

Build reliable AI agents with Amazon Bedrock AgentCore Evaluations
Your AI agent worked in the demo, impressed stakeholders, handled test scenarios, and seemed ready for production… The result is a gap between expected agent behavior and actual user experience in production… This means that you must test each scenario repeatedly to understand your agent’s ac…
Your AI agent worked in the demo, impressed stakeholders, handled test scenarios, and seemed ready for production. Then you deployed it, and the picture changed. Real users experienced wrong tool calls, inconsistent responses, and failure modes nobody anticipated during testing.
The result is a gap between expected agent behavior and actual user experience in production. Agent evaluation introduces challenges that traditional software testing wasn’t designed to handle. Because large language models (LLMs) are non-deterministic, the same user query can produce different tool selections, reasoning paths, and outputs across multiple runs. This means that you must test each scenario repeatedly to understand your agent’s actual behavior patterns. A single test pass tells you what can happen, not what typically happens. Without systematic measurement across these variations, teams are trapped in cycles of manual testing and reactive debugging. This burns through API costs without clear insight into whether changes improve agent performance. This uncertainty makes every prompt modification risky and leaves a fundamental question unanswered: “Is this agent actually better now?”
In this post, we introduce Amazon Bedrock AgentCore Evaluations, a fully managed service for assessing AI agent performance across the development lifecycle. We walk through how the service measures agent accuracy across multiple quality dimensions. We explain the two evaluation approaches for development and production and share practical guidance for building agents you can deploy with confidence.
Why agent evaluation requires a new approach
When a user sends a request to an agent, multiple decisions happen in sequence. The agent determines which tools (if any) to call, executes those calls, and generates a response based on the results. Each step introduces potential failure points: selecting the wrong tool, calling the right tool with incorrect parameters, or synthesizing tool outputs into an inaccurate final answer. Unlike traditional applications where you test a single function’s output, agent evaluation requires measuring quality across this entire interaction flow.
This creates specific challenges for agent developers that can be addressed by doing the following:
- Define evaluation criteria on what constitutes a correct tool selection, valid tool parameters, an accurate response, and a helpful user experience.
- Build test datasets that represent real user requests and expected behaviors.
- Choose scoring methods that can assess quality consistently across repeated runs.
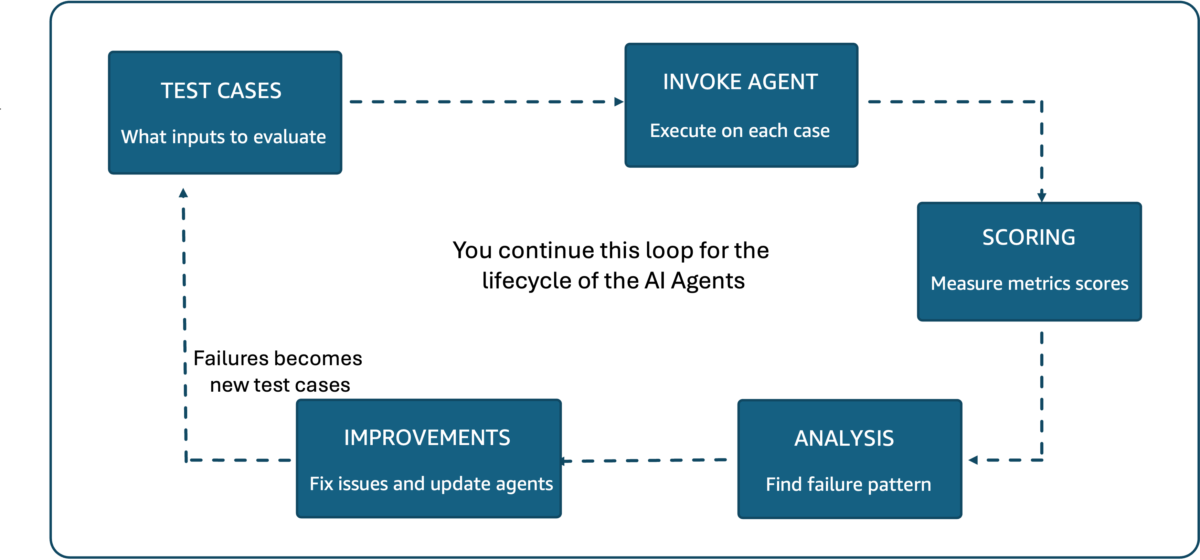
Each of these definitions directly determines what your evaluation system measures and getting them wrong means optimizing for the wrong outcomes. Without this foundational work, the gap between what teams hope their agents do and what they can prove their agents do becomes a real business risk.Bridging this gap requires a continuous evaluation cycle, as shown in Figure 1. Teams build test cases, run them against the agent, score the results, analyze failures, and implement improvements. Each failure becomes a new test case, and the cycle continues through every iteration of the agent.
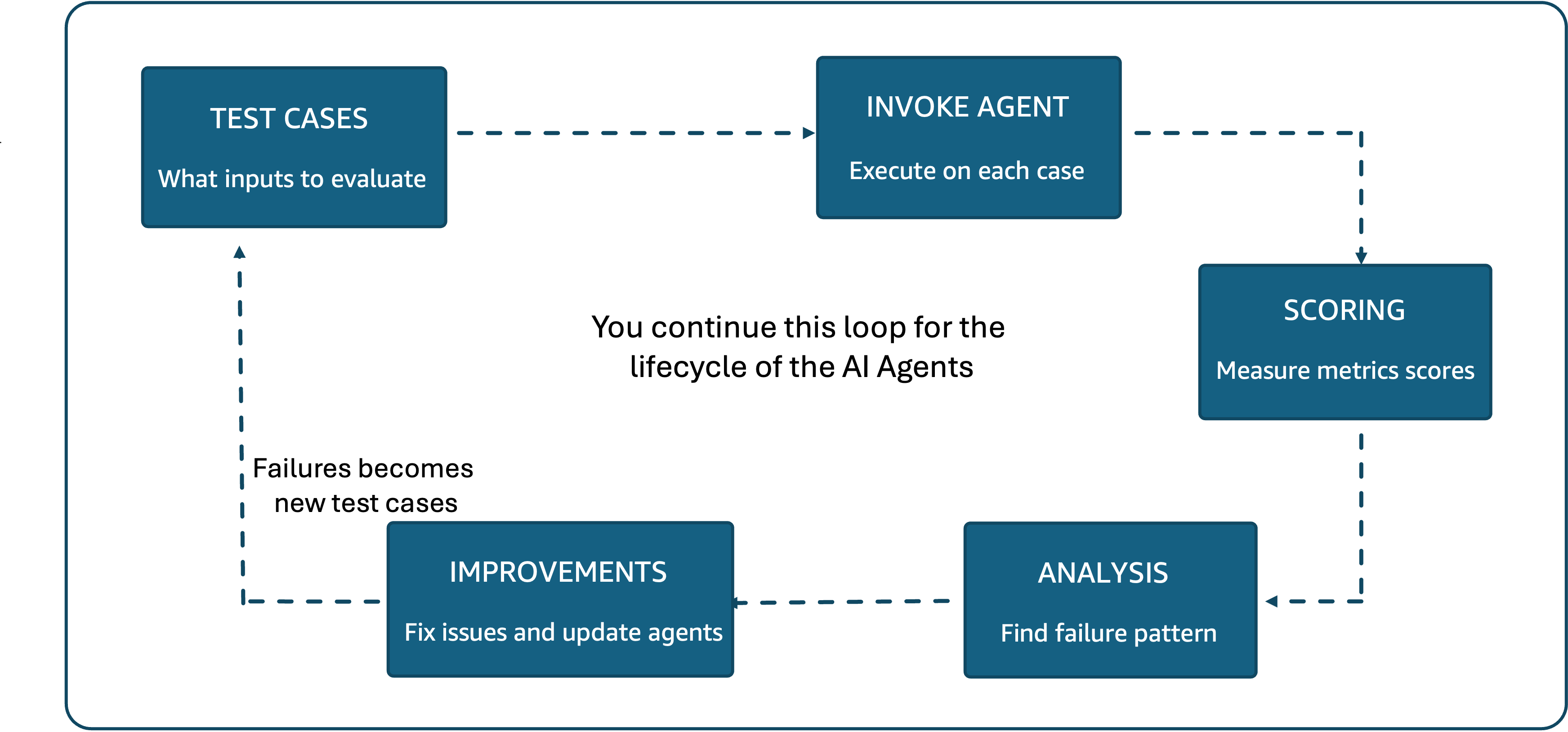
Figure 1: The agent evaluation process follows a continuous cycle of test cases, agent execution, scoring, analysis, and improvements. Failures become new test cases.
Running this cycle end to end, however, requires significant infrastructure beyond the evaluation logic itself. Teams must curate datasets, select and host scoring models, manage inference capacity and API rate limits, build data pipelines that transform agent traces into evaluation-ready formats, and create dashboards to visualize trends. For organizations running multiple agents, this overhead multiplies with each one. The result is that agent developer teams end up spending more time maintaining evaluation tooling than acting on what it tells them. This is the problem Amazon Bedrock AgentCore Evaluations was built to address.
Introducing Amazon Bedrock AgentCore Evaluations
First launched in public preview at AWS re:Invent 2025, the service is now generally available. It handles the evaluation models, inference infrastructure, data pipelines, and scaling so teams can focus on improving agent quality rather than building and maintaining evaluation systems. For built-in evaluators, model quota and inference capacity are fully managed. This means that organizations evaluating many agents aren’t consuming their own quotas or provisioning separate infrastructure for evaluation workloads.
AgentCore Evaluations examine agent behavior end-to-end using OpenTelemetry (OTEL) traces with generative AI semantic conventions. OTEL is an open source observability standard for collecting distributed traces from applications. The generative AI semantic conventions extend it with fields specific to language model interactions, including prompts, completions, tool calls, and model parameters. By building on this standard, the service works consistently across agents built with any Strands Agents or LangGraph, and instrumented with OpenTelemetry and OpenInference, capturing the full context needed for meaningful evaluation.
The evaluations can be configured with different approaches:
- LLM-as-a-Judge where an LLM evaluates each agent interaction against structured rubrics with clearly defined criteria.
- Ground Truth based evaluation can be used to compare the agent responses against pre-defined or simulated datasets.
- Custom code evaluators where you can bring in a Lambda as a evaluator with your own custom code.
In the LLM-as-a-Judge approach, the Judge model examines the full interaction context, including conversation history, available tools, tools used, parameters passed, and system instructions, then provides detailed reasoning before assigning a score. Every score comes with an explanation. Teams can use these scores to verify judgments, understand exactly why an interaction received a particular rating, and identify what should have happened differently. This approach goes beyond simple pass/fail judgments, providing the structured evaluation and transparent reasoning that enable quality assessment at a scale that manual review cannot match.
Three principles guide how the service approaches evaluation. Evidence-driven development replaces intuition with quantitative metrics, so teams can measure the actual impact of changes rather than debating whether a prompt modification “feels better.” Multi-dimensional assessment evaluates different aspects of agent behavior independently. This makes it possible to pinpoint exactly where improvements are needed rather than relying on a single aggregate score. Continuous measurement connects the performance baselines established during development directly to production monitoring, making sure that quality holds up as real-world conditions evolve. These principles apply throughout the agent lifecycle, from the first round of development testing through ongoing production monitoring.
Evaluation across the agent lifecycle
An agent’s journey from prototype to production creates two distinct evaluation needs. During development, teams need controlled environments where they can compare alternatives, test the agent on curated datasets, reproduce results, and validate changes before they reach users. After the agent is live, the challenge shifts to monitoring real-world interactions at scale, where users encounter edge cases and interaction patterns that no amount of pre-deployment testing anticipated. Figure 2 illustrates how evaluation supports each stage of this journey, from initial proof of concept through shadow testing, A/B testing, and continuous production monitoring.
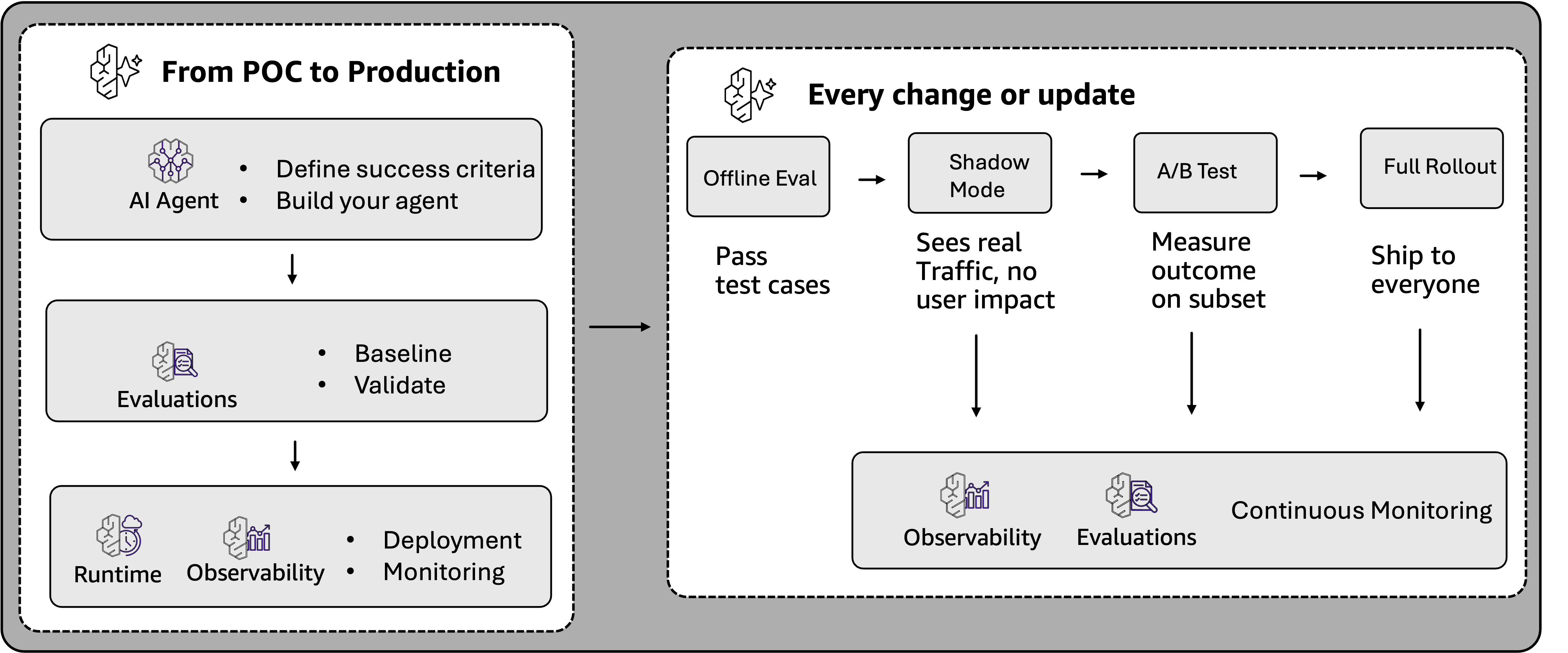
Figure 2: From POC to production, evaluation validates agents before deployment. As agents mature, evaluation supports shadow testing, A/B testing, and continuous monitoring at scale.
AgentCore Evaluations map two complementary approaches to these lifecycle phases, as shown in Figure 3. Online evaluation handles continuous production monitoring, while on-demand evaluation supports controlled testing during development and continuous integration and continuous delivery (CI/CD) workflows, including evaluations against ground truth.
| On-demand Evaluation | Online Evaluation | |
| Advantages |
|
|
| Use cases |
|
|
Figure 3: Online evaluation monitors production traffic continuously, while on-demand evaluation supports controlled testing during development.
Online evaluation for production monitoring
Online evaluation monitors live agent interactions by continuously sampling a configurable percentage of traces and scoring them against your chosen evaluators. You define which evaluators to apply, set sampling rules that control what fraction of production traffic gets evaluated, and set up appropriate filters. The service handles reading traces, running evaluations, and surfacing results in the AgentCore Observability dashboard powered by Amazon CloudWatch. If you’re already collecting traces for observability, online evaluation adds quality scores with explanation, alongside your existing operational metrics without requiring code changes or re-deployments. Figure 4 shows how this process works.
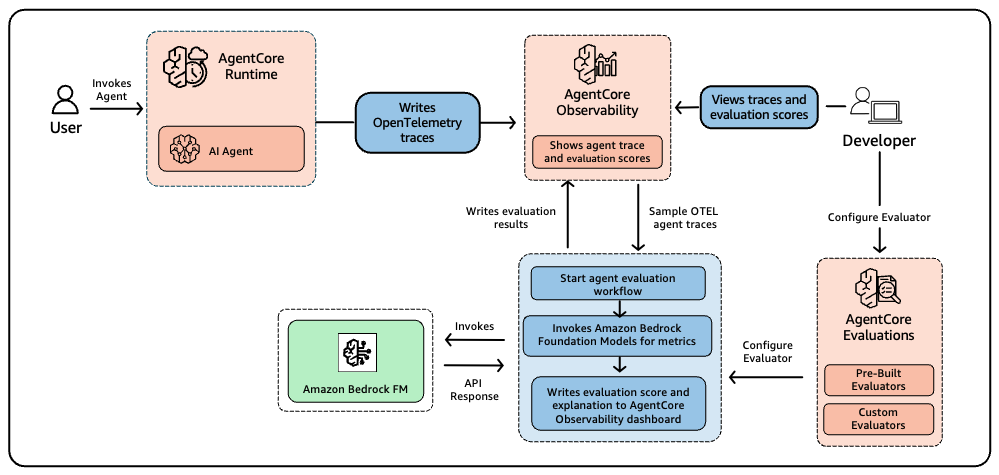
Quality issues in production often surface in ways that traditional monitoring misses. Operational dashboards may show green across latency and error rates while user experience quietly degrades because the agent starts selecting wrong tools or providing less helpful responses. Continuous quality scoring catches these silent failures by tracking evaluation metrics alongside operational ones. Because AgentCore Observability runs on CloudWatch, you can create custom dashboards and set alarms to get alerted the moment scores drop below your thresholds.
On-demand evaluation for development
On-demand evaluation is a real-time API designed for development and CI/CD workflows. Teams use it to test changes before deployment, run evaluation suites as part of CI/CD pipelines, perform regression testing across builds, and gate deployments on quality thresholds. Developers select a full session and specify exact spans (individual operations within a trace) or traces by providing their IDs. The service considers the full session conversation and scores individual span/traces against the same evaluators used in production. Common use cases include validating prompt changes, comparing model performance across alternatives, and preventing quality regressions.
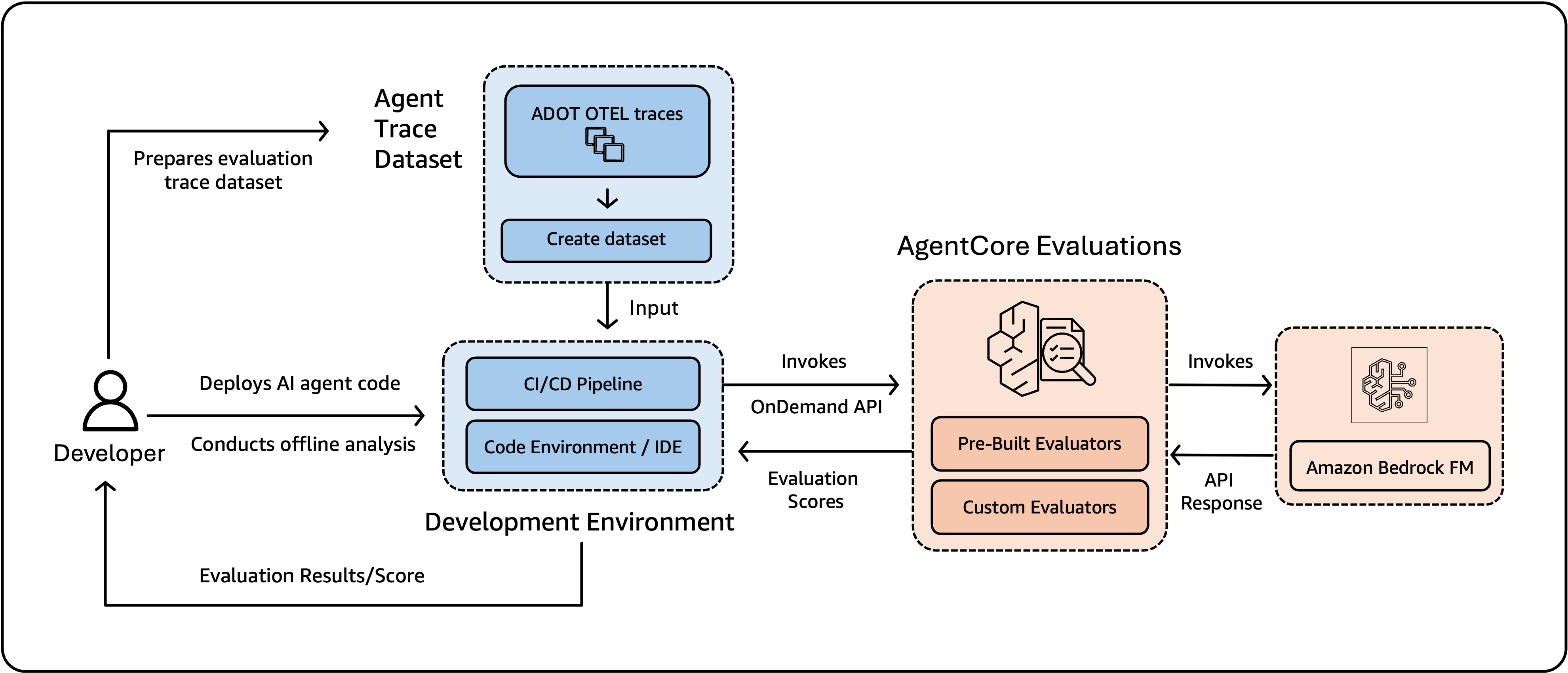
Figure 5: On-demand evaluation enables developers to prepare trace datasets, invoke evaluations through a CI/CD pipeline or development environment, and receive scores using built-in or custom evaluators powered by Amazon Bedrock foundation models.
Because both modes use the same evaluators, what you test in CI/CD is what you monitor in production, giving you consistent quality standards across the entire development lifecycle. On-demand evaluation provides the controlled environment needed for architecture decisions and systematic improvement, while online evaluation maintains quality monitoring continues after the agent is live. Together, the two modes form a continuous feedback loop between development and production, and both draw from the same set of evaluators and scoring infrastructure.
How AgentCore evaluates your agent
AgentCore Evaluations organizes agent interactions into a three-level hierarchy that determines what can be evaluated and at what granularity. A session represents a complete conversation between a user and your agent, grouping all related interactions from a single user or workflow. Within each session, a trace captures everything that happens during a single exchange. When a user sends a message and receives a response, that round trip produces one trace containing every step that the agent took to generate its answer. Each trace in turn contains individual operations called spans, representing specific actions your agent performed, such as invoking a tool, retrieving information from a knowledge base, or generating text.
Different evaluators operate at different levels of this hierarchy, and problems at one level can look very different from problems at another. The service provides 13 pre-configured built-in evaluators organized across these three levels, each measuring a distinct aspect of agent behavior (Figure 6). You can define custom evaluators using LLM-as-a-Judge and custom code evaluators that can work on session, trace and span levels.
| Level | Evaluators | Purpose | Ground Truth Use |
| Session | Goal Success Rate | Assesses whether all user goals were completed within a conversation | User provides free form textual assertions of goal completion, which are compared against system behavior and measured via Goal Success Rate |
| Trace | Helpfulness, Correctness, Coherence, Conciseness, Faithfulness, Harmfulness, Instruction Following, Response Relevance, Context Relevance, Refusal, Stereotyping | Evaluates response quality, accuracy, safety, and communication effectiveness | Turn level ground truth (e.g., expected answer or attributes per turn) supports evaluation of Correctness |
| Tool | Tool Selection Accuracy, Tool Parameter Accuracy | Assesses tool selection decisions and parameter extraction precision | Tool call ground truth specifies the correct tool sequence enabling Trajectory Exact Order Match, Trajectory In-Order Match, and Trajectory Any Order Match |
Figure 6: Built-in evaluators operate at session, trace, and tool levels. Each level measures different aspects of agent behavior. Ground Truth can be provided as assertions, expected response and expected trajectory for evaluation on session, trace and tool level.
Evaluating each level independently helps teams to diagnose whether a problem originates in tool selection, response generation, or session-level planning. An agent might choose the right tool with accurate parameters but then synthesize the tool’s output poorly in its final response. This pattern only becomes visible when each level is assessed on its own. Your agent’s primary purpose guides which evaluators to prioritize. Customer service agents should focus on Helpfulness, Goal Success Rate, and Instruction Following, since resolving user issues within defined guardrails directly impacts satisfaction. Agents with Retrieval Augmented Generation (RAG) components benefit most from Correctness and Faithfulness to make sure that responses are grounded in the provided context. Tool-heavy agents need strong Tool Selection Accuracy and Tool Parameter Accuracy scores. It’s recommended to start with three or four evaluators that align with your agent’s purpose and expand coverage as your understanding matures.
Understanding evaluator distinctions
Some evaluators naturally interact with each other, so scores should be read together rather than in isolation. Evaluators that sound similar often measure fundamentally different things, and understanding these distinctions is important for diagnosis.
- Correctness checks whether the response is factually accurate, while Faithfulness checks whether it is consistent with the conversation history. For example, an agent can be faithful to flawed source material but still wrong.
- Helpfulness asks whether the response advances the user toward their goal, while Response Relevance asks whether it addresses what was originally asked. For example, an agent can answer the wrong question thoroughly.
- Coherence checks for internal contradictions in reasoning, while Context Relevance checks whether the agent had the right information available. For example, one reveals a generation problem, the other a retrieval problem.
Some evaluators also depend on or trade-off against each other. For instance:
- Tool Parameter Accuracy is meaningful only when the agent has selected the correct tool, so low Tool Selection Accuracy should be addressed first.
- Correctness often depends on Context Relevance because an agent cannot generate accurate answers without the right information.
- Conciseness and Helpfulness often conflict because brief responses might omit context that users need.
Built-in evaluators ship with predefined prompt templates, selected evaluator models, and standardized scoring criteria, with configurations fixed to preserve consistency across evaluations. They use cross-Region inference to automatically select compute from AWS Regions within your geography, improving model availability and throughput while keeping data stored in the originating Region. Custom evaluators extend this foundation with support for your own evaluator model, evaluation instructions, criteria, and scoring schema. They’re particularly valuable for industry-specific assessments such as compliance checking in healthcare or financial services, brand voice consistency verification, or enforcing organizational quality standards. Custom code evaluators let you bring in an AWS Lambda function to perform the evaluations. This allows you to also create deterministic scoring of your agents.
For use cases requiring all processing within a single Region, custom evaluators also provide full control over inference configuration. When building a custom evaluator, you define instructions with placeholders that get replaced with actual trace information before being sent to the judge model. The scope of information available depends on the evaluator’s level: a session-level evaluator can access the full conversation context and available tools, a trace-level evaluator sees previous turns plus the current assistant response, and a tool-level evaluator focuses on specific tool calls within their surrounding context. The AWS console provides the option to load the prompt template of any existing built-in evaluator as a starting point, making it straightforward to create custom variants (Figure 7).
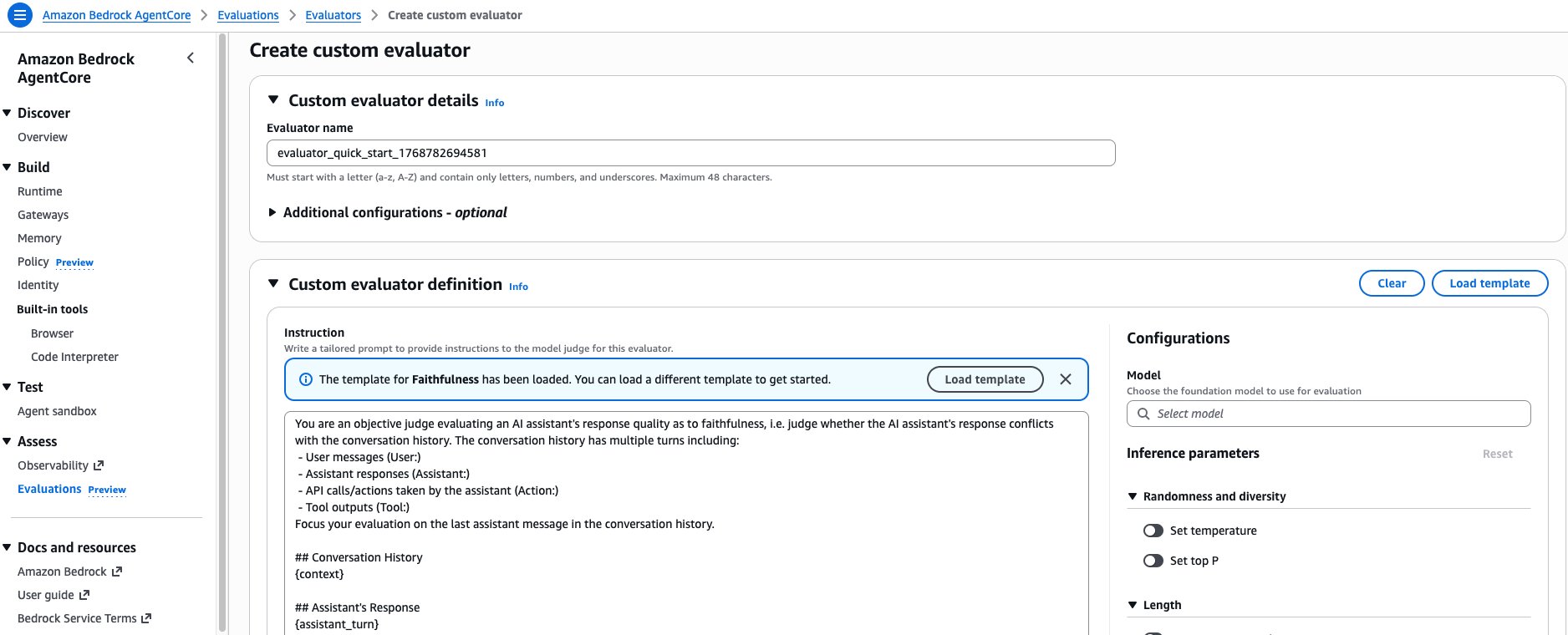
Figure 7: The AgentCore Evaluations console provides the option to load any built-in evaluator’s prompt template as a starting point when creating a custom evaluator.
When building multiple custom evaluators, use the MECE (Mutually Exclusive, Collectively Exhaustive) principle to design your evaluation suite. Each evaluator should have a distinct, non-overlapping scope while collectively covering all quality dimensions you care about. For example, rather than creating two evaluators that both partially assess “response quality,” separate them into one that evaluates factual grounding and another that evaluates communication clarity. Furthermore, to write evaluator instructions, establish the judge model’s role as a performance evaluator to prevent confusion between evaluation and task execution. Use clear, sequential instructions with precise language, and consider including one to three relevant examples with matching input/output pairs that represent your expected standards. For scoring, choose between binary scales (0/1) for pass/fail scenarios or ordinal scales (such as 1–5) for more nuanced assessments, and start with binary scoring when uncertain. The service standardizes output to include a reason field followed by a score field, so the judge model always presents its reasoning before assigning a number. Avoid including your own output formatting instructions, as they can confuse the Judge model.
Custom Code-based evaluators
Built-in and custom evaluators both use an LLM-as-a-Judge. AgentCore Evaluations also supports a third approach: code-based evaluators, where an AWS Lambda function can be used as the evaluator with your custom code.
Code-based evaluators are ideal when you have heuristic scoring methods that don’t require language understanding to verify. An LLM evaluator can judge whether a response “sounds correct,” but it cannot reliably confirm that a specific pay stub figure of $8,333.33 appears verbatim in a response, or that a generated request ID follows the format PTO-2026-NNN. For these deterministic checks, a custom code is faster, cheaper, and more reliable. There are four situations where code-based evaluators are particularly helpful:
- Exact data validation: The agent is expected to return specific values from a data source, such as account balances, transaction IDs, or prices.
- Format compliance: Responses must conform to structural constraints, such as length limits, required phrases, or output schemas.
- Business rule enforcement: Policies that require precise interpretation, such as whether a response correctly applies a tiered discount rule or cites the right regulatory clause.
- High-volume production monitoring: Lambda invocations cost a fraction of LLM inference, making code-based evaluators the right choice when every production session needs to be scored continuously at scale.
Creating a code-based evaluator
A code-based evaluator is configured as an AWS Lambda function with your custom logic. AgentCore passes the agent’s OTel spans to your function as a structured event and expects a result in return. Your function extracts whatever information it needs from the spans and returns a score, a label, and an explanation.
Once your Lambda is deployed and granted permission to be invoked by the AgentCore service principal, you register it as an evaluator for AgentCore. Once registered, the evaluator ID can be used for on-demand evaluation.
Setting up AgentCore Evaluations
Configuring the service involves three steps. Select your agent, choose your evaluators, and set your sampling rules. Before you begin, deploy your agent using AgentCore Runtime and set up observability through OpenTelemetry or OpenInference instrumentation. The AgentCore samples repository on GitHub provides working examples.
Configuring online evaluation
Create a new online evaluation configuration through the AgentCore Evaluations console. Here, you specify which evaluators to apply, which data source to monitor, and what sampling parameters to use. For the data source, select either an existing AgentCore Runtime endpoint or a CloudWatch log group for agents not hosted on AgentCore Runtime. Then choose your evaluators and define your sampling rules.
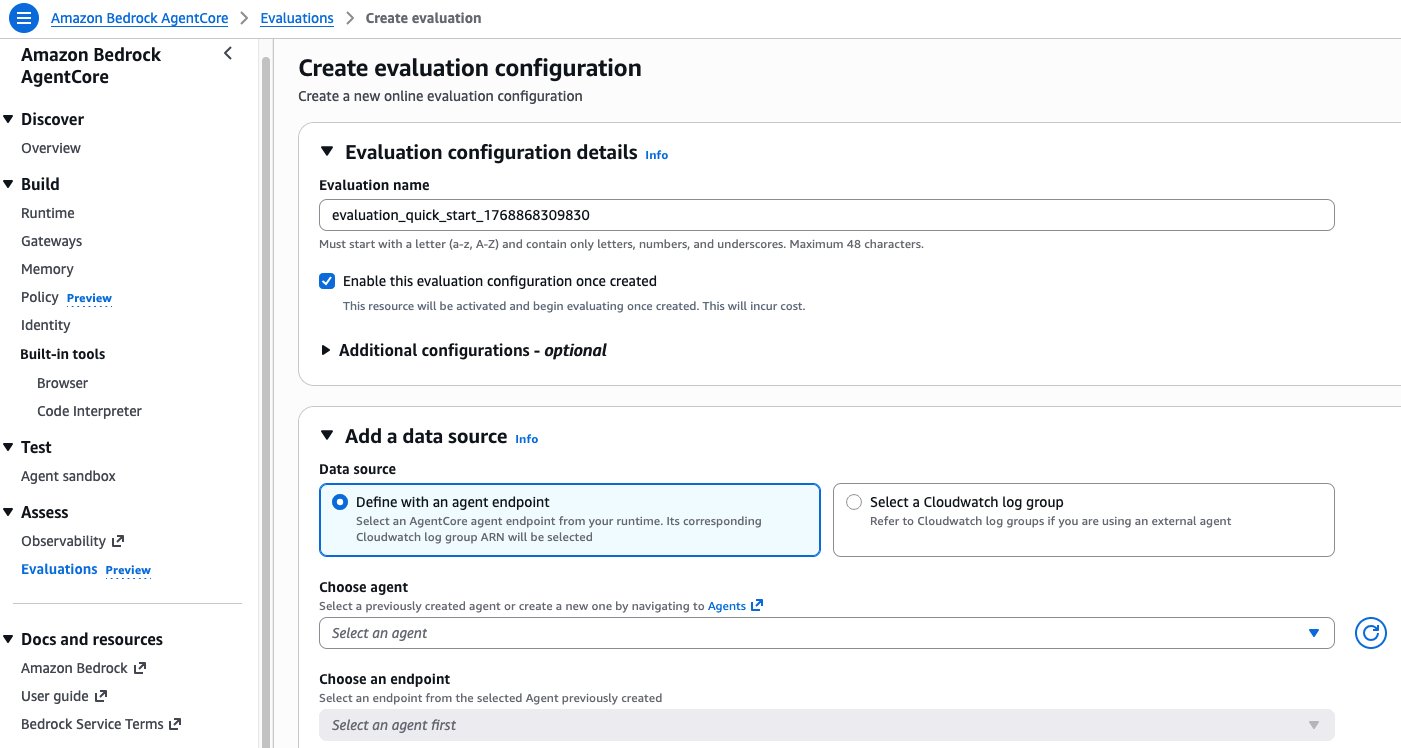
Figure 8: The AgentCore Evaluations console for creating an online evaluation configuration, including data source selection, evaluator assignment, and sampling rules.
You can also create configurations programmatically using the CreateOnlineEvaluationConfig API with a unique configuration name, data source, list of evaluators (up to 10), and IAM service role. The enableOnCreate parameter controls whether evaluation starts immediately or stays paused, and executionStatus determines whether the configuration actively processes traces once enabled. When a configuration is running, any custom evaluators it references become locked and cannot be modified or deleted. If you need to change an evaluator, clone it and create a new version. Online evaluation results are saved to a dedicated CloudWatch log group in JSON format.
Monitoring results
After enabling your configuration, monitor results through the AgentCore Observability dashboard in Amazon CloudWatch. Agent-level views display aggregated evaluation metrics and trends, and you can drill into specific sessions and traces to see individual scores and the reasoning behind each one.
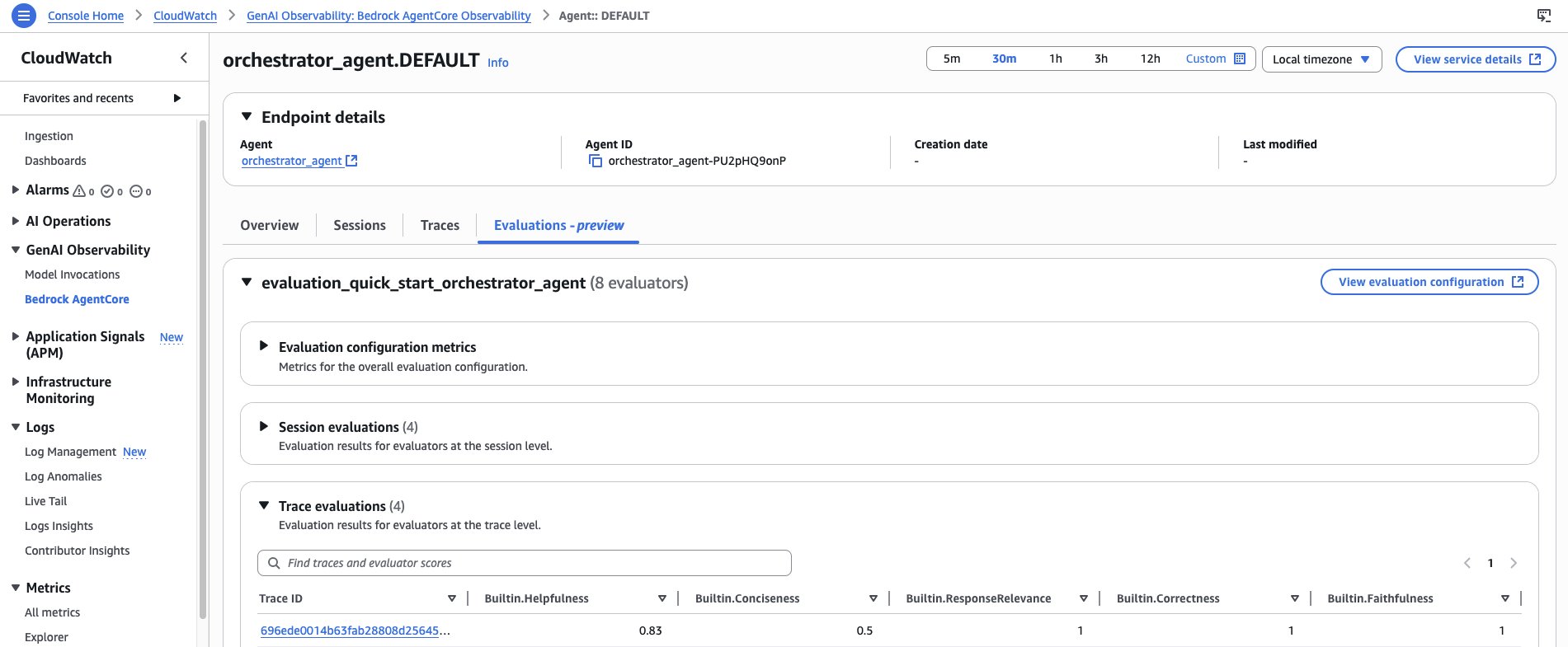
Figure 9: The AgentCore Observability dashboard displays evaluation metrics and trends at the agent level, with drill-down into individual sessions, traces, scores, and judge reasoning.
Drilling into an individual trace reveals the evaluation scores and detailed explanations for that specific interaction, so teams can verify judge reasoning and understand why the agent received a particular rating.
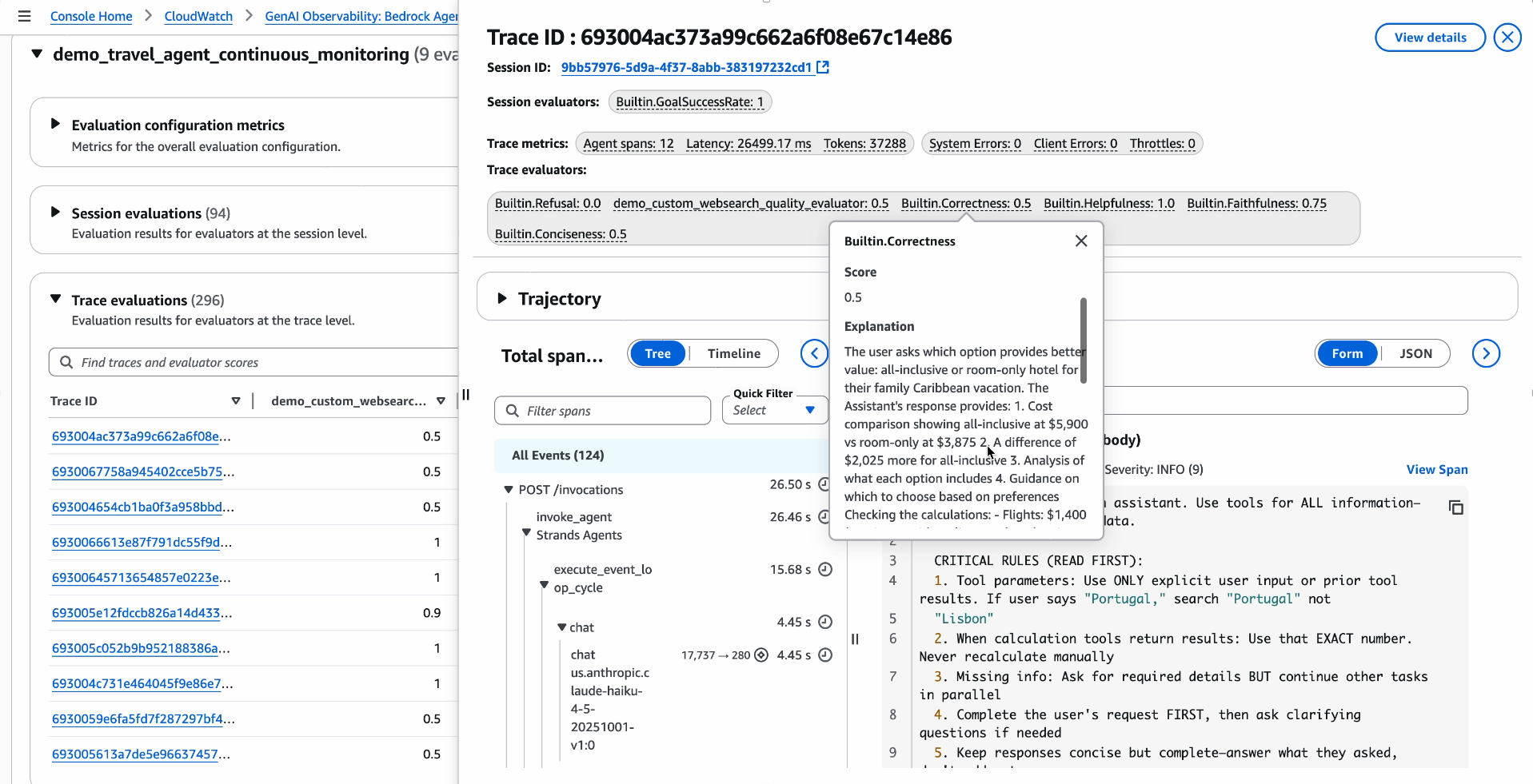
Figure 10: The trace-level view displays evaluation scores and explanations directly on individual traces, showing the judge model’s reasoning for each metric.
Using on-demand evaluation
For development and testing, you can use on-demand evaluation to analyze specific interactions by selecting the traces or spans that you want to examine, applying your chosen evaluators, and receiving detailed scores with explanations. Results return directly in the API response, limited to 10 evaluations per call, with each result containing the span context, score, and reasoning. If an evaluation partially fails, the response includes both successful and failed results with error codes and messages. On-demand evaluation works well for testing custom evaluators, investigating specific quality issues, and validating fixes before deployment.
Evaluating agents with ground truth
LLM-as-judge scoring tells you whether responses seem correct and helpful by the standards of a general-purpose language model. Ground truth evaluation takes this further by letting you specify the answer, the tools that should have been called, and the outcomes the session should have achieved. This helps you measure how closely the agent’s actual behavior matches your reference inputs. This is particularly valuable during development, when you have domain knowledge about what the right behavior is and want to test for specific scenarios.
AgentCore Evaluations supports three types of ground truth reference inputs, each consumed by a specific set of evaluators:
| Reference Input | Evaluator | What it measures |
expected_response | Builtin.Correctness | Similarity between the agent’s response and the known-correct answer |
expected_trajectory | Builtin.TrajectoryExactOrderMatch, Builtin.TrajectoryInOrderMatch, Builtin.TrajectoryAnyOrderMatch | Whether the agent called the right tools in the right sequence |
assertions | Builtin.GoalSuccessRate | Whether the session satisfied a set of natural-language statements about expected outcomes |
These inputs are optional and independent. Evaluators that don’t require ground truth such as Builtin.Helpfulness and Builtin.ResponseRelevance can be included in the same call as ground-truth evaluators, and each evaluator reads only the fields it needs. You can supply all three reference inputs simultaneously for a comprehensive evaluation, or supply only the subset relevant to a given scenario.
The bedrock-agentcore Python SDK provides two interfaces for ground truth evaluation: EvaluationClient for assessing existing sessions and OnDemandEvaluationRunner for automated dataset evaluation.
Evaluation Client: Evaluating existing sessions
Evaluation Client is the right choice when you already have agent sessions recorded in CloudWatch and want to evaluate specific interactions. You provide the session ID, the agent ID, your chosen evaluators, a look back window for CloudWatch span retrieval, and optional Reference Inputs. The client fetches the session’s spans and submits them for evaluation. This is well suited to development analysis, debugging specific agent failures, and validating known interactions after prompt or model changes.
Evaluation Client works equally well for multi-turn sessions. When you pass a session ID from a multi-turn conversation, the client fetches all spans for that session and evaluates the complete dialogue. Trajectory evaluators verify tool usage across all turns, goal success assertions apply to the session, and correctness evaluators score each individual response against its corresponding expected answer.
On-Demand Evaluation Dataset Runner: Automated dataset evaluation
On-Demand Evaluation Dataset Runner is the right choice when you want to evaluate your agent systematically across a curated dataset by invoking the agent for every scenario, collecting CloudWatch spans, and scoring results in a single automated workflow. You define a Dataset containing multi-turn scenarios with per-turn and per-scenario ground truth and provide an agent_invoker function that the runner calls for each turn. The runner manages session IDs and handles all coordination between invocation, span collection, and evaluation.
On-Demand Evaluation Dataset Runner is well suited to CI/CD pipelines where the same dataset runs against every build, regression testing after prompt or model changes, and batch evaluation across a large corpus of test cases before a release.
The two interfaces share the same evaluators and Reference Inputs schema, so you can develop and validate ground truth test cases interactively with Evaluation Client against existing production sessions, then promote those same scenarios into your Evaluation Runner dataset for systematic regression testing. The hands-on tutorial in the AgentCore samples repository demonstrates both interfaces end-to-end using an example agent across single-turn and multi-turn scenarios with all three types of ground truth reference inputs.
Best practices
Success criteria for your agent typically combine three dimensions: the quality of responses, the latency at which users receive them, and the cost of inference. AgentCore Evaluations focuses on the quality dimension, while operational metrics like latency and cost are available through AgentCore Observability in CloudWatch. The following best practices are organized around the three evaluation principles described earlier, and reflect patterns that emerge from working with agent evaluation at scale.
Evidence-driven development
- Baseline your agent’s performance with both synthetic and real-world data, and experiment rigorously. Measure before and after every change so that improvements are grounded in evidence, not intuition. Start testing early with the test cases that you have, and build your corpus continuously. The evaluation loop described in Figure 1 makes sure that failures become new test cases over time.
- Run A/B testing with statistical rigor for every change. Whether you are updating a system prompt, swapping a model, or adding a tool, compare performance across the same evaluator set before and after deployment.
- Run repeated trials (at least 10 per question) organized by category to benchmark reliability and identify specialization opportunities. Variance across repeated runs reveals where your agent is consistent and where it needs work.
Multi-dimensional assessment
- Define what success looks like early, using multi-dimensional criteria that reflect your agent’s actual purpose. Consider which evaluation levels matter most (session, trace, or tool) and select evaluators that map to your business objectives.
- Evaluate every step in the agent’s workflow, not just final outcomes. Measuring tool selection, parameter accuracy, and response quality independently gives you the diagnostic precision to fix problems where they actually occur.
- Involve subject matter experts in designing your metrics, defining task coverage, and conducting human-in-the-loop reviews for quality assurance. SME input keeps your evaluators grounded in real-world expectations and catches blind spots that automated scoring alone can miss.
- Start with built-in evaluators to establish baseline measurements, then create custom evaluators as your needs mature. Calibrate custom evaluator scoring with SMEs for automated judgments align with human expectations in your domain.
Continuous measurement
- Detect drift by comparing production behavior to your test baselines. Set up CloudWatch alarms on key metrics so you catch regressions before they reach a broad set of users.
- Remember that your test dataset evolves with your agent, your users, and the adversarial scenarios you encounter. Update it regularly as edge cases emerge in production and requirements shift.
Troubleshooting common Evaluation patterns
- The evaluator relationships described earlier helps you interpret scores diagnostically. The following patterns are described for specific scenarios you may encounter as you scale your application along with steps to resolve them.
- If you notice low scores across all evaluators, the issue is typically foundational. Start by reviewing Context Relevance scores to determine whether your agent has access to the information it needs. Check your agent’s system prompt for clarity and completeness; vague or contradictory instructions affect every downstream behavior. Verify that tool descriptions accurately explain when and how to use each tool.
- If you notice inconsistent scores for similar interactions, it usually points to evaluation configuration issues rather than agent problems. If you are using custom evaluators, check whether your instructions are specific enough and whether each score level has clear, distinguishable definitions. Consider lowering the temperature parameter in your custom evaluator’s model configuration to produce more deterministic scoring.
- If you see high Tool Selection Accuracy but low Goal Success Rate, your agent selects appropriate tools but fails to complete user objectives. This pattern suggests that you might need additional tools to handle certain user requests, or your agent struggles with tasks requiring multiple sequential tool calls. Check Helpfulness scores as well; the agent might use tools correctly but explain results poorly.
- If evaluations are slow or failing due to throttling, lower your sampling rate to evaluate a smaller percentage of sessions. Reduce your evaluator count. For custom evaluators, request quota increases for your chosen model, or switch to a model with higher default quotas.
Conclusion
In this post, we showed how Amazon Bedrock AgentCore Evaluations helps teams move from reactive debugging to systematic quality management for AI agents. As a fully managed service, it handles the evaluation models, inference infrastructure, and data pipelines that teams would otherwise need to build and maintain for each agent. With on-demand evaluation anchoring the development workflow and online evaluation providing continuous production insight, quality becomes a measurable and improvable property throughout the agent lifecycle. The evaluator relationships and diagnostic patterns give a framework not just to score agents but for understanding where and why quality issues occur and where to focus improvement efforts.
To explore AgentCore Evaluations in detail, watch the public preview launch session from AWS re:Invent 2025 for a walkthrough with live demos. Visit the Amazon Bedrock AgentCore samples repository on GitHub for hands-on tutorials. For technical details on configuration and API usage, see the AgentCore Evaluations documentation. You can also review service limits and pricing.
About the authors
Author: Akarsha Sehwag