

Build enterprise-ready generative AI solutions with Cohere foundation models in Amazon Bedrock and Weaviate vector database on AWS Marketplace
The example use case generates targeted advertisements for vacation stay listings based on a target audience… The goal is to use the user query for the target audience (for example, “family with small children”) to retrieve the most relevant vacation stay listing (for example, a listing with…
Generative AI solutions have the potential to transform businesses by boosting productivity and improving customer experiences, and using large language models (LLMs) with these solutions has become increasingly popular. Building proofs of concept is relatively straightforward because cutting-edge foundation models are available from specialized providers through a simple API call. Therefore, organizations of various sizes and across different industries have begun to reimagine their products and processes using generative AI.
Despite their wealth of general knowledge, state-of-the-art LLMs only have access to the information they were trained on. This can lead to factual inaccuracies (hallucinations) when the LLM is prompted to generate text based on information they didn’t see during their training. Therefore, it’s crucial to bridge the gap between the LLM’s general knowledge and your proprietary data to help the model generate more accurate and contextual responses while reducing the risk of hallucinations. The traditional method of fine-tuning, although effective, can be compute-intensive, expensive, and requires technical expertise. Another option to consider is called Retrieval Augmented Generation (RAG), which provides LLMs with additional information from an external knowledge source that can be updated easily.
Additionally, enterprises must ensure data security when handling proprietary and sensitive data, such as personal data or intellectual property. This is particularly important for organizations operating in heavily regulated industries, such as financial services and healthcare and life sciences. Therefore, it’s important to understand and control the flow of your data through the generative AI application: Where is the model located? Where is the data processed? Who has access to the data? Will the data be used to train models, eventually risking the leak of sensitive data to public LLMs?
This post discusses how enterprises can build accurate, transparent, and secure generative AI applications while keeping full control over proprietary data. The proposed solution is a RAG pipeline using an AI-native technology stack, whose components are designed from the ground up with AI at their core, rather than having AI capabilities added as an afterthought. We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace. The accompanying source code is available in the related GitHub repository hosted by Weaviate. Although AWS will not be responsible for maintaining or updating the code in the partner’s repository, we encourage customers to connect with Weaviate directly regarding any desired updates.
Solution overview
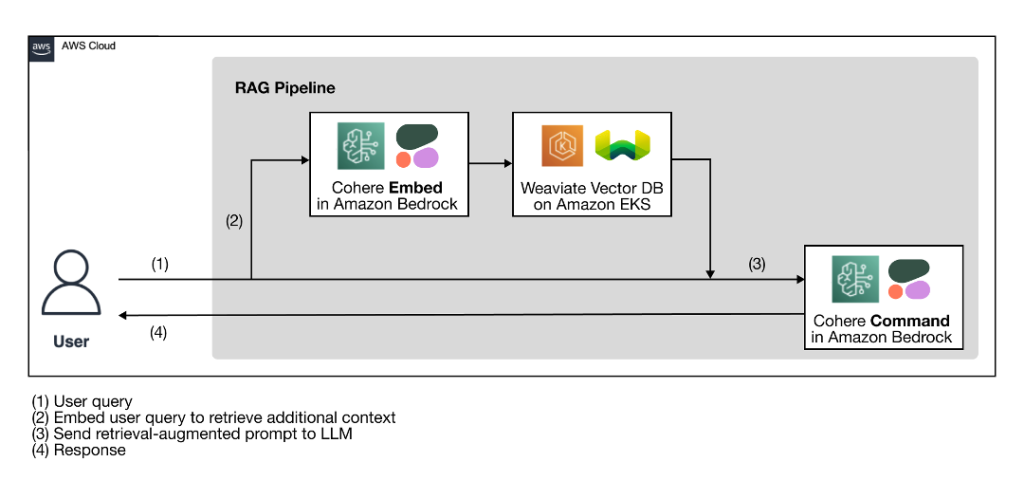
The following high-level architecture diagram illustrates the proposed RAG pipeline with an AI-native technology stack for building accurate, transparent, and secure generative AI solutions.
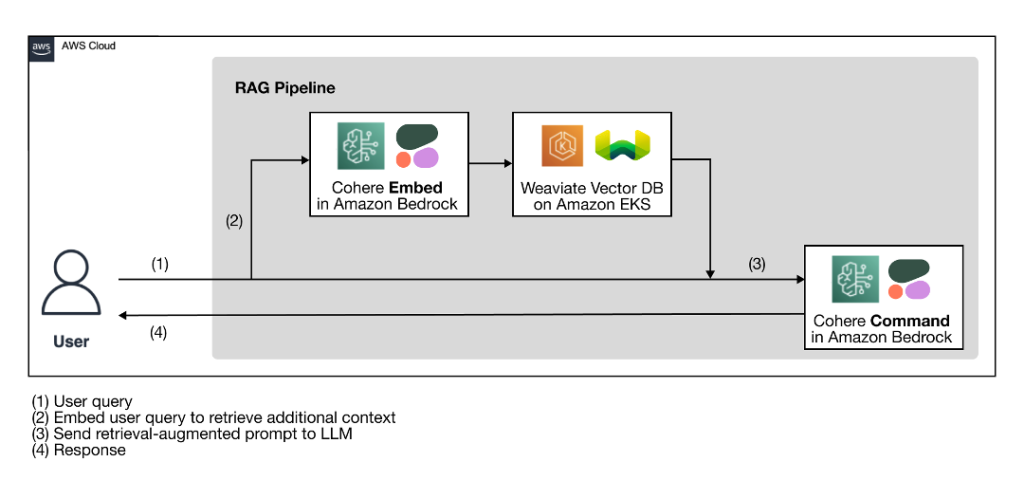
Figure 1: RAG workflow using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace
As a preparation step for the RAG workflow, a vector database, which serves as the external knowledge source, is ingested with the additional context from the proprietary data. The actual RAG workflow follows the four steps illustrated in the diagram:
- The user enters their query.
- The user query is used to retrieve relevant additional context from the vector database. This is done by generating the vector embeddings of the user query with an embedding model to perform a vector search to retrieve the most relevant context from the database.
- The retrieved context and the user query are used to augment a prompt template. The retrieval-augmented prompt helps the LLM generate a more relevant and accurate completion, minimizing hallucinations.
- The user receives a more accurate response based on their query.
The AI-native technology stack illustrated in the architecture diagram has two key components: Cohere language models and a Weaviate vector database.
Cohere language models in Amazon Bedrock
The Cohere Platform brings language models with state-of-the-art performance to enterprises and developers through a simple API call. There are two key types of language processing capabilities that the Cohere Platform provides—generative and embedding—and each is served by a different type of model:
- Text generation with Command – Developers can access endpoints that power generative AI capabilities, enabling applications such as conversational, question answering, copywriting, summarization, information extraction, and more.
- Text representation with Embed – Developers can access endpoints that capture the semantic meaning of text, enabling applications such as vector search engines, text classification and clustering, and more. Cohere Embed comes in two forms, an English language model and a multilingual model, both of which are now available on Amazon Bedrock.
The Cohere Platform empowers enterprises to customize their generative AI solution privately and securely through the Amazon Bedrock deployment. Amazon Bedrock is a fully managed cloud service that enables development teams to build and scale generative AI applications quickly while helping keep your data and applications secure and private. Your data is not used for service improvements, is never shared with third-party model providers, and remains in the Region where the API call is processed. The data is always encrypted in transit and at rest, and you can encrypt the data using your own keys. Amazon Bedrock supports security requirements, including U.S. Health Insurance Portability and Accountability Act (HIPAA) eligibility and General Data Protection Regulation (GDPR) compliance. Additionally, you can securely integrate and easily deploy your generative AI applications using the AWS tools you are already familiar with.
Weaviate vector database on AWS Marketplace
Weaviate is an AI-native vector database that makes it straightforward for development teams to build secure and transparent generative AI applications. Weaviate is used to store and search both vector data and source objects, which simplifies development by eliminating the need to host and integrate separate databases. Weaviate delivers subsecond semantic search performance and can scale to handle billions of vectors and millions of tenants. With a uniquely extensible architecture, Weaviate integrates natively with Cohere foundation models deployed in Amazon Bedrock to facilitate the convenient vectorization of data and use its generative capabilities from within the database.
The Weaviate AI-native vector database gives customers the flexibility to deploy it as a bring-your-own-cloud (BYOC) solution or as a managed service. This showcase uses the Weaviate Kubernetes Cluster on AWS Marketplace, part of Weaviate’s BYOC offering, which allows container-based scalable deployment inside your AWS tenant and VPC with just a few clicks using an AWS CloudFormation template. This approach ensures that your vector database is deployed in your specific Region close to the foundation models and proprietary data to minimize latency, support data locality, and protect sensitive data while addressing potential regulatory requirements, such as GDPR.
Use case overview
In the following sections, we demonstrate how to build a RAG solution using the AI-native technology stack with Cohere, AWS, and Weaviate, as illustrated in the solution overview.
The example use case generates targeted advertisements for vacation stay listings based on a target audience. The goal is to use the user query for the target audience (for example, “family with small children”) to retrieve the most relevant vacation stay listing (for example, a listing with playgrounds close by) and then to generate an advertisement for the retrieved listing tailored to the target audience.

Figure 2: First few rows of vacation stay listings available from Inside Airbnb.
The dataset is available from Inside Airbnb and is licensed under a Creative Commons Attribution 4.0 International License. You can find the accompanying code in the GitHub repository.
Prerequisites
To follow along and use any AWS services in the following tutorial, make sure you have an AWS account.
Enable components of the AI-native technology stack
First, you need to enable the relevant components discussed in the solution overview in your AWS account. Complete the following steps:
- In the left Amazon Bedrock console, choose Model access in the navigation pane.
- Choose Manage model access on the top right.
- Select the foundation models of your choice and request access.
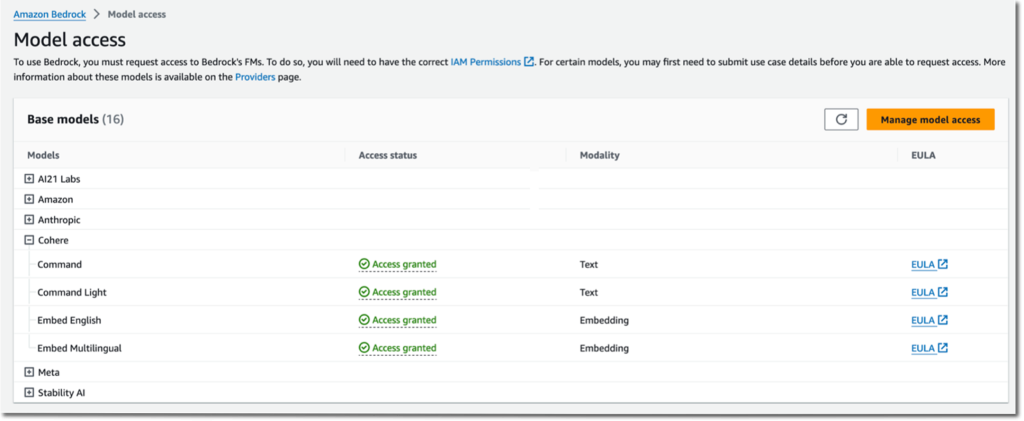
Figure 3: Manage model access in Amazon Bedrock console.
Next, you set up a Weaviate cluster.
- Subscribe to the Weaviate Kubernetes Cluster on AWS Marketplace.
- Launch the software using a CloudFormation template according to your preferred Availability Zone.
The CloudFormation template is pre-populated with default values.
- For Stack name, enter a stack name.
- For helmauthenticationtype, it is recommended to enable authentication by setting
helmauthenticationtypetoapikeyand defining a helmauthenticationapikey. - For helmauthenticationapikey, enter your Weaviate API key.
- For helmchartversion, enter your version number. It must be at least v.16.8.0. Refer to the GitHub repo for the latest version.
- For helmenabledmodules, make sure
tex2vec-awsandgenerative-awsare present in the list of enabled modules within Weaviate.
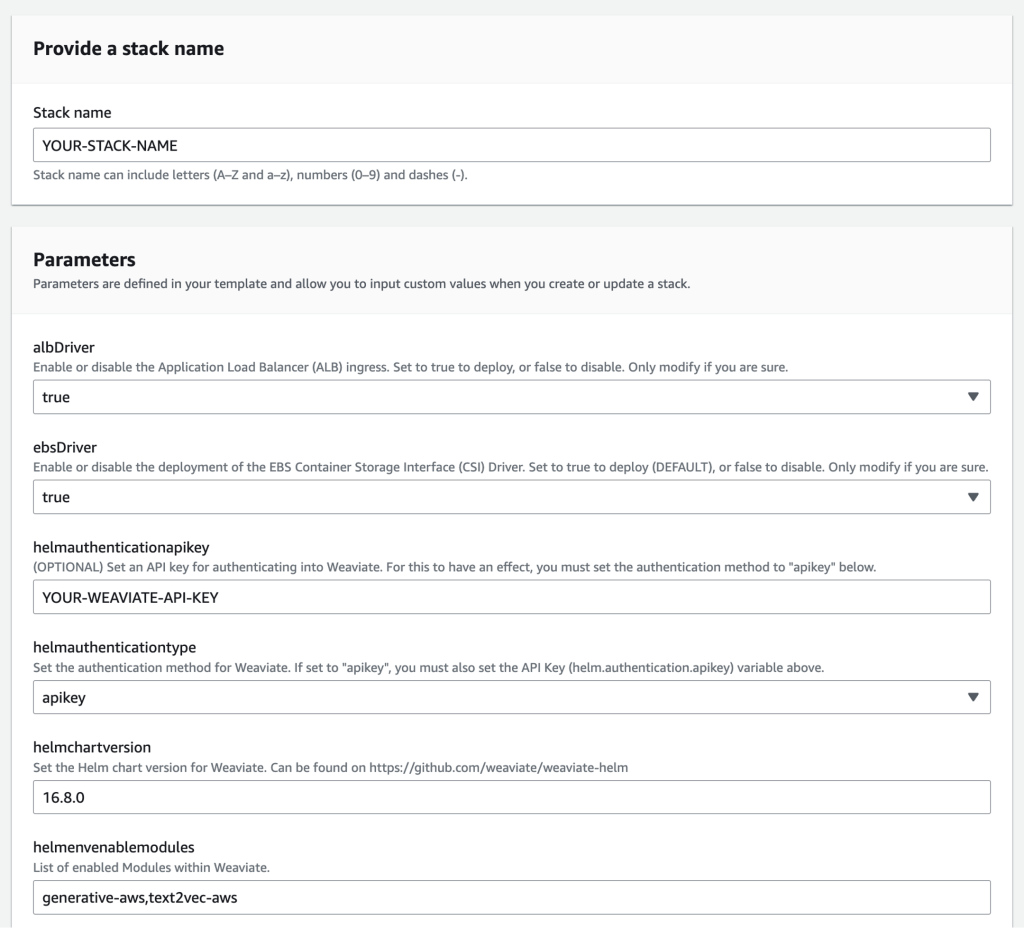
Figure 4: CloudFormation template.
This template takes about 30 minutes to complete.
Connect to Weaviate
Complete the following steps to connect to Weaviate:
- In the Amazon SageMaker console, navigate to Notebook instances in the navigation pane via Notebook > Notebook instances on the left.
- Create a new notebook instance.
- Install the Weaviate client package with the required dependencies:
- Connect to your Weaviate instance with the following code:
- Weaviate URL – Access Weaviate via the load balancer URL. In the Amazon Elastic Compute Cloud (Amazon EC2) console, choose Load balancers in the navigation pane and find the load balancer. Look for the DNS name column and add
http://in front of it. - Weaviate API key – This is the key you set earlier in the CloudFormation template (
helmauthenticationapikey). - AWS access key and secret access key – You can retrieve the access key and secret access key for your user in the AWS Identity and Access Management (IAM) console.
Figure 5: AWS Identity and Access Management (IAM) console to retrieve AWS access key and secret access key.
Configure the Amazon Bedrock module to enable Cohere models
Next, you define a data collection (class) called Listings to store the listings’ data objects, which is analogous to creating a table in a relational database. In this step, you configure the relevant modules to enable the usage of Cohere language models hosted on Amazon Bedrock natively from within the Weaviate vector database. The vectorizer (“text2vec-aws“) and generative module (“generative-aws“) are specified in the data collection definition. Both of these modules take three parameters:
- “service” – Use “
bedrock” for Amazon Bedrock (alternatively, use “sagemaker” for Amazon SageMaker JumpStart) - “Region” – Enter the Region where your model is deployed
- “model” – Provide the foundation model’s name
See the following code:
Ingest data into the Weaviate vector database
In this step, you define the structure of the data collection by configuring its properties. Aside from the property’s name and data type, you can also configure if only the data object will be stored or if it will be stored together with its vector embeddings. In this example, host_name and property_type are not vectorized:
Run the following code to create the collection in your Weaviate instance:
You can now add objects to Weaviate. You use a batch import process for maximum efficiency. Run the following code to import data. During the import, Weaviate will use the defined vectorizer to create a vector embedding for each object. The following code loads objects, initializes a batch process, and adds objects to the target collection one by one:
Retrieval Augmented Generation
You can build a RAG pipeline by implementing a generative search query on your Weaviate instance. For this, you first define a prompt template in the form of an f-string that can take in the user query ({target_audience}) directly and the additional context ({{host_name}}, {{property_type}}, {{description}}, and {{neighborhood_overview}}) from the vector database at runtime:
Next, you run a generative search query. This prompts the defined generative model with a prompt that is comprised of the user query as well as the retrieved data. The following query retrieves one listing object (.with_limit(1)) from the Listings collection that is most similar to the user query (.with_near_text({"concepts": target_audience})). Then the user query (target_audience) and the retrieved listings properties (["description", "neighborhood", "host_name", "property_type"]) are fed into the prompt template. See the following code:
In the following example, you can see that the preceding piece of code for target_audience = “Family with small children” retrieves a listing from the host Marre. The prompt template is augmented with Marre’s listing details and the target audience:
Based on the retrieval-augmented prompt, Cohere’s Command model generates the following targeted advertisement:
Alternative customizations
You can make alternative customizations to different components in the proposed solution, such as the following:
- Cohere’s language models are also available through Amazon SageMaker JumpStart, which provides access to cutting-edge foundation models and enables developers to deploy LLMs to Amazon SageMaker, a fully managed service that brings together a broad set of tools to enable high-performance, low-cost machine learning for any use case. Weaviate is integrated with SageMaker as well.
- A powerful addition to this solution is the Cohere Rerank endpoint, available through SageMaker JumpStart. Rerank can improve the relevance of search results from lexical or semantic search. Rerank works by computing semantic relevance scores for documents that are retrieved by a search system and ranking the documents based on these scores. Adding Rerank to an application requires only a single line of code change.
- To cater to different deployment requirements of different production environments, Weaviate can be deployed in various additional ways. For example, it is available as a direct download from Weaviate website, which runs on Amazon Elastic Kubernetes Service (Amazon EKS) or locally via Docker or Kubernetes. It’s also available as a managed service that can run securely within a VPC or as a public cloud service hosted on AWS with a 14-day free trial.
- You can serve your solution in a VPC using Amazon Virtual Private Cloud (Amazon VPC), which enables organizations to launch AWS services in a logically isolated virtual network, resembling a traditional network but with the benefits of AWS’s scalable infrastructure. Depending on the classified level of sensitivity of the data, organizations can also disable internet access in these VPCs.
Clean up
To prevent unexpected charges, delete all the resources you deployed as part of this post. If you launched the CloudFormation stack, you can delete it via the AWS CloudFormation console. Note that there may be some AWS resources, such as Amazon Elastic Block Store (Amazon EBS) volumes and AWS Key Management Service (AWS KMS) keys, that may not be deleted automatically when the CloudFormation stack is deleted.

Figure 6: Delete all resources via the AWS CloudFormation console.
Conclusion
This post discussed how enterprises can build accurate, transparent, and secure generative AI applications while still having full control over their data. The proposed solution is a RAG pipeline using an AI-native technology stack as a combination of Cohere foundation models in Amazon Bedrock and a Weaviate vector database on AWS Marketplace. The RAG approach enables enterprises to bridge the gap between the LLM’s general knowledge and the proprietary data while minimizing hallucinations. An AI-native technology stack enables fast development and scalable performance.
You can start experimenting with RAG proofs of concept for your enterprise-ready generative AI applications using the steps outlined in this post. The accompanying source code is available in the related GitHub repository. Thank you for reading. Feel free to provide comments or feedback in the comments section.
About the authors
 James Yi is a Senior AI/ML Partner Solutions Architect in the Technology Partners COE Tech team at Amazon Web Services. He is passionate about working with enterprise customers and partners to design, deploy, and scale AI/ML applications to derive business value. Outside of work, he enjoys playing soccer, traveling, and spending time with his family.
James Yi is a Senior AI/ML Partner Solutions Architect in the Technology Partners COE Tech team at Amazon Web Services. He is passionate about working with enterprise customers and partners to design, deploy, and scale AI/ML applications to derive business value. Outside of work, he enjoys playing soccer, traveling, and spending time with his family.
 Leonie Monigatti is a Developer Advocate at Weaviate. Her focus area is AI/ML, and she helps developers learn about generative AI. Outside of work, she also shares her learnings in data science and ML on her blog and on Kaggle.
Leonie Monigatti is a Developer Advocate at Weaviate. Her focus area is AI/ML, and she helps developers learn about generative AI. Outside of work, she also shares her learnings in data science and ML on her blog and on Kaggle.
 Meor Amer is a Developer Advocate at Cohere, a provider of cutting-edge natural language processing (NLP) technology. He helps developers build cutting-edge applications with Cohere’s Large Language Models (LLMs).
Meor Amer is a Developer Advocate at Cohere, a provider of cutting-edge natural language processing (NLP) technology. He helps developers build cutting-edge applications with Cohere’s Large Language Models (LLMs).
 Shun Mao is a Senior AI/ML Partner Solutions Architect in the Emerging Technologies team at Amazon Web Services. He is passionate about working with enterprise customers and partners to design, deploy and scale AI/ML applications to derive their business values. Outside of work, he enjoys fishing, traveling and playing Ping-Pong.
Shun Mao is a Senior AI/ML Partner Solutions Architect in the Emerging Technologies team at Amazon Web Services. He is passionate about working with enterprise customers and partners to design, deploy and scale AI/ML applications to derive their business values. Outside of work, he enjoys fishing, traveling and playing Ping-Pong.
Author: James Yi