

Build and deploy ML inference applications from scratch using Amazon SageMaker

The solution to these complex business problems often requires using multiple ML models and steps… Amazon SageMaker offers built-in algorithms and pre-built SageMaker docker images for model deployment… Specialized models: For certain domains or industries, you may require specific model arc…
As machine learning (ML) goes mainstream and gains wider adoption, ML-powered inference applications are becoming increasingly common to solve a range of complex business problems. The solution to these complex business problems often requires using multiple ML models and steps. This post shows you how to build and host an ML application with custom containers on Amazon SageMaker.
Amazon SageMaker offers built-in algorithms and pre-built SageMaker docker images for model deployment. But, if these don’t fit your needs, you can bring your own containers (BYOC) for hosting on Amazon SageMaker.
There are several use cases where users might need to BYOC for hosting on Amazon SageMaker.
- Custom ML frameworks or libraries: If you plan on using a ML framework or libraries that aren’t supported by Amazon SageMaker built-in algorithms or pre-built containers, then you’ll need to create a custom container.
- Specialized models: For certain domains or industries, you may require specific model architectures or tailored preprocessing steps that aren’t available in built-in Amazon SageMaker offerings.
- Proprietary algorithms: If you’ve developed your own proprietary algorithms inhouse, then you’ll need a custom container to deploy them on Amazon SageMaker.
- Complex inference pipelines: If your ML inference workflow involves custom business logic — a series of complex steps that need to be executed in a particular order — then BYOC can help you manage and orchestrate these steps more efficiently.
Solution overview
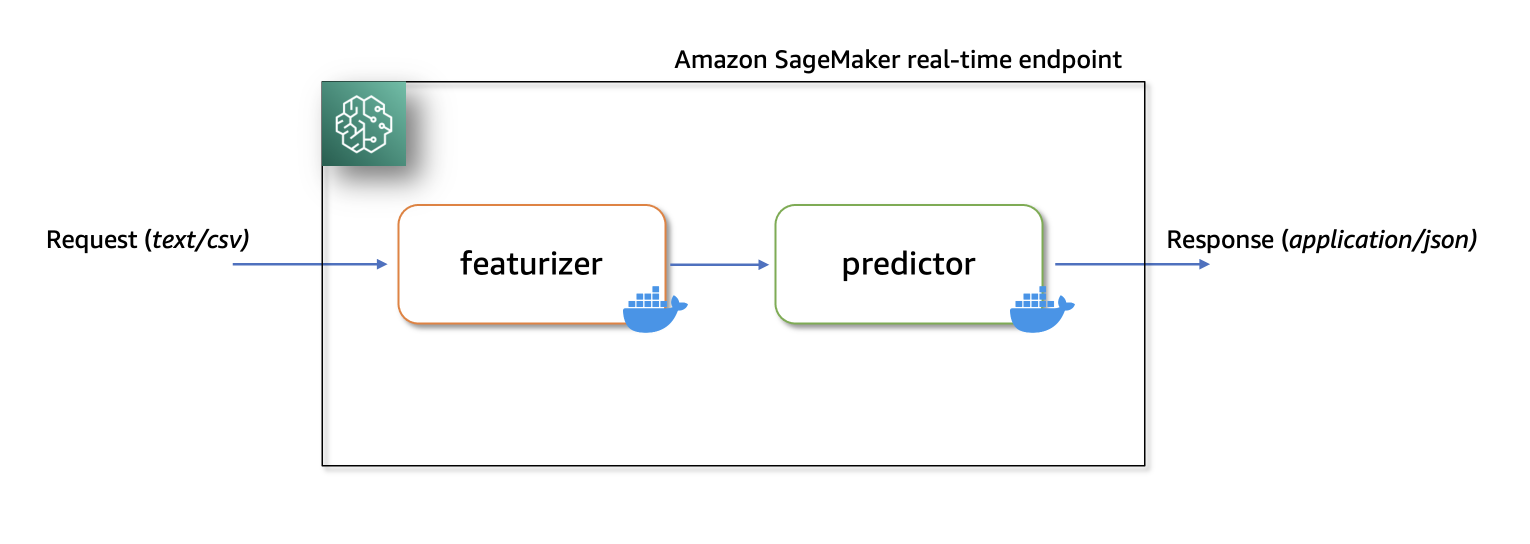
In this solution, we show how to host a ML serial inference application on Amazon SageMaker with real-time endpoints using two custom inference containers with latest scikit-learn and xgboost packages.
The first container uses a scikit-learn model to transform raw data into featurized columns. It applies StandardScaler for numerical columns and OneHotEncoder to categorical ones.

The second container hosts a pretrained XGboost model (i.e., predictor). The predictor model accepts the featurized input and outputs predictions.

Lastly, we deploy the featurizer and predictor in a serial-inference pipeline to an Amazon SageMaker real-time endpoint.
Here are few different considerations as to why you may want to have separate containers within your inference application.
- Decoupling – Various steps of the pipeline have a clearly defined purpose and need to be run on separate containers due to the underlying dependencies involved. This also helps keep the pipeline well structured.
- Frameworks – Various steps of the pipeline use specific fit-for-purpose frameworks (such as scikit or Spark ML) and therefore need to be run on separate containers.
- Resource isolation – Various steps of the pipeline have varying resource consumption requirements and therefore need to be run on separate containers for more flexibility and control.
- Maintenance and upgrades – From an operational standpoint, this promotes functional isolation and you can continue to upgrade or modify individual steps much more easily, without affecting other models.
Additionally, local build of the individual containers helps in the iterative process of development and testing with favorite tools and Integrated Development Environments (IDEs). Once the containers are ready, you can use deploy them to the AWS cloud for inference using Amazon SageMaker endpoints.
Full implementation, including code snippets, is available in this Github repository here.
Prerequisites
As we test these custom containers locally first, we’ll need docker desktop installed on your local computer. You should be familiar with building docker containers.
You’ll also need an AWS account with access to Amazon SageMaker, Amazon ECR and Amazon S3 to test this application end-to-end.
Ensure you have the latest version of Boto3 and the Amazon SageMaker Python packages installed:
Solution Walkthrough
Build custom featurizer container
To build the first container, the featurizer container, we train a scikit-learn model to process raw features in the abalone dataset. The preprocessing script uses SimpleImputer for handling missing values, StandardScaler for normalizing numerical columns, and OneHotEncoder for transforming categorical columns. After fitting the transformer, we save the model in joblib format. We then compress and upload this saved model artifact to an Amazon Simple Storage Service (Amazon S3) bucket.
Here’s a sample code snippet that demonstrates this. Refer to featurizer.ipynb for full implementation:
Next, to create a custom inference container for the featurizer model, we build a Docker image with nginx, gunicorn, flask packages, along with other required dependencies for the featurizer model.
Nginx, gunicorn and the Flask app will serve as the model serving stack on Amazon SageMaker real-time endpoints.
When bringing custom containers for hosting on Amazon SageMaker, we need to ensure that the inference script performs the following tasks after being launched inside the container:
- Model loading: Inference script (
preprocessing.py) should refer to/opt/ml/modeldirectory to load the model in the container. Model artifacts in Amazon S3 will be downloaded and mounted onto the container at the path/opt/ml/model. - Environment variables: To pass custom environment variables to the container, you must specify them during the Model creation step or during Endpoint creation from a training job.
- API requirements: The Inference script must implement both
/pingand/invocationsroutes as a Flask application. The/pingAPI is used for health checks, while the/invocationsAPI handles inference requests. - Logging: Output logs in the inference script must be written to standard output (stdout) and standard error (stderr) streams. These logs are then streamed to Amazon CloudWatch by Amazon SageMaker.
Here’s a snippet from preprocessing.py that show the implementation of /ping and /invocations.
Refer to preprocessing.py under the featurizer folder for full implementation.
Build Docker image with featurizer and model serving stack
Let’s now build a Dockerfile using a custom base image and install required dependencies.
For this, we use python:3.9-slim-buster as the base image. You can change this any other base image relevant to your use case.
We then copy the nginx configuration, gunicorn’s web server gateway file, and the inference script to the container. We also create a python script called serve that launches nginx and gunicorn processes in the background and sets the inference script (i.e., preprocessing.py Flask application) as the entry point for the container.
Here’s a snippet of the Dockerfile for hosting the featurizer model. For full implementation refer to Dockerfile under featurizer folder.
Test custom inference image with featurizer locally
Now, build and test the custom inference container with featurizer locally, using Amazon SageMaker local mode. Local mode is perfect for testing your processing, training, and inference scripts without launching any jobs on Amazon SageMaker. After confirming the results of your local tests, you can easily adapt the training and inference scripts for deployment on Amazon SageMaker with minimal changes.
To test the featurizer custom image locally, first build the image using the previously defined Dockerfile. Then, launch a container by mounting the directory containing the featurizer model (preprocess.joblib) to the /opt/ml/model directory inside the container. Additionally, map port 8080 from container to the host.
Once launched, you can send inference requests to http://localhost:8080/invocations.
To build and launch the container, open a terminal and run the following commands.
Note that you should replace the <IMAGE_NAME>, as shown in the following code, with the image name of your container.
The following command also assumes that the trained scikit-learn model (preprocess.joblib) is present under a directory called models.
After the container is up and running, we can test both the /ping and /invocations routes using curl commands.
Run the below commands from a terminal
When raw (untransformed) data is sent to http://localhost:8080/invocations, the endpoint responds with transformed data.
You should see response something similar to the following:
We now terminate the running container, and then tag and push the local custom image to a private Amazon Elastic Container Registry (Amazon ECR) repository.
See the following commands to login to Amazon ECR, which tags the local image with full Amazon ECR image path and then push the image to Amazon ECR. Ensure you replace region and account variables to match your environment.
Refer to create a repository and push an image to Amazon ECR AWS Command Line Interface (AWS CLI) commands for more information.
Optional step
Optionally, you could perform a live test by deploying the featurizer model to a real-time endpoint with the custom docker image in Amazon ECR. Refer to featurizer.ipynb notebook for full implementation of buiding, testing, and pushing the custom image to Amazon ECR.
Amazon SageMaker initializes the inference endpoint and copies the model artifacts to the /opt/ml/model directory inside the container. See How SageMaker Loads your Model artifacts.
Build custom XGBoost predictor container
For building the XGBoost inference container we follow similar steps as we did while building the image for featurizer container:
- Download pre-trained
XGBoostmodel from Amazon S3. - Create the
inference.pyscript that loads the pretrainedXGBoostmodel, converts the transformed input data received from featurizer, and converts toXGBoost.DMatrixformat, runspredicton the booster, and returns predictions in json format. - Scripts and configuration files that form the model serving stack (i.e.,
nginx.conf,wsgi.py, andserveremain the same and needs no modification. - We use
Ubuntu:18.04as the base image for the Dockerfile. This isn’t a prerequisite. We use the ubuntu base image to demonstrate that containers can be built with any base image. - The steps for building the customer docker image, testing the image locally, and pushing the tested image to Amazon ECR remain the same as before.
For brevity, as the steps are similar shown previously; however, we only show the changed coding in the following.
First, the inference.py script. Here’s a snippet that show the implementation of /ping and /invocations. Refer to inference.py under the predictor folder for full implementation of this file.
Here’s a snippet of the Dockerfile for hosting the predictor model. For full implementation refer to Dockerfile under predictor folder.
We then continue to build, test, and push this custom predictor image to a private repository in Amazon ECR. Refer to predictor.ipynb notebook for full implementation of building, testing and pushing the custom image to Amazon ECR.
Deploy serial inference pipeline
After we have tested both the featurizer and predictor images and have pushed them to Amazon ECR, we now upload our model artifacts to an Amazon S3 bucket.
Then, we create two model objects: one for the featurizer (i.e., preprocess.joblib) and other for the predictor (i.e., xgboost-model) by specifying the custom image uri we built earlier.
Here’s a snippet that shows that. Refer to serial-inference-pipeline.ipynb for full implementation.
Now, to deploy these containers in a serial fashion, we first create a PipelineModel object and pass the featurizer model and the predictor model to a python list object in the same order.
Then, we call the .deploy() method on the PipelineModel specifying the instance type and instance count.
At this stage, Amazon SageMaker deploys the serial inference pipeline to a real-time endpoint. We wait for the endpoint to be InService.
We can now test the endpoint by sending some inference requests to this live endpoint.
Refer to serial-inference-pipeline.ipynb for full implementation.
Clean up
After you are done testing, please follow the instructions in the cleanup section of the notebook to delete the resources provisioned in this post to avoid unnecessary charges. Refer to Amazon SageMaker Pricing for details on the cost of the inference instances.
Conclusion
In this post, I showed how we can build and deploy a serial ML inference application using custom inference containers to real-time endpoints on Amazon SageMaker.
This solution demonstrates how customers can bring their own custom containers for hosting on Amazon SageMaker in a cost-efficient manner. With BYOC option, customers can quickly build and adapt their ML applications to be deployed on to Amazon SageMaker.
We encourage you to try this solution with a dataset relevant to your business Key Performance Indicators (KPIs). You can refer to the entire solution in this GitHub repository.
References
- Model hosting patterns in Amazon SageMaker
- Amazon SageMaker Bring your own containers
- Hosting models as serial inference pipeline on Amazon SageMaker
About the Author
 Praveen Chamarthi is a Senior AI/ML Specialist with Amazon Web Services. He is passionate about AI/ML and all things AWS. He helps customers across the Americas to scale, innovate, and operate ML workloads efficiently on AWS. In his spare time, Praveen loves to read and enjoys sci-fi movies.
Praveen Chamarthi is a Senior AI/ML Specialist with Amazon Web Services. He is passionate about AI/ML and all things AWS. He helps customers across the Americas to scale, innovate, and operate ML workloads efficiently on AWS. In his spare time, Praveen loves to read and enjoys sci-fi movies.
Author: Praveen Chamarthi