

Combining content moderation services with graph databases & analytics to reduce community toxicity
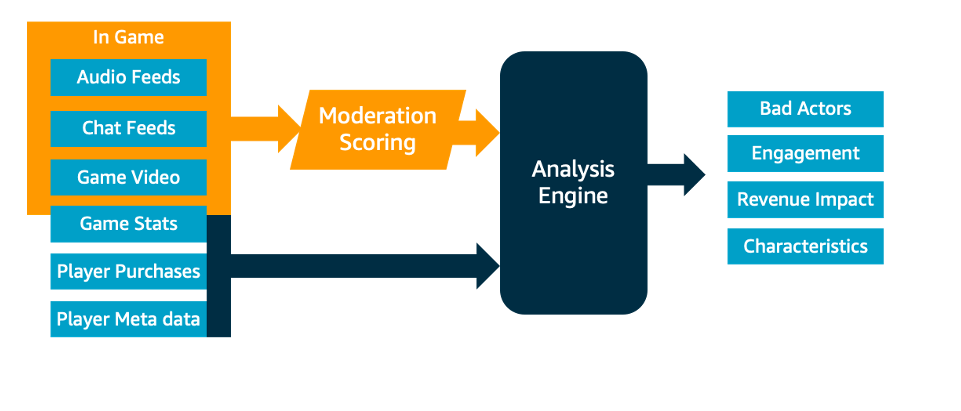
We shall be using a multi-player gaming scenario to illustrate this, but the steps below could be applicable to any community with user-generated content and interactions between users… Audio, chat and game screenshots are ingested into the moderation system where they can be combined with “me…
Ensuring online communities are safe and inclusive places for all is essential for maintaining community engagement and ultimately obtaining the most value for your users.
This challenge presents itself in many industries – ranging from gaming to social media networks. However, the volume of data and interactions between users increases daily making policing these communities more and more difficult.
In this blog we describe how the AWS machine learning services can be used, in conjunction with graph databases and visualisation tools, to automate the process of scoring users and determining the impact of toxicity on your community.
We shall be using a multi-player gaming scenario to illustrate this, but the steps below could be applicable to any community with user-generated content and interactions between users. Some basic knowledge of AWS is required and familiarity with working on the command line.
High Level Approach
The basic approach for this solution involves collecting data from both the game client and central databases. Audio, chat and game screenshots are ingested into the moderation system where they can be combined with “metadata” about the player and the games.
By combining live game interactions with meta data, a richer picture can be derived allowing questions to be asked like “Do players stay in a game with many toxic interactions?” or “Do players with a high toxicity score spend more or less on in-game transactions?”. This sort of information could be used to influence matchmaking decisions, for example, preventing players who are more sensitive to abusive content from being matched with players more tolerant of toxicity. It could also help in deciding when to eject abusive players from games or for reporting purposes to understand the impact of toxicity on your community.

Technical High Level Architecture
Before going through the steps required to configure the solution, let’s look at the high-level architecture.

Ingestion
The first step is to ingest the required data from both the game client and the central databases into the system.
For the in-game components the ability to ingest potentially millions of interactions from in-game chat and speech is needed. Therefore, a massively scalable platform to collect streaming data in real time is needed. For this task we recommend Amazon Kinesis. Kinesis is a managed service which cost-effectively process and analyzes streaming data at any scale. Using the Kinesis SDK, in-game clients can send chat transcripts and audio snippets to this system.
Kinesis could also be used to process video streams from the game clients, but for this solution we have opted to use screenshots on a periodic basis to reduce cost.
Kinesis is configured to store audio and screenshot information in an Amazon Simple Store Service (Amazon S3) “scratch space” bucket, while chat interactions are directly passed to the next stage.
Kinesis is configured to send “micro batches” of these interactions to an AWS Lambda function. AWS Lambda is a serverless compute platform that automatically allows seamless scaling from a few interactions per minute to thousands of interactions.
These Lambda functions are responsible for performing abuse moderation functions against the AWS Machine Learning and Natural Language processing services before passing the results to the graph database.
A method of processing “metadata” from the central databases is also needed. For this solution we suggest that you send:
- player information (e.g. username, date joined, age, gender)
- player transactions (e.g. how much they spent and when)
- time spent within a particular game session (e.g. which games they played and what was the duration of play)
This could include any metrics that would be relevant to your community.
Since the volume of data would be lower than the in-game interactions and is transactional in nature, we propose that an API Gateway is used to trigger a separate Lambda function which enters this information into the graph database. API Gateway is a scalable frontend for APIs which handles scaling, traffic management, and authorization.
Moderation
Now that the data from the in-game interactions has been passed into the AWS Lambda function, it’s time to start figuring out if the interaction is toxic or not.
Let’s start with audio data. Amazon Transcribe is a managed service for converting audio to text. In this case, we simply pass the audio data to the transcription service, and the transcribed text is passed back. In this solution we then pass the transcribed text back into the Kinesis stream for processing a text-based “chat” interaction (with a flag indicating audio origins) to simplify the architecture.
Chat data (or transcribed audio data) is passed to the Amazon Comprehend service. This service can be used for many purposes such as extracting entities, topics and key phrases from text. In this case, it can also be used to detect sentiment and can also be trained to identify abusive or toxic content.
For in-game video (or in this case, screenshots) we pass this to the Amazon Rekognition service. Amazon Rekognition is a machine-learning based image and video analysis solution that can label objects within an image. For this solution, we will use it to label any offensive content.
Graph Database
Next, moderation results and meta data need to be stored in a repository. Since this solution revolves around the relationships between players, games, transactions and abusive incidents, we have selected a graph database. Graph databases are purpose built for storing and modelling relationships between entities, making them perfect for this use. We will be using Amazon Neptune as our graph database.
Visualization
There are many tools available to query and visualise graph databases. In this case Jupyter Notebook is used to query the Amazon Neptune database. The notebook is used to dynamically query the data to help visualise the relationships between players, games, transactions and abusive incidents.
Additionally, Amazon’s business intelligence tool, Amazon Quicksight, can be configured to run reports against the data via Amazon Athena.
Procedure
To implement this demonstration solution, we have provided an AWS Cloud Development Kit (CDK) model for you to use, and some sample scripts to help you get up and running.
Prerequisites
Since this is only a demonstration solution, it is strongly recommended that this is deployed on an AWS account in a test & development environment.
You will need Python installed on your client machine to be able to run this sample code and deploy the CDK model.
Installation
- Using the AWS CDK, deploy the solution as detailed at: https://github.com/aws-samples/content-moderation-with-graph-databases
Once the deployment is complete and you’ll be ready to start inputting data into the system. Ensure that you complete the pre-requisites including installing the additional python modules.
Resources Created
Before you ingest any data into the system, first you should understand what has been deployed.
Backend
In the backend, an Amazon Neptune database and a Jupyter Notebook has been deployed, ready for you to create visualisations against your database.
API Gateway
The “API” Lambda function which acts as the service which runs behind your API Gateway. This API is responsible for creating games, players, transactions and receiving notifications of abusive content from the three other functions has also been deployed. It is the only part of the frontend that communicates with Neptune.
The API Gateway accepts PUT requests with HTTP form data for the variables:
/createGame – requires ‘gameid’ to be set
/createPlayer – requires ‘playerid’ to be set
/playerPlaysGame – requires ‘playerid’ and ‘gameid’ to be set
/playerTransaction – requires ‘playerid’,’gameid’,’transactionid’ and ‘transactionvalue’
It also accepts PUT request on /recordAbuse to record incidents of abusive behaviour.
This should contain the fields ‘playerid’, ’gameid’, ‘abusetype’ (e.g. AUDIO, CHAT, SCREENSHOT) and ‘abusecontent’ (i.e. the abusive comment or label found in the data)
Lastly, a GET request to /resetNeptune will reset the database.
Chat Data
An Amazon Kinesis stream to accept chat data has also been created. You can post chat data to the Kinesis stream with the following JSON object:
{ “gameid” : “the game id”, “playerid” : “the playerid”, “type” : “chat” , “data” : “your text data for analysis”}
There is also a Lambda function which has a trigger setup to read from this Kinesis stream.
This Lambda function will use Amazon Comprehend to determine the sentiment of the text. If abuse is detected, it will send the information to the “/recordAbuse” API endpoint.
Screenshot Data
An S3 bucket has been created where your client will upload screenshots of in-game footage.
The filename should be in the format “gameid-playerid-screenname.jpg” so that the screenshot can be linked to a game and a player. In a production system you could also consider using tagging.
There is also a trigger to a Lambda function that will pass the screenshot through Amazon Rekogntion to detect any abusive labels in the image. Again, any abuse is sent to the “/recordAbuse” API endpoint.
Audio Data
In a similar way to screenshot data, an S3 bucket is created for audio. Audio filenames should be in the format “gameid-playerid-audioname.mp3”. Amazon Transcribe is used to convert the audio to text. This transcription is then passed back to the Kinesis stream previously described for chat data and is processed.
Populating our system
Our database is currently empty, so before you visualise your player interactions and abusive content, you need to create some players and games.
Within the github repository you installed the solution from is a folder called “example-scripts” which contains several Python scripts that will help you test out the system.
Base Players & Games
- Retrieve your API Endpoint from the CloudFormation Outputs. This will be the key called “APIEndpoint”

- To populate your database with a sample range of players, games and transactions run in your terminal:
cd examples-scripts/python setupGamesPlayers.py APIEndpoint
- Retrieve your API Endpoint from the CloudFormation Outputs. This will be the key called “APIEndpoint”

This script will create 20 transactions, 20 players, 20 games and 200 game-to-player links (meaning a player has played a game). You can amend these parameters at the top of the Python file.
Player IDs will be prefixed with a ‘p’ (e.g. p23), game IDs with a ‘g’ (e.g. g101) and transactions with a ‘t’ – although this is not a required for the solution to work should you wish to pass your own data to the platform.
Visualize using Jupyter Notebook
You can visualize the games and players you just created using a Jupyter notebook.
- Navigate to Amazon SageMaker in the AWS Console, then to Notebook Instances. You should see a notebook called “cdk-neptune-workbench”. Press Open Jupyter.

- Once in Jupyter, select Upload and upload the “Content Moderation Samples.ipynb” file from the “examples-scripts” folder.

This notebook has automatically been configured to connect to your Neptune database so you can begin querying immediately.
In this example, you are using Gremlin to query your database, but you could also use other graph query languages like SPARQL or Cypher.
- Select “Run” on the first two blocks of code. Then go to the graph tab.

You should be able to see a visualization of all of the players, games and the links between them – showing which players have played which games. You can also see the financial transactions around the outside.
- Zoom into the visualization and pick a playerID and find a gameID that they have played at random – you’ll need these for the next step.
Creating Abuse
You now want to test out the abuse detection systems.
Let’s start with Chat data.
Chat Data
Within the “example-scripts” folder there is a script that will post chat data to your Kinesis stream for processing.
- Retrieve your Kinesis stream name from your CloudFormation Output. It is the key called “KinesisChatStream”
- On your terminal enter:
python postChat.py KinesisChatStream game-id player-id chat-data
You can enter a ‘0’ for chat-data which will pick a comment at random, ‘NEGATIVE’/’POSITIVE’ for a random negative/positive comment, or you may enter your own comment. Remember to put single quotes around your comment.
- Repeat this 10 times to get some data flowing into the system.
- You can check that it is working by navigating to Lambda function in the AWS console. You can find the function name in your CloudFormation Output as the key “lambdaChat”
- Click the function, then onto the Monitor tab. Under the Logs section retrieve the latest log file.

You should see in the log the results of sentiment analysis against the chat you entered.
Screenshot Data
First retrieve the location of the S3 bucket that will be used to store your audio files.
This will be in your CloudFormation Output as the key “S3ScreenshotsBucket”.
On your terminal enter: python postScreenshot.py S3ScreenshotsBucket game-id player-id screenshot-location
You can enter a ‘0’ for screenshot-location which will pick a screenshot from the ‘screenshots’ folder at random, ‘NEGATIVE’/’POSITIVE’ for a random negative/positive screenshot, or you may enter your own screenshot filename. Remember to place the screenshot in the ‘screenshots’ folder.
You can check this worked by locating the Lambda function (CloudFormation Output key “lambdaScreenshots”) and reviewing the logs as we did for the chat data.

Audio Data
Again, retrieve the S3 location – the CloudFormation Output key is “S3AudioBucket”.
On your terminal enter: python postAudio.py S3AudioBucket game-id player-id audio-filename
You can enter a ‘0’ for audio-location which will pick an audio file from the ‘audio’ folder at random, ‘NEGATIVE’/’POSITIVE’ for a random negative/positive screenshot, or you may enter your own audio filename. Remember to place the audio in the ‘audio’ folder.
To check if the transcription worked find the Lambda function (CloudFormation Output key “lambdaAudio”) and check the logs in the same way you did for chat data.
Once the audio is transcribed it will be sent back to the Chat Kinesis stream for processing.

Visualize Abuse
Return to your Jupyter notebook and re-run your query. You should see that now the abusive incidents are connected to the player and game you selected.

Try some of the other queries in the Notebook which zoom in on individual players.

You can also zoom in on a player and see all the games they have played – including the other players and any abuse witnessed in that game.

Custom Training Models
For this demonstration you have been using out-of-the-box models included in Amazon Comprehend and Amazon Rekognition.
These are a great starting point, but for your community you may have specific requirements.
You can train Amazon Comprehend to apply custom classification labels to your chat data to more accurately reflect what your community would consider toxic content.
An example dataset, created by Victor Zhou, that can be used train a Custom Classifier to detect toxic content is available here. This dataset has two columns – firstly text obtained from various sources, and secondly a marker indicating whether this text was judged offensive or not.
To make the results more readable, we suggest the values of the ‘is_offensive’ column are replaced with OFFENSIVE or NOT_OFFENSIVE rather than 1 or 0. The first ‘header’ line of the file should be removed as this is not required for Amazon Comprehend. Ensure that file has 2 columns – the first column the label (OFFENSIVE or NOT_OFFENSIVE) and the second column the text.
Then follow the instructions in this blog post to setup a Custom Classifier in Amazon Comprehend.
You can follow a similar process to create custom labels for your screenshots. Full details are available in the documentation for Amazon Rekognition: https://docs.aws.amazon.com/rekognition/latest/customlabels-dg/getting-started.html
Visualising in QuickSight
You could take this project further by enabling the data to be accessed in QuickSight, which allows business users to access, query and report on your database.
QuickSight does not have a native connector to Neptune, so you need to create an Athena connector first that will allow regular SQL queries to be run against your database.
To create an Athena connector to your Neptune database, please see the article “Build interactive graph data analytics and visualization using Amazon Neptune, Amazon Athena Federated Query, and Amazon QuickSight”.
We have included in our ‘example-scripts’ directory a Shell script that will create the required glue tables for you. You must specify your region and an S3 bucket (a bucket has been created for you – see your CloudFormation Output key “S3Overspill).
sh create-glue.sh aws-cli-profile aws-region S3Overspill
e.g. sh create-glue.sh default eu-west-1 s3://NeptuneOverspill
Once you have that setup you should be able to create queries against your dataset.
For example, here we have a scatter plot comparing how much of a game players complete (%) compared to how much toxic content they witness within the game:

Or visualize the impact of abusive players on player engagement by comparing the amount of money they spend in-game against the abusive behaviors they witness:

Clean up
- Remove the Quicksight instance that you have created
- Remove the Custom Training model from Comprehend
- If you created IAM roles as part of the Comprehend step remove these
- Delete the Neptune database created as part of deployment
- Delete the CloudFormation stack.
Conclusion
In this blog we’ve shown how you can combine the Amazon Machine Learning services to quickly identify abusive content in your community and provide additional context by mapping this onto a graph database to show the relationships between players, games and abuse.
We hope some of the techniques presented here can help you maintain an engaged, abuse-free online community!
Author: Andrew Thomas