

Build an image-to-text generative AI application using multimodality models on Amazon SageMaker
As we delve deeper into the digital era, the development of multimodality models has been critical in enhancing machine understanding… These models process and generate content across various data forms, like text and images… A key feature of these models is their image-to-text capabilities, whi…
As we delve deeper into the digital era, the development of multimodality models has been critical in enhancing machine understanding. These models process and generate content across various data forms, like text and images. A key feature of these models is their image-to-text capabilities, which have shown remarkable proficiency in tasks such as image captioning and visual question answering.
By translating images into text, we unlock and harness the wealth of information contained in visual data. For instance, in ecommerce, image-to-text can automate product categorization based on images, enhancing search efficiency and accuracy. Similarly, it can assist in generating automatic photo descriptions, providing information that might not be included in product titles or descriptions, thereby improving user experience.
In this post, we provide an overview of popular multimodality models. We also demonstrate how to deploy these pre-trained models on Amazon SageMaker. Furthermore, we discuss the diverse applications of these models, focusing particularly on several real-world scenarios, such as zero-shot tag and attribution generation for ecommerce and automatic prompt generation from images.
Background of multimodality models
Machine learning (ML) models have achieved significant advancements in fields like natural language processing (NLP) and computer vision, where models can exhibit human-like performance in analyzing and generating content from a single source of data. More recently, there has been increasing attention in the development of multimodality models, which are capable of processing and generating content across different modalities. These models, such as the fusion of vision and language networks, have gained prominence due to their ability to integrate information from diverse sources and modalities, thereby enhancing their comprehension and expression capabilities.
In this section, we provide an overview of two popular multimodality models: CLIP (Contrastive Language-Image Pre-training) and BLIP (Bootstrapping Language-Image Pre-training).
CLIP model
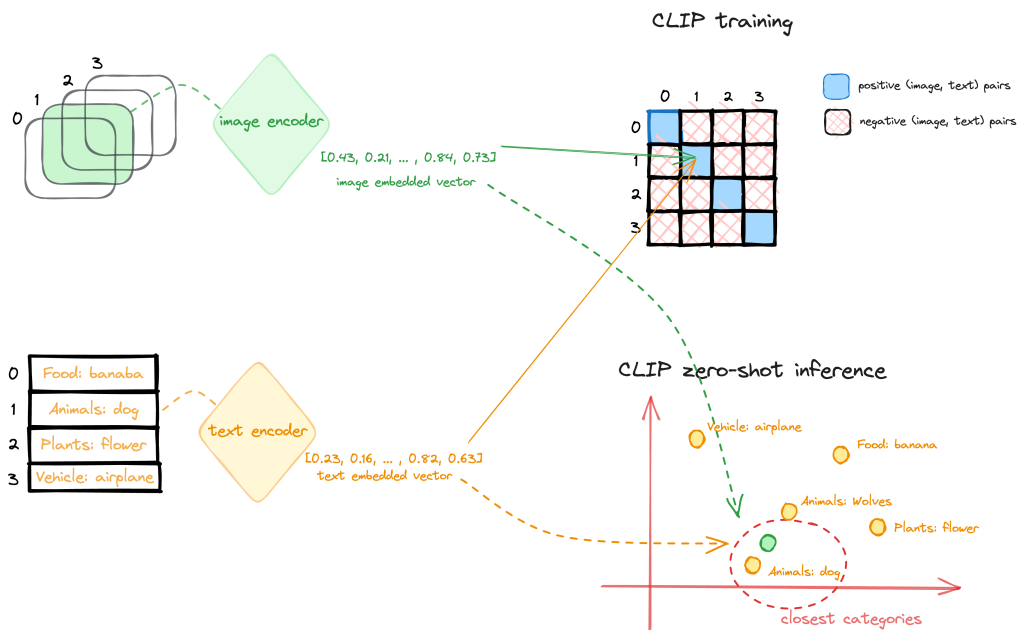
CLIP is a multi-modal vision and language model, which can be used for image-text similarity and for zero-shot image classification. CLIP is trained on a dataset of 400 million image-text pairs collected from a variety of publicly available sources on the internet. The model architecture consists of an image encoder and a text encoder, as shown in the following diagram.

During training, an image and corresponding text snippet are fed through the encoders to get an image feature vector and text feature vector. The goal is to make the image and text features for a matched pair have a high cosine similarity, while features for mismatched pairs have low similarity. This is done through a contrastive loss. This contrastive pre-training results in encoders that map images and text to a common embedding space where semantics are aligned.
The encoders can then be used for zero-shot transfer learning for downstream tasks. At inference time, the image and text pre-trained encoder processes its respective input and transforms it into a high-dimensional vector representation, or an embedding. The embeddings of the image and text are then compared to determine their similarity, such as cosine similarity. The text prompt (image classes, categories, or tags) whose embedding is most similar (for example, has the smallest distance) to the image embedding is considered the most relevant, and the image is classified accordingly.
BLIP model
Another popular multimodality model is BLIP. It introduces a novel model architecture capable of adapting to diverse vision-language tasks and employs a unique dataset bootstrapping technique to learn from noisy web data. BLIP architecture includes an image encoder and text encoder: the image-grounded text encoder injects visual information into the transformer block of the text encoder, and the image-grounded text decoder incorporates visual information into the transformer decoder block. With this architecture, BLIP demonstrates outstanding performance across a spectrum of vision-language tasks that involve the fusion of visual and linguistic information, from image-based search and content generation to interactive visual dialog systems. In a previous post, we proposed a content moderation solution based on the BLIP model that addressed multiple challenges using computer vision unimodal ML approaches.
Use case 1: Zero-shot tag or attribute generation for an ecommerce platform
Ecommerce platforms serve as dynamic marketplaces teeming with ideas, products, and services. With millions of products listed, effective sorting and categorization poses a significant challenge. This is where the power of auto-tagging and attribute generation comes into its own. By harnessing advanced technologies like ML and NLP, these automated processes can revolutionize the operations of ecommerce platforms.
One of the key benefits of auto-tagging or attribute generation lies in its ability to enhance searchability. Products tagged accurately can be found by customers swiftly and efficiently. For instance, if a customer is searching for a “cotton crew neck t-shirt with a logo in front,” auto-tagging and attribute generation enable the search engine to pinpoint products that match not merely the broader “t-shirt” category, but also the specific attributes of “cotton” and “crew neck.” This precise matching can facilitate a more personalized shopping experience and boost customer satisfaction. Moreover, auto-generated tags or attributes can substantially improve product recommendation algorithms. With a deep understanding of product attributes, the system can suggest more relevant products to customers, thereby increasing the likelihood of purchases and enhancing customer satisfaction.
CLIP offers a promising solution for automating the process of tag or attribute generation. It takes a product image and a list of descriptions or tags as input, generating a vector representation, or embedding, for each tag. These embeddings exist in a high-dimensional space, with their relative distances and directions reflecting the semantic relationships between the inputs. CLIP is pre-trained on a large scale of image-text pairs to encapsulate these meaningful embeddings. If a tag or attribute accurately describes an image, their embeddings should be relatively close in this space. To generate corresponding tags or attributes, a list of potential tags can be inputted into the text part of the CLIP model, and the resulting embeddings stored. Ideally, this list should be exhaustive, covering all potential categories and attributes relevant to the products on the ecommerce platform. The following figure shows some examples.

To deploy the CLIP model on SageMaker, you can follow the notebook in the following GitHub repo. We use the SageMaker pre-built large model inference (LMI) containers to deploy the model. The LMI containers use DJL Serving to serve your model for inference. To learn more about hosting large models on SageMaker, refer to Deploy large models on Amazon SageMaker using DJLServing and DeepSpeed model parallel inference and Deploy large models at high performance using FasterTransformer on Amazon SageMaker.
In this example, we provide the files serving.properties, model.py, and requirements.txt to prepare the model artifacts and store them in a tarball file.
serving.propertiesis the configuration file that can be used to indicate to DJL Serving which model parallelization and inference optimization libraries you would like to use. Depending on your need, you can set the appropriate configuration. For more details on the configuration options and an exhaustive list, refer to Configurations and settings.model.pyis the script that handles any requests for serving.requirements.txtis the text file containing any additional pip wheels to install.
If you want to download the model from Hugging Face directly, you can set the option.model_id parameter in the serving.properties file as the model id of a pre-trained model hosted inside a model repository on huggingface.co. The container uses this model id to download the corresponding model during deployment time. If you set the model_id to an Amazon Simple Storage Service (Amazon S3) URL, the DJL will download the model artifacts from Amazon S3 and swap the model_id to the actual location of the model artifacts. In your script, you can point to this value to load the pre-trained model. In our example, we use the latter option, because the LMI container uses s5cmd to download data from Amazon S3, which significantly reduces the speed when loading models during deployment. See the following code:
In the model.py script, we load the model path using the model ID provided in the property file:
After the model artifacts are prepared and uploaded to Amazon S3, you can deploy the CLIP model to SageMaker hosting with a few lines of code:
When the endpoint is in service, you can invoke the endpoint with an input image and a list of labels as the input prompt to generate the label probabilities:
Use case 2: Automatic prompt generation from images
One innovative application using the multimodality models is to generate informative prompts from an image. In generative AI, a prompt refers to the input provided to a language model or other generative model to instruct it on what type of content or response is desired. The prompt is essentially a starting point or a set of instructions that guides the model’s generation process. It can take the form of a sentence, question, partial text, or any input that conveys the context or desired output to the model. The choice of a well-crafted prompt is pivotal in generating high-quality images with precision and relevance. Prompt engineering is the process of optimizing or crafting a textual input to achieve desired responses from a language model, often involving wording, format, or context adjustments.
Prompt engineering for image generation poses several challenges, including the following:
- Defining visual concepts accurately – Describing visual concepts in words can sometimes be imprecise or ambiguous, making it difficult to convey the exact image desired. Capturing intricate details or complex scenes through textual prompts might not be straightforward.
- Specifying desired styles effectively – Communicating specific stylistic preferences, such as mood, color palette, or artistic style, can be challenging through text alone. Translating abstract aesthetic concepts into concrete instructions for the model can be tricky.
- Balancing complexity to prevent overloading the model – Elaborate prompts could confuse the model or lead to overloading it with information, affecting the generated output. Striking the right balance between providing sufficient guidance and avoiding overwhelming complexity is essential.
Therefore, crafting effective prompts for image generation is time consuming, which requires iterative experimentation and refining to strike the right balance between precision and creativity, making it a resource-intensive task that heavily relies on human expertise.
The CLIP Interrogator is an automatic prompt engineering tool for images that combines CLIP and BLIP to optimize text prompts to match a given image. You can use the resulting prompts with text-to-image models like Stable Diffusion to create cool art. The prompts created by CLIP Interrogator offer a comprehensive description of the image, covering not only its fundamental elements but also the artistic style, the potential inspiration behind the image, the medium where the image could have been or might be used, and beyond. You can easily deploy the CLIP Interrogator solution on SageMaker to streamline the deployment process, and take advantage of the scalability, cost-efficiency, and robust security provided by the fully managed service. The following diagram shows the flow logic of this solution.

You can use the following notebook to deploy the CLIP Interrogator solution on SageMaker. Similarly, for CLIP model hosting, we use the SageMaker LMI container to host the solution on SageMaker using DJL Serving. In this example, we provided an additional input file with the model artifacts that specifies the models deployed to the SageMaker endpoint. You can choose different CLIP or BLIP models by passing the caption model name and the clip model name through the model_name.json file created with the following code:
The inference script model.py contains a handle function that DJL Serving will run your request by invoking this function. To prepare this entry point script, we adopted the code from the original clip_interrogator.py file and modified it to work with DJL Serving on SageMaker hosting. One update is the loading of the BLIP model. The BLIP and CLIP models are loaded via the load_caption_model() and load_clip_model() function during the initialization of the Interrogator object. To load the BLIP model, we first downloaded the model artifacts from Hugging Face and uploaded them to Amazon S3 as the target value of the model_id in the properties file. This is because the BLIP model can be a large file, such as the blip2-opt-2.7b model, which is more than 15 GB in size. Downloading the model from Hugging Face during model deployment will require more time for endpoint creation. Therefore, we point the model_id to the Amazon S3 location of the BLIP2 model and load the model from the model path specified in the properties file. Note that, during deployment, the model path will be swapped to the local container path where the model artifacts were downloaded to by DJL Serving from the Amazon S3 location. See the following code:
Because the CLIP model isn’t very big in size, we use open_clip to load the model directly from Hugging Face, which is the same as the original clip_interrogator implementation:
We use similar code to deploy the CLIP Interrogator solution to a SageMaker endpoint and invoke the endpoint with an input image to get the prompts that can be used to generate similar images.
Let’s take the following image as an example. Using the deployed CLIP Interrogator endpoint on SageMaker, it generates the following text description: croissant on a plate, pexels contest winner, aspect ratio 16:9, cgsocietywlop, 8 h, golden cracks, the artist has used bright, picture of a loft in morning, object features, stylized border, pastry, french emperor.

We can further combine the CLIP Interrogator solution with Stable Diffusion and prompt engineering techniques—a whole new dimension of creative possibilities emerges. This integration allows us to not only describe images with text, but also manipulate and generate diverse variations of the original images. Stable Diffusion ensures controlled image synthesis by iteratively refining the generated output, and strategic prompt engineering guides the generation process towards desired outcomes.
In the second part of the notebook, we detail the steps to use prompt engineering to restyle images with the Stable Diffusion model (Stable Diffusion XL 1.0). We use the Stability AI SDK to deploy this model from SageMaker JumpStart after subscribing to this model on the AWS marketplace. Because this is a newer and better version for image generation provided by Stability AI, we can get high-quality images based on the original input image. Additionally, if we prefix the preceding description and add an additional prompt mentioning a known artist and one of his works, we get amazing results with restyling. The following image uses the prompt: This scene is a Van Gogh painting with The Starry Night style, croissant on a plate, pexels contest winner, aspect ratio 16:9, cgsocietywlop, 8 h, golden cracks, the artist has used bright, picture of a loft in morning, object features, stylized border, pastry, french emperor.

The following image uses the prompt: This scene is a Hokusai painting with The Great Wave off Kanagawa style, croissant on a plate, pexels contest winner, aspect ratio 16:9, cgsocietywlop, 8 h, golden cracks, the artist has used bright, picture of a loft in morning, object features, stylized border, pastry, french emperor.

Conclusion
The emergence of multimodality models, like CLIP and BLIP, and their applications are rapidly transforming the landscape of image-to-text conversion. Bridging the gap between visual and semantic information, they are providing us with the tools to unlock the vast potential of visual data and harness it in ways that were previously unimaginable.
In this post, we illustrated different applications of the multimodality models. These range from enhancing the efficiency and accuracy of search in ecommerce platforms through automatic tagging and categorization to the generation of prompts for text-to-image models like Stable Diffusion. These applications open new horizons for creating unique and engaging content. We encourage you to learn more by exploring the various multimodality models on SageMaker and build a solution that is innovative to your business.
About the Authors
 Yanwei Cui, PhD, is a Senior Machine Learning Specialist Solutions Architect at AWS. He started machine learning research at IRISA (Research Institute of Computer Science and Random Systems), and has several years of experience building AI-powered industrial applications in computer vision, natural language processing, and online user behavior prediction. At AWS, he shares his domain expertise and helps customers unlock business potentials and drive actionable outcomes with machine learning at scale. Outside of work, he enjoys reading and traveling.
Yanwei Cui, PhD, is a Senior Machine Learning Specialist Solutions Architect at AWS. He started machine learning research at IRISA (Research Institute of Computer Science and Random Systems), and has several years of experience building AI-powered industrial applications in computer vision, natural language processing, and online user behavior prediction. At AWS, he shares his domain expertise and helps customers unlock business potentials and drive actionable outcomes with machine learning at scale. Outside of work, he enjoys reading and traveling.
 Raghu Ramesha is a Senior ML Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
Raghu Ramesha is a Senior ML Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
 Sam Edwards, is a Cloud Engineer (AI/ML) at AWS Sydney specialized in machine learning and Amazon SageMaker. He is passionate about helping customers solve issues related to machine learning workflows and creating new solutions for them. Outside of work, he enjoys playing racquet sports and traveling.
Sam Edwards, is a Cloud Engineer (AI/ML) at AWS Sydney specialized in machine learning and Amazon SageMaker. He is passionate about helping customers solve issues related to machine learning workflows and creating new solutions for them. Outside of work, he enjoys playing racquet sports and traveling.
 Melanie Li, PhD, is a Senior AI/ML Specialist TAM at AWS based in Sydney, Australia. She helps enterprise customers build solutions using state-of-the-art AI/ML tools on AWS and provides guidance on architecting and implementing ML solutions with best practices. In her spare time, she loves to explore nature and spend time with family and friends.
Melanie Li, PhD, is a Senior AI/ML Specialist TAM at AWS based in Sydney, Australia. She helps enterprise customers build solutions using state-of-the-art AI/ML tools on AWS and provides guidance on architecting and implementing ML solutions with best practices. In her spare time, she loves to explore nature and spend time with family and friends.
 Gordon Wang is a Senior AI/ML Specialist TAM at AWS. He supports strategic customers with AI/ML best practices cross many industries. He is passionate about computer vision, NLP, generative AI, and MLOps. In his spare time, he loves running and hiking.
Gordon Wang is a Senior AI/ML Specialist TAM at AWS. He supports strategic customers with AI/ML best practices cross many industries. He is passionate about computer vision, NLP, generative AI, and MLOps. In his spare time, he loves running and hiking.
 Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
Author: Yanwei Cui