

CBRE and AWS perform natural language queries of structured data using Amazon Bedrock
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon with a single API, along with a broad set of capabilities to build generative AI applications, simpl…
This is a guest post co-written with CBRE.
CBRE is the world’s largest commercial real estate services and investment firm, with 130,000 professionals serving clients in more than 100 countries. Services range from financing and investment to property management.
CBRE is unlocking the potential of artificial intelligence (AI) to realize value across the entire commercial real estate lifecycle—from guiding investment decisions to managing buildings. The opportunities to unlock value using AI in the commercial real estate lifecycle starts with data at scale. CBRE’s data environment, with 39 billion data points from over 300 sources, combined with a suite of enterprise-grade technology can deploy a range of AI solutions to enable individual productivity all the way to broadscale transformation. Although CBRE provides customers their curated best-in-class dashboards, CBRE wanted to provide a solution for their customers to quickly make custom queries of their data using only natural language prompts.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon with a single API, along with a broad set of capabilities to build generative AI applications, simplifying development while maintaining privacy and security. With the comprehensive capabilities of Amazon Bedrock, you can experiment with a variety of FMs, privately customize them with your own data using techniques such as fine-tuning and Retrieval Augmented Generation (RAG), and create managed agents that run complex business tasks—from booking travel and processing insurance claims to creating ad campaigns and managing inventory—all without the need to write code. Because Amazon Bedrock is serverless, you don’t have to manage infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with.
In this post, we describe how CBRE partnered with AWS Prototyping to develop a custom query environment allowing natural language query (NLQ) prompts by using Amazon Bedrock, AWS Lambda, Amazon Relational Database Service (Amazon RDS), and Amazon OpenSearch Service. AWS Prototyping successfully delivered a scalable prototype, which solved CBRE’s business problem with a high accuracy rate (over 95%) and supported reuse of embeddings for similar NLQs, and an API gateway for integration into CBRE’s dashboards.
Customer use case
Today, CBRE manages a standardized set of best-in-class client dashboards and reports, powered by various business intelligence (BI) tools, such as Tableau and Microsoft Power BI, and their proprietary UI, enabling CBRE clients to review core metrics and reports on occupancy, rent, energy usage, and more for various properties managed by CBRE.
The company’s Data & Analytics team regularly receives client requests for unique reports, metrics, or insights, which require custom development. CBRE wanted to enable clients to quickly query existing data using natural language prompts, all in a user-friendly environment. The prompts are managed through Lambda functions to use OpenSearch Service and Anthropic Claude 2 on Amazon Bedrock to search the client’s database and generate an appropriate response to the client’s business analysis, including the response in plain English, the reasoning, and the SQL code. A simple UI was developed that encapsulates the complexity and allows users to input questions and retrieve the results directly. This solution can be applied to other dashboards at a later stage.
Key use case and environment requirements
Generative AI is a powerful tool for analyzing and transforming vast datasets into usable summaries and text for end-users. Key requirements from CBRE included:
- Natural language queries (common questions submitted in English) to be used as primary input
- A scalable solution using a large language model (LLM) to generate and run SQL queries for business dashboards
- Queries submitted to the environment that return the following:
- Result in plain English
- Reasoning in plain English
- SQL code generated
- The ability to reuseexisting embeddings of tables, columns, and SQL code if input NLQ is similar to a previous query
- Query response time of 3–5 seconds
- Target 90% “good” responses to queries (based on customer User Acceptance Testing)
- An API management layer for integration into CBRE’s dashboard
- A straightforward UI and frontend for User Acceptance Testing (UAT)
Solution overview
CBRE and AWS Prototyping built an environment that allows a user to submit a query to structured data tables using natural language (in English), based on Anthropic Claude 2 on Amazon Bedrock with support for 100,000 maximum tokens. Embeddings were generated using Amazon Titan. The framework for connecting Anthropic Claude 2 and CBRE’s sample database was implemented using LangChain. AWS Prototyping developed an AWS Cloud Development Kit (AWS CDK) stack for deployment following AWS best practices.
The environment was developed over a period of multiple development sprints. CBRE, in parallel, completed UAT testing to confirm it performed as expected.
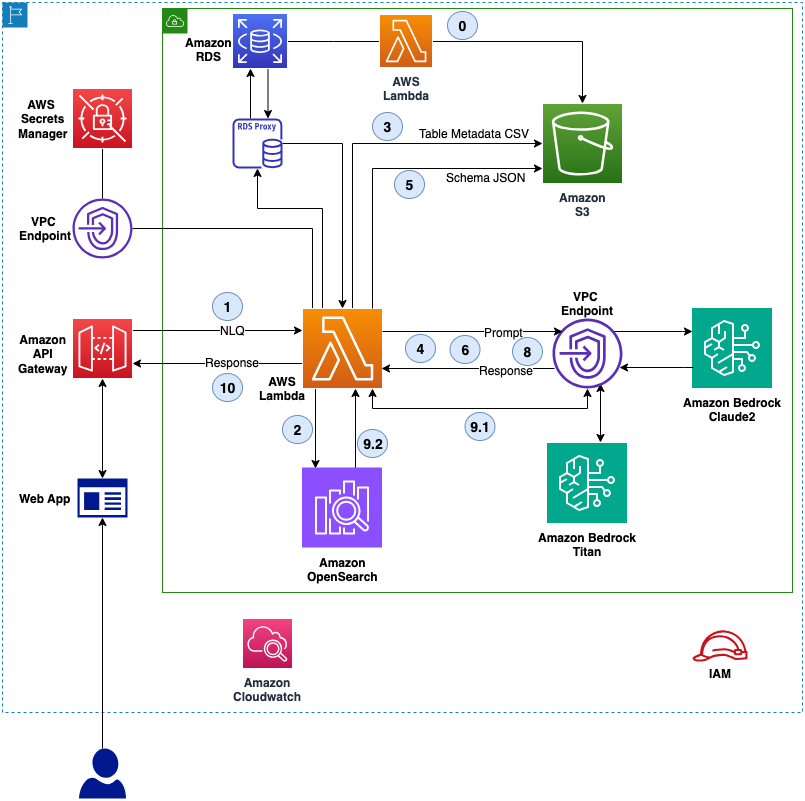
The following figure illustrates the core architecture for the NLQ capability.

The workflow for NLQ consists of the following steps:
- A Lambda function writes schema JSON and table metadata CSV to an S3 bucket.
- A user sends a question (NLQ) as a JSON event.
- The Lambda wrapper function searches for similar questions in OpenSearch Service. If it finds any, it skips to Step 6. If not, it continues to Step 3.
- The wrapper function reads the table metadata from the S3 bucket.
- The wrapper function creates a dynamic prompt template and gets relevant tables using Amazon Bedrock and LangChain.
- The wrapper function selects only relevant tables schema from the schema JSON in the S3 bucket.
- The wrapper function creates a dynamic prompt template and generates a SQL query using Anthropic Claude 2.
- The wrapper function runs the SQL query using psycopg2.
- The wrapper function creates a dynamic prompt template to generate an English answer using Anthropic Claude 2.
- The wrapper function uses Anthropic Claude 2 and OpenSearch Service to do the following:
- It generates embeddings using Amazon Titan.
- It stores the question and SQL query as a vector for reuse in the OpenSearch Service index.
- The wrapper function consolidates the output and returns the JSON output.
Web UI and API management layer
AWS Prototyping built a web interface and API management layer to enable user testing during development and accelerate integration into CBRE’s existing BI capabilities. The following diagram illustrates the web interface and API management layer.

The workflow includes the following steps:
- The user accesses the web portal hosted from their laptop through a web browser.
- A low-latency Amazon CloudFront distribution is used to serve the static site protected by a HTTPS certificate issued by Amazon Certificate Manager (ACM).
- An S3 bucket stores the website-related HTML, CSS, and JavaScript necessary to render the static site. The CloudFront distribution has its origin configured to this S3 bucket and remains in sync to serve the latest version of the site to users.
- Amazon Cognito is used as a primary authentication and authorization provider with its user pools to allow user login, access to the API gateway, and access to the website bucket and response bucket.
- An Amazon API Gateway endpoint with a REST API stage is secured by Amazon Cognito to only allow authenticated entities access to the Lambda function.
- A Lambda function with business logic invokes the primary Lambda function.
- An S3 bucket to store the generated response from the primary Lambda function is queried from the frontend periodically to show on the web application.
- A VPC endpoint is established to isolate the primary Lambda function.
- VPC endpoints for both Lambda and Amazon S3 are imported and configured using the AWS CDK so the frontend stack can have adequate access permissions to reach resources within a VPC.
- AWS Identity and Access Management (IAM) enforces the necessary permissions for the frontend application.
- Amazon CloudWatch captures run logs across various resources, especially Lambda and API Gateway.
Technical approach
Amazon Bedrock is a fully managed service that makes FMs from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. With the Amazon Bedrock serverless experience, you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage any infrastructure.
Anthropic Claude 2 on Amazon Bedrock, a general-purpose LLM with 100,000 maximum token support, was selected to support the solution. LLMs demonstrate impressive abilities in automatically generating code. Relevant metadata can help guide the model’s output and in customizing SQL code generation for specific use cases. AWS offers tools like AWS Glue crawlers to automatically extract technical metadata from data sources. Business metadata can be constructed using services like Amazon DataZone. A lightweight approach was taken to quickly build the required technical and business catalogs using custom scripts. The metadata primed the model to generate tailored SQL code aligned with our database schema and business needs.
Input context files are needed for the Anthropic Claude 2 model to generate a SQL query according to the NLQ:
- meta.csv – This is human-written metadata in a CSV file stored in an S3 bucket, which includes the names of the tables in the schema and a description for each table. The
meta.csvfile is sent as an input context to the model (refer to steps 3 and 4 in the end-to-end solution architecture diagram) to find the relevant tables according to the input NLQ. The S3 location ofmeta.csvis as follows: - schema.json – This JSON schema is generated by a Lambda function and stored in Amazon S3. Following steps 5 and 6 in the architecture, the relevant tables schema is sent as input context to the model to generate a SQL query according to the input NLQ. The S3 location of
schem.jsonis as follows:
DB schema generator Lambda function
This function needs to be invoked manually. The following configurable environmental variables are managed by the AWS CDK during the deployment of this Lambda function:
- dbSchemaGeneratorBucket – S3 bucket for
schema.json - secretManagerKey – AWS Secrets Manager key for DB credentials
- secretManagerRegion – AWS Region in which the Secrets Manager key exists
After a successful run, schema.json is written in an S3 bucket.
Lambda wrapper function
This is the core component of the solution, which performs steps 2 through 10 as described in the end-to-end solution architecture. The following figure illustrates its code structure and workflow.

It runs the following scripts:
- index.py – The Lambda handler (main) handles input/output and runs functions based on keys in the input context
- langchain_bedrock.py – Get relevant tables, generate SQL queries, and convert SQL to English using Anthropic Claude 2
- opensearch.py – Retrieve similar embeddings with existing index or generate new embeddings in OpenSearch Service
- sql.py – Run SQL queries using pyscopg2 and the
opensearch.pymodule - boto3_bedrock.py – The Boto3 client for Amazon Bedrock
- utils.py – The utilities function includes the OpenSearch Service client, Secrets Manager client, and formatting the final output response
The Lambda wrapper function has two layers for the dependencies:
- LangChain layer – pip modules and dependencies of LangChain, boto3, and psycopg2
- OpenSearch Service layer – OpenSearch Service Python client dependencies
AWS CDK manages the following configurable environmental variables during wrapper function deployment:
- dbSchemaGeneratorBucket – S3 bucket for
schema.json - opensearchDomainEndpoint – OpenSearch Service endpoint
- opensearchMasterUserSecretKey – Secret key name for OpenSearch Service credentials
- secretManagerKey – Secret key name for Amazon RDS credentials
- secretManagerRegion – Region in which Secrets Manager key exists
The following code illustrates the JSON format for an input event:
It contains the following parameters:
input_queriesis a list of NLQ questions with a range of 1 to X integer. If there is more than one NLQ, those are added as follow-up questions to the first NLQ.- The
useVectorDBkey defines if OpenSearch Service is to be used as the vector database. If 0, it will run the end-to-end workflow without searching for similar embeddings in OpenSearch Service. If 1, it searches for similar embeddings. If similar embeddings are available, it directly runs the SQL code, otherwise it performs inference with the model. By default,useVectorDBis set to 1, and therefore this key is optional. - The S3OutBucket and S3OutPrefix keys are optional. These keys represent the S3 output location of the JSON response. These are primarily used by the frontend in asynchronous mode.
The following code illustrates the JSON format for an output response:
statusCode 200 indicates a successful run of the Lambda function; statusCode 400 indicates a failure with error.
Performance tuning approach
Performance tuning is an iterative approach across multiple layers. In this section, we discuss a performance tuning approach for this solution.
Input context for RAG
LLMs are mostly trained on general domain corpora, making them less effective on domain-specific tasks. In this scenario, when the expectation is to generate SQL queries based on a PostgreSQL DB schema, the schema becomes our input context to an LLM to generate a context-specific SQL query. In our solution, two input context files are critical for the best output, performance, and cost:
- Get relevant tables – Because the entire PostgreSQL DB schema’s context length is high (over 16,000 tokens for our demo database), it’s necessary to include only the relevant tables in the schema rather than the entire DB schema with all tables to reduce the input context length of the model, which impacts not only the quality of the generated content, but also performance and cost. Because choosing the right tables according to the NLQ is a crucial step, it’s highly recommended to describe the tables in detail in
meta.csv. - DB schema –
schema.jsonis generated by the schema generator Lambda function, saved in Amazon S3, and passed as input context. It includes column names, data type, distinct values, relationships, and more. The output quality of the LLM-generated SQL query is highly dependent on the detailed schema. Input context length for each table’s schema for demo is between 2,000–4,000 tokens. A more detailed schema may provide fine results, but it’s also necessary to optimize the context length for performance and cost. As part of our solution, we already optimized the DB schema generator Lambda function to balance detailed schema and input context length. If required, you can further optimize the function depending on the complexity of the SQL query to be generated to include more details (for example, column metadata).
Prompt engineering and instruction tuning
Prompt engineering allows you to design the input to an LLM in order to generate an optimized output. A dynamic prompt template is created according to the input NLQ using LangChain (refer to steps 4, 6, and 8 in the end-to-end solution architecture). We combine the input NLQ (prompt) along with a set of instructions for the model to generate the content. It is necessary to optimize both the input NLQ and the instructions within the dynamic prompt template:
- With prompt tuning, it’s vital to be descriptive of newer NLQs for the model to understand and generate a relevant SQL query.
- For instruction tuning, the functions
dyn_prompt_get_table,gen_sql_query, andsql_to_englishinlangchain_bedrock.pyof the Lambda wrapper function have a set of purpose-specific instructions. These instructions are optimized for best performance and can be further optimized depending on the complexity of the SQL query to be generated.
Inference parameters
Refer to Inference parameters for foundation models for more information on model inference parameters to influence the response generated by the model. We’ve used the following parameters specific to different inference steps to control maximum tokens to sample, randomness, probability distribution, and cutoff based on the sum of probabilities of the potential choices.
The following parameters specify to get relevant tables and output a SQL-to-English response:
The following parameters generate the SQL query:
Monitoring
You can monitor the solution components through Amazon CloudWatch logs and metrics. For example, the Lambda wrapper’s logs are available on the Log groups page of the CloudWatch console (cbre-wrapper-lambda-<account ID>-us-east-1), and provide step-by-step logs throughout the workflow. Similarly, Amazon Bedrock metrics are available by navigating to Metrics, Bedrock on the CloudWatch console. These metrics include input/output tokens count, invocation metrics, and errors.
AWS CDK stacks
We used the AWS CDK to provision all the resources mentioned. The AWS CDK defines the AWS Cloud infrastructure in a general-purpose programming language. Currently, the AWS CDK supports TypeScript, JavaScript, Python, Java, C#, and Go. We used TypeScript for the AWS CDK stacks and constructs.
AWS CodeCommit
The first AWS Cloud resource is an AWS CodeCommit repository. CodeCommit is a secure, highly scalable, fully managed source control service that hosts private Git repositories. The entire code base of this prototyping engagement resides in the CodeCommit repo provisioned by the AWS CDK in the us-east-1 Region.
Amazon Bedrock roles
A dedicated IAM policy is created to allow other AWS Cloud services to access Amazon Bedrock within the target AWS account. We used IAM to create a policy document and add the necessary roles. The roles and policy define the access constraints to Amazon Bedrock from other AWS services in the customer account.
It’s recommended to follow the Well Architected Framework’s principle of least privilege for a production-ready security posture.
Amazon VPC
The prototype infrastructure was built within an virtual private cloud (VPC), which enables you to launch AWS resources in a logically isolated virtual network that you’ve defined.
Amazon Virtual Private Cloud (Amazon VPC) also isolates other resources, including publicly accessible AWS services like Secrets Manager, Amazon S3, and Lambda. A VPC endpoint enables you to privately connect to supported AWS services and VPC endpoint services powered by AWS PrivateLink. VPC endpoints create dynamic, scalable, and privately routable network connections between the VPC and supported AWS services. There are two types of VPC endpoints: interface endpoints and gateway endpoints. The following endpoints were created using the AWS CDK:
- An Amazon S3 gateway endpoint to access several S3 buckets needed for this prototype
- An Amazon VPC endpoint to allow private communication between AWS Cloud resources within the VPC and Amazon Bedrock with a policy to allow listing of FMs and to invoke an FM
- An Amazon VPC endpoint to allow private communication between AWS Cloud resources within the VPC and the secrets stored in Secrets Manager only within the AWS account and the specific target Region of
us-east-1
Provision OpenSearch Service clusters
OpenSearch Service makes it straightforward to perform interactive log analytics, real-time application monitoring, website search, and more. OpenSearch is an open source, distributed search and analytics suite derived from Elasticsearch. OpenSearch Service offers the latest versions of OpenSearch, support for 19 versions of Elasticsearch (1.5 to 7.10 versions), as well as visualization capabilities powered by OpenSearch Dashboards and Kibana (1.5 to 7.10 versions). OpenSearch Service currently has tens of thousands of active customers with hundreds of thousands of clusters under management, processing hundreds of trillions of requests per month.
The first step was setting up an OpenSearch Service security group that is restricted to only allow HTTPS connectivity to the index. Then we added this security group to the newly created VPC endpoints for Secrets Manager to allow OpenSearch Service to store and retrieve the credentials necessary to access the clusters. As a best practice, we don’t reuse or import a primary user; instead, we create a primary user with a unique user name and password automatically using the AWS CDK upon deployment. Because the OpenSearch Service security group to the VPC is allowed, the primary user credentials are now stored directly in Secrets Manager while the AWS CDK stack is deployed.
The number of data nodes must be a multiple of the number of Availability Zones configured for the domain, so a list of three subnets from all the available VPC subnets is maintained.
Lambda wrapper function design and deployment
The Lambda wrapper function is the central Lambda function, which connects to every other AWS resource such as Amazon Bedrock, OpenSearch Service, Secrets Manager, and Amazon S3.
The first step is setting up two Lambda layers, one for LangChain and the other for OpenSearch Service dependencies. A Lambda layer is a .zip file archive that contains supplementary code or data. Layers usually contain library dependencies, a custom runtime, or configuration files.
Using the provided RDS database, the security groups were imported and linked to the Lambda wrapper function for Lambda to then reach out to the RDS instance. We used Amazon RDS Proxy to create a proxy to obscure the original domain details of the RDS instance. This RDS proxy interface was manually created from the AWS Management Console and not from the AWS CDK.
DB schema generator Lambda function
An S3 bucket is then created to store the RDS DB schema file with configurations to block public access with Amazon S3 managed encryptions, although customer managed key (CMK) backed encryption is recommended for enhanced security for production workloads.
The Lambda function was created with access to Amazon RDS using an RDS proxy endpoint. The credentials of the RDS instance are manually stored in Secrets Manager and access to the DB schema S3 bucket can be gained by adding an IAM policy to the Amazon S3 VPC endpoint (created earlier in the stack).
Website dashboard
The frontend provides an interface where users can log in and enter natural language prompts to get AI-generated responses. The various resources deployed through the website stack are as follows.
Imports
The website stack communicates with the infrastructure stack to deploy the resources within a VPC and trigger the Lambda wrapper function. The VPC and Lambda function objects were imported into this stack. This is the only link between the two stacks so they remain loosely coupled.
Auth stack
The auth stack is responsible for setting up Amazon Cognito user pools, identity pools, and the authenticated and un-authenticated IAM roles. User sign-in settings and password policies were set up with an email as our primary authentication mechanism to help prevent new users from signing up from the web application itself. New users must be manually created from the console.
Bucket stack
The bucket stack is responsible for setting up the S3 bucket to store the response from the Lambda wrapper function. The Lambda wrapper function is smart enough to understand if it was invoked directly from the console or the website. The frontend code will reach out to this response bucket to pull the response for the respective natural language prompt. The S3 bucket endpoint is configured with an allow list to limit the I/O traffic of this bucket within the VPC only.
API stack
The API stack is responsible for setting up an API Gateway endpoint that is protected by Amazon Cognito to allow authenticated and authorized user entities. Also, a REST API stage was added, which then invokes the website Lambda function.
The website Lambda function is allowed to invoke the Lambda wrapper function. Invoking a Lambda function within a VPC by a non-VPC Lambda function is allowed but is not recommended for a production system.
The API Gateway endpoint is protected by an AWS WAF configuration. AWS WAF helps you protect against common web exploits and bots that can affect availability, compromise security, or consume excessive resources.
Hosting stack
The hosting stack uses CloudFront to serve the frontend website code (HTML, CSS, and JavaScript) stored in a dedicated S3 bucket. CloudFront is a content delivery network (CDN) service built for high performance, security, and developer convenience. When you serve static content that is hosted on AWS, the recommended approach is to use an S3 bucket as the origin and use CloudFront to distribute the content. There are two primary benefits of this solution. The first is the convenience of caching static content at edge locations. The second is that you can define web access control lists (ACLs) for the CloudFront distribution, which helps you secure requests to the content with minimal configuration and administrative overhead.
Users can visit the CloudFront distribution endpoint from their preferred web browser to access the login screen.
Home page
The home page has three sections to it. The first section is the NLQ prompt section, where you can add up to three user prompts and delete prompts as needed.

The prompts are then translated into a prompt input that will be sent to the Lambda wrapper function. This section is non-editable and only for reference. You can opt to use the OpenSearch Service vector DB store to get preprocessed queries for faster responses. Only prompts that were processed earlier and stored in the vector DB will return a valid response. For newer queries, we recommend leaving the switch in its default off position.

If you choose Get Response, you may see a progress bar, which waits for approximately 100 seconds for the Lambda wrapper function to finish. If the response is timed out for reasons such as unexcepted service delays with Amazon Bedrock or Lambda, you will see a timeout message and the prompts are reset.

When the Lambda wrapper function is complete, it outputs the AI generated response.

Conclusion
CBRE has taken pragmatic steps to adopt transformative AI technologies that enhance their business offerings and extend their leadership in the market. CBRE and the AWS Prototyping team developed an NLQ environment using Amazon Bedrock, Lambda, Amazon RDS, and OpenSearch Service, demonstrating outputs with a high accuracy rate (more than 95%), supported reuse of embeddings, and an API gateway.
This project is a great starting point for organizations looking to break ground with generative AI in data analytics. CBRE stands poised and ready to continue using their intimate knowledge of their customers and the real estate industry to build the real estate solutions of tomorrow.
For more resources, refer to the following:
- AWS Generative AI Innovation Center
- Inside the AWS Prototyping and Innovation Lab
- Guidance for Natural Language Queries of Relational Databases on AWS
About the Authors
- Surya Rebbapragada is the VP of Digital & Technology at CBRE
- Edy Setiawan is the Director of Digital & Technology at CBRE
- Naveena Allampalli is a Sr. Principal Enterprise Architect at CBRE
- Chakra Nagarajan is a Sr. Principal ML Prototyping Solutions Architect at AWS
- Tamil Jayakumar is a Sr. Prototyping Engineer at AWS
- Shane Madigan is a Sr. Engagement Manager at AWS
- Maran Chandrasekaran is a Sr. Solutions Architect at AWS
- VB Bakre is an Account Manager at AWS
Author: Surya Rebbapragada