

Build RAG applications using Jina Embeddings v2 on Amazon SageMaker JumpStart
Today, we are excited to announce that the Jina Embeddings v2 model, developed by Jina AI, is available for customers through Amazon SageMaker JumpStart to deploy with one click for running model inference… This state-of-the-art model supports an impressive 8,192-tokens context length… You can d…
Today, we are excited to announce that the Jina Embeddings v2 model, developed by Jina AI, is available for customers through Amazon SageMaker JumpStart to deploy with one click for running model inference. This state-of-the-art model supports an impressive 8,192-tokens context length. You can deploy this model with SageMaker JumpStart, a machine learning (ML) hub with foundation models, built-in algorithms, and pre-built ML solutions that you can deploy with just a few clicks.
Text embedding refers to the process of transforming text into numerical representations that reside in a high-dimensional vector space. Text embeddings have a broad range of applications in enterprise artificial intelligence (AI), including the following:
- Multimodal search for ecommerce
- Content personalization
- Recommender systems
- Data analytics
Jina Embeddings v2 is a state-of-the-art collection of text embedding models, trained by Berlin-based Jina AI, that boast high performance on several public benchmarks.
In this post, we walk through how to discover and deploy the jina-embeddings-v2 model as part of a Retrieval Augmented Generation (RAG)-based question answering system in SageMaker JumpStart. You can use this tutorial as a starting point for a variety of chatbot-based solutions for customer service, internal support, and question answering systems based on internal and private documents.
What is RAG?
RAG is the process of optimizing the output of a large language model (LLM) so it references an authoritative knowledge base outside of its training data sources before generating a response.
LLMs are trained on vast volumes of data and use billions of parameters to generate original output for tasks like answering questions, translating languages, and completing sentences. RAG extends the already powerful capabilities of LLMs to specific domains or an organization’s internal knowledge base, all without the need to retrain the model. It’s a cost-effective approach to improving LLM output so it remains relevant, accurate, and useful in various contexts.
What does Jina Embeddings v2 bring to RAG applications?
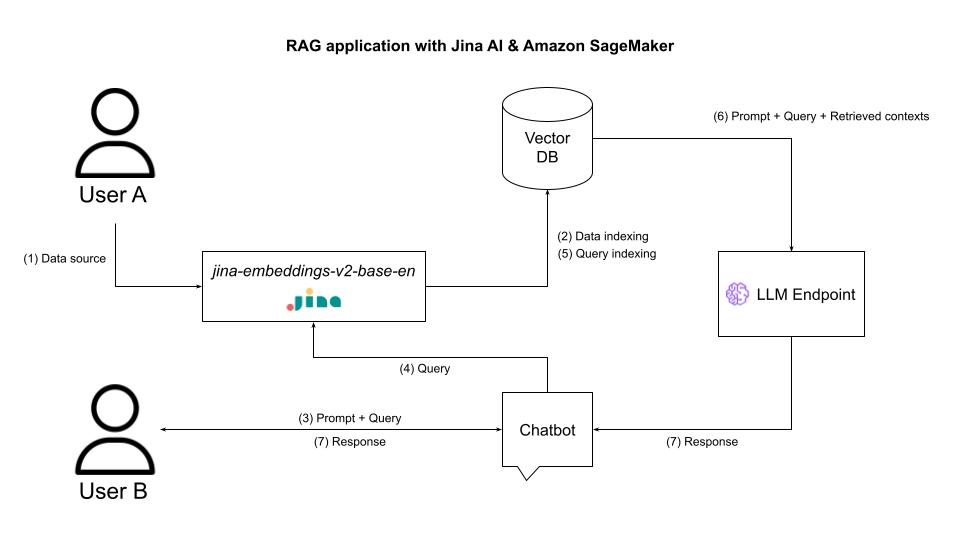
A RAG system uses a vector database to serve as a knowledge retriever. It must extract a query from a user’s prompt and send it to a vector database to reliably find as much semantic information as possible. The following diagram illustrates the architecture of a RAG application with Jina AI and Amazon SageMaker.

Jina Embeddings v2 is the preferred choice for experienced ML scientists for the following reasons:
- State-of-the-art performance – We have shown on various text embedding benchmarks that Jina Embeddings v2 models excel on tasks such as classification, reranking, summarization, and retrieval. Some of the benchmarks demonstrating their performance are MTEB, an independent study of combining embedding models with reranking models, and the LoCo benchmark by a Stanford University group.
- Long input-context length – Jina Embeddings v2 models support 8,192 input tokens. This makes the models especially powerful at tasks such as clustering for long documents like legal text or product documentation.
- Support for bilingual text input – Recent research shows that multilingual models without specific language training show strong biases towards English grammatical structures in embeddings. Jina AI’s bilingual embedding models include
jina-embeddings-v2-base-de,jina-embeddings-v2-base-zh,jina-embeddings-v2-base-es, andjina-embeddings-v2-base-code. They were trained to encode texts in a combination of English-German, English-Chinese, English-Spanish, and English-Code, respectively, allowing the use of either language as the query or target document in retrieval applications. - Cost-effectiveness of operating – Jina Embeddings v2 provides high performance on information retrieval tasks with relatively small models and compact embedding vectors. For example,
jina-embeddings-v2-base-dehas a size of 322 MB with a performance score of 60.1%. A smaller vector size means a great amount of cost savings while storing them in a vector database.
What is SageMaker JumpStart?
With SageMaker JumpStart, ML practitioners can choose from a growing list of best-performing foundation models. Developers can deploy foundation models to dedicated SageMaker instances within a network-isolated environment, and customize models using SageMaker for model training and deployment.
You can now discover and deploy a Jina Embeddings v2 model with a few clicks in Amazon SageMaker Studio or programmatically through the SageMaker Python SDK, enabling you to derive model performance and MLOps controls with SageMaker features such as Amazon SageMaker Pipelines and Amazon SageMaker Debugger. With SageMaker JumpStart, the model is deployed in an AWS secure environment and under your VPC controls, helping provide data security.
Jina Embeddings models are available in AWS Marketplace so you can integrate them directly into your deployments when working in SageMaker.
AWS Marketplace enables you to find third-party software, data, and services that run on AWS and manage them from a centralized location. AWS Marketplace includes thousands of software listings and simplifies software licensing and procurement with flexible pricing options and multiple deployment methods.
Solution overview
We’ve prepared a notebook that constructs and runs a RAG question answering system using Jina Embeddings and the Mixtral 8x7B LLM in SageMaker JumpStart.
In the following sections, we give you an overview of the main steps needed to bring a RAG application to life using generative AI models on SageMaker JumpStart. Although we omit some of the boilerplate code and installation steps in this post for reasons of readability, you can access the full Python notebook to run yourself.
Connecting to a Jina Embeddings v2 endpoint
To start using Jina Embeddings v2 models, complete the following steps:
- In SageMaker Studio, choose JumpStart in the navigation pane.
- Search for “jina” and you will see the provider page link and models available from Jina AI.
- Choose Jina Embeddings v2 Base – en, which is Jina AI’s English language embeddings model.

- Choose Deploy.

- In the dialog that appears, choose Subscribe, which will redirect you to the model’s AWS Marketplace listing, where you can subscribe to the model after accepting the terms of usage.
- After subscribing, return to the Sagemaker Studio and choose Deploy.

- You will be redirected to the endpoint configuration page, where you can select the instance most suitable for your use case and provide a name for the endpoint.
- Choose Deploy.





After you create the endpoint, you can connect to it with the following code snippet:
Preparing a dataset for indexing
In this post, we use a public dataset from Kaggle (CC0: Public Domain) that contains audio transcripts from the popular YouTube channel Kurzgesagt – In a Nutshell, which has over 20 million subscribers.
Each row in this dataset contains the title of a video, its URL, and the corresponding text transcript.
Enter the following code:
Because the transcript of these videos can be quite long (around 10 minutes), in order to find only the relevant content for answering users’ questions and not other parts of the transcripts that are unrelated, you can chunk each of these transcripts before indexing them:
The parameter max_words defines the maximum number of full words that can be in a chunk of indexed text. Many chunking strategies exist in academic and non-peer-reviewed literature that are more sophisticated than a simple word limit. However, for the purpose of simplicity, we use this technique in this post.
Index text embeddings for vector search
After you chunk the transcript text, you obtain embeddings for each chunk and link each chunk back to the original transcript and video title:
The dataframe df contains a column titled embeddings that can be put into any vector database of your choice. Embeddings can then be retrieved from the vector database using a function such as find_most_similar_transcript_segment(query, n), which will retrieve the n closest documents to the given input query by a user.
Prompt a generative LLM endpoint
For question answering based on an LLM, you can use the Mistral 7B-Instruct model on SageMaker JumpStart:
Query the LLM
Now, for a query sent by a user, you first find the semantically closest n chunks of transcripts from any video of Kurzgesagt (using vector distance between embeddings of chunks and the users’ query), and provide those chunks as context to the LLM for answering the users’ query:
Based on the preceding question, the LLM might respond with an answer such as the following:
Based on the provided context, it does not seem that individuals can solve climate change solely through their personal actions. While personal actions such as using renewable energy sources and reducing consumption can contribute to mitigating climate change, the context suggests that larger systemic changes are necessary to address the issue fully.
Clean up
After you’re done running the notebook, make sure to delete all the resources that you created in the process so your billing is stopped. Use the following code:
Conclusion
By taking advantage of the features of Jina Embeddings v2 to develop RAG applications, together with the streamlined access to state-of-the-art models on SageMaker JumpStart, developers and businesses are now empowered to create sophisticated AI solutions with ease.
Jina Embeddings v2’s extended context length, support for bilingual documents, and small model size enables enterprises to quickly build natural language processing use cases based on their internal datasets without relying on external APIs.
Get started with SageMaker JumpStart today, and refer to the GitHub repository for the complete code to run this sample.
Connect with Jina AI
Jina AI remains committed to leadership in bringing affordable and accessible AI embeddings technology to the world. Our state-of-the-art text embedding models support English and Chinese and soon will support German, with other languages to follow.
For more information about Jina AI’s offerings, check out the Jina AI website or join our community on Discord.
About the Authors
 Francesco Kruk is Product Managment intern at Jina AI and is completing his Master’s at ETH Zurich in Management, Technology, and Economics. With a strong business background and his knowledge in machine learning, Francesco helps customers implement RAG solutions using Jina Embeddings in an impactful way.
Francesco Kruk is Product Managment intern at Jina AI and is completing his Master’s at ETH Zurich in Management, Technology, and Economics. With a strong business background and his knowledge in machine learning, Francesco helps customers implement RAG solutions using Jina Embeddings in an impactful way.
 Saahil Ognawala is Head of Product at Jina AI based in Munich, Germany. He leads the development of search foundation models and collaborates with clients worldwide to enable quick and efficient deployment of state-of-the-art generative AI products. With an academic background in machine learning, Saahil is now interested in scaled applications of generative AI in the knowledge economy.
Saahil Ognawala is Head of Product at Jina AI based in Munich, Germany. He leads the development of search foundation models and collaborates with clients worldwide to enable quick and efficient deployment of state-of-the-art generative AI products. With an academic background in machine learning, Saahil is now interested in scaled applications of generative AI in the knowledge economy.
 Roy Allela is a Senior AI/ML Specialist Solutions Architect at AWS based in Munich, Germany. Roy helps AWS customers—from small startups to large enterprises—train and deploy large language models efficiently on AWS. Roy is passionate about computational optimization problems and improving the performance of AI workloads.
Roy Allela is a Senior AI/ML Specialist Solutions Architect at AWS based in Munich, Germany. Roy helps AWS customers—from small startups to large enterprises—train and deploy large language models efficiently on AWS. Roy is passionate about computational optimization problems and improving the performance of AI workloads.
Author: Francesco Kruk