains 10 entries.

For the same content, we use the following parallel data input file with pairs of sentences and 16 entries.

We used both parallel data input files to construct two parallel data entities in Amazon Translate, then created two batch translation jobs with the same source document. The following figure compares the output translations. It shows that the output using parallel data with pairs of sentences out-performed the one using parallel data with pairs of paragraphs, for both English to Chinese translation and Chinese to English translation.

If you are interested in learning more about these benchmark analyses, refer to Auto Machine Translation and Synchronization for “Dive into Deep Learning”.
Clean up
To avoid recurring costs in the future, we recommend you clean up the resources you created:
- On the Amazon Translate console, select the parallel data you created and choose Delete. Alternatively, you can use the DeleteParallelData API or the AWS Command Line Interface (AWS CLI) delete-parallel-data command to delete the parallel data.
- Delete the S3 bucket used to host the source and reference documents, translated documents, and parallel data input files.
- Delete the IAM role and policy. For instructions, refer to Deleting roles or instance profiles and Deleting IAM policies.
Conclusion
With this solution, we aim to reduce the workload of human translators by 80%, while maintaining the translation quality and supporting multiple languages. You can use this solution to improve your translation quality and efficiency. We are working on further improving the solution architecture and translation quality for other languages.
Your feedback is always welcome; please leave your thoughts and questions in the comments section.
About the authors
 Yunfei Bai is a Senior Solutions Architect at AWS. With a background in AI/ML, data science, and analytics, Yunfei helps customers adopt AWS services to deliver business results. He designs AI/ML and data analytics solutions that overcome complex technical challenges and drive strategic objectives. Yunfei has a PhD in Electronic and Electrical Engineering. Outside of work, Yunfei enjoys reading and music.
Yunfei Bai is a Senior Solutions Architect at AWS. With a background in AI/ML, data science, and analytics, Yunfei helps customers adopt AWS services to deliver business results. He designs AI/ML and data analytics solutions that overcome complex technical challenges and drive strategic objectives. Yunfei has a PhD in Electronic and Electrical Engineering. Outside of work, Yunfei enjoys reading and music.
 Rachel Hu is an applied scientist at AWS Machine Learning University (MLU). She has been leading a few course designs, including ML Operations (MLOps) and Accelerator Computer Vision. Rachel is an AWS senior speaker and has spoken at top conferences including AWS re:Invent, NVIDIA GTC, KDD, and MLOps Summit. Before joining AWS, Rachel worked as a machine learning engineer building natural language processing models. Outside of work, she enjoys yoga, ultimate frisbee, reading, and traveling.
Rachel Hu is an applied scientist at AWS Machine Learning University (MLU). She has been leading a few course designs, including ML Operations (MLOps) and Accelerator Computer Vision. Rachel is an AWS senior speaker and has spoken at top conferences including AWS re:Invent, NVIDIA GTC, KDD, and MLOps Summit. Before joining AWS, Rachel worked as a machine learning engineer building natural language processing models. Outside of work, she enjoys yoga, ultimate frisbee, reading, and traveling.
 Watson Srivathsan is the Principal Product Manager for Amazon Translate, AWS’s natural language processing service. On weekends, you will find him exploring the outdoors in the Pacific Northwest.
Watson Srivathsan is the Principal Product Manager for Amazon Translate, AWS’s natural language processing service. On weekends, you will find him exploring the outdoors in the Pacific Northwest.
Author: Yunfei Bai