

Converting stateful application to stateless using AWS services
Designing a system to be either stateful or stateless is an important choice with tradeoffs regarding its performance and scalability… In a stateful system, data from one session is carried over to the next… A stateless system doesn’t preserve data between sessions and depends on external enti…
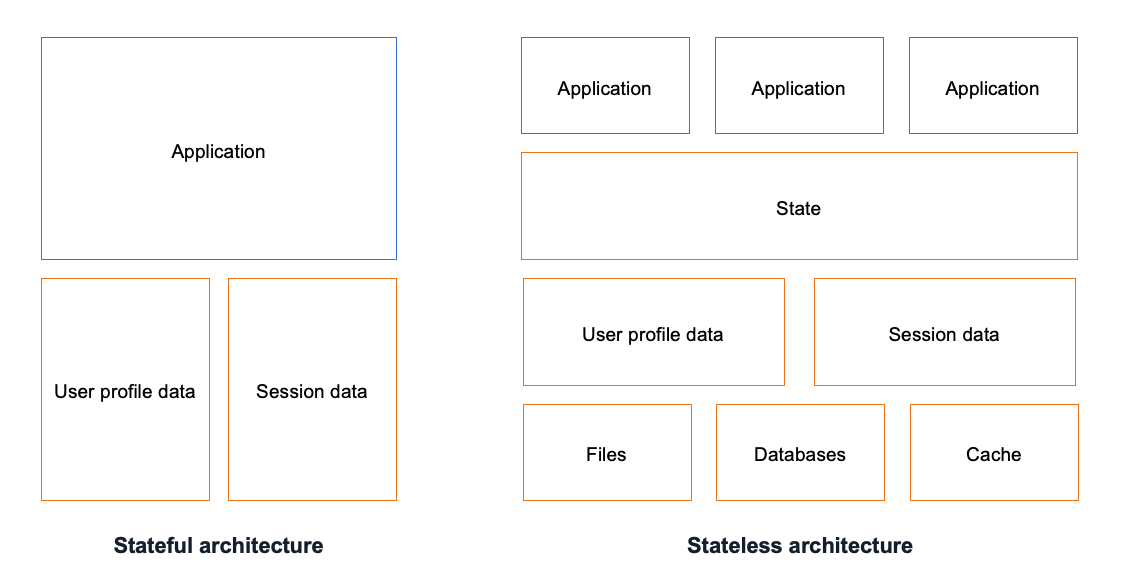
Designing a system to be either stateful or stateless is an important choice with tradeoffs regarding its performance and scalability. In a stateful system, data from one session is carried over to the next. A stateless system doesn’t preserve data between sessions and depends on external entities such as databases or cache to manage state.
Stateful and stateless architectures are both widely adopted.
- Stateful applications are typically simple to deploy. Stateful applications save client session data on the server, allowing for faster processing and improved performance. Stateful applications excel in predictable workloads and offer consistent user experiences.
- Stateless architectures typically align with the demands of dynamic workload and changing business requirements. Stateless application design can increase flexibility with horizontal scaling and dynamic deployment. This flexibility helps applications handle sudden spikes in traffic, maintain resilience to failures, and optimize cost.
Figure 1 provides a conceptual comparison of stateful and stateless architectures.

Figure 1. Conceptual diagram for stateful vs stateless architectures
For example, an eCommerce application accessible from web and mobile devices manages several aspects of the customer transaction life cycle. This lifecycle starts with account creation, then moves to placing items in the shopping cart, and proceeds through checkout. Session and user profile data provide session persistence and cart management, which retain the cart’s contents and render the latest updated cart from any device. A stateless architecture is preferable for this application because it decouples user data and offloads the session data. This provides the flexibility to scale each component independently to meet varying workloads and optimize resource utilization.
In this blog, we outline the process and benefits of converting from a stateful to stateless architecture.
Solution overview
This section walks you through the steps for converting stateful to stateless architecture:
- Identifying and understanding the stateful requirements
- Decoupling user profile data
- Offloading session data
- Scaling each component dynamically
- Designing a stateless architecture
Step 1: Identifying and understanding the stateful components
Transforming a stateful architecture to a stateless architecture starts with reviewing the overall architecture and source code of the application, and then analyzing dataflow and dependencies.
Review the architecture and source code
It’s important to understand how your application accesses and shares data. Pay attention to components that persist state data and retain state information. Examples include user credentials, user profiles, session tokens, and data specific to sessions (such as shopping carts). Identifying how this data is handled serves as the foundation for planning the conversion to a stateless architecture.
Analyze dataflow and dependencies
Analyze and understand the components that maintain state within the architecture. This helps you assess the potential impact of transitioning to a stateless design.
You can use the following questionnaire to assess the components. Customize the questions according to your application.
- What data is specific to a user or session?
- How is user data stored and managed?
- How is the session data accessed and updated?
- Which components rely on the user and session data?
- Are there any shared or centralized data stores?
- How does the state affect scalability and tolerance?
- Can the stateful components be decoupled or made stateless?
Step 2: Decoupling user profile data
Decoupling user data involves separating and managing user data from the core application logic. Delegate responsibilities for user management and secrets, such as application programming interface (API) keys and database credentials, to a separate service that can be resilient and scale independently. For example, you can use:
- Amazon Cognito to decouple user data from application code by using features, such as identity pools, user pools, and Amazon Cognito Sync.
- AWS Secrets Manager to decouple user data by storing secrets in a secure, centralized location. This means that the application code doesn’t need to store secrets, which makes it more secure.
- Amazon S3 to store large, unstructured data, such as images and documents. Your application can retrieve this data when required, eliminating the need to store it in memory.
- Amazon DynamoDB to store information such as user profiles. Your application can query this data in near-real time.
Step 3: Offloading session data
Offloading session data refers to the practice of storing and managing session related data external to the stateful components of an application. This involves separating the state from business logic. You can offload session data to a database, cache, or external files.
Factors to consider when offloading session data include:
- Amount of session data
- Frequency and latency
- Security requirements
Amazon ElastiCache, Amazon DynamoDB, Amazon Elastic File System (Amazon EFS), and Amazon MemoryDB for Redis are examples of AWS services that you can use to offload session data. The AWS service you choose for offloading session data depends on application requirements.
Step 4: Scaling each component dynamically
Stateless architecture gives the flexibility to scale each component independently, allowing the application to meet varying workloads and optimize resource utilization. While planning for scaling, consider using:
- AWS Autoscaling, which supports automatic scaling of resources based on predefined policies and metrics.
- AWS Load Balancer, which supports dynamic scaling by automatically adding or removing instances based on the configured scaling policies and health checks.
- Containers orchestration and management services on AWS and services such as Amazon API Gateway, AWS Lambda, Amazon Aurora Serverless, which can automatically scale the capacity based on the workload.
Step 5: Design a stateless architecture
After you identify which state and user data need to be persisted, and your storage solution of choice, you can begin designing the stateless architecture. This involves:
- Understanding how the application interacts with the storage solution.
- Planning how session creation, retrieval, and expiration logic work with the overall session management.
- Refactoring application logic to remove references to the state information that’s stored on the server.
- Rearchitecting the application into smaller, independent services, as described in steps 2, 3, and 4.
- Performing thorough testing to ensure that all functionalities produce the desired results after the conversion.
The following figure is an example of a stateless architecture on AWS. This architecture separates the user interface, application logic, and data storage into distinct layers, allowing for scalability, modularity, and flexibility in designing and deploying applications. The tiers interact through well-defined interfaces and APIs, ensuring that each component focuses on its specific responsibilities.

Figure 2. Example of a stateless architecture
Benefits
Benefits of adopting a stateless architecture include:
- Scalability: Stateless components don’t maintain a local state. Typically, you can easily replicate and distribute them to handle increasing workloads. This supports horizontal scaling, making it possible to add or remove capacity based on fluctuating traffic and demand.
- Reliability and fault tolerance: Stateless architectures are inherently resilient to failures. If a stateless component fails, it can be replaced or restarted without affecting the overall system. Because stateless applications don’t have a shared state, failures in one component don’t impact other components. This helps ensure continuity of user sessions, minimizes disruptions, and improves fault tolerance and overall system reliability.
- Cost-effectiveness: By leveraging on-demand scaling capabilities, your application can dynamically adjust resources based on actual demand, avoiding overprovisioning of infrastructure. Stateless architectures lend themselves to serverless computing models, paying for the actual run time and resulting in cost savings.
- Performance: Externalizing session data by using services optimized for high-speed access, such as in-memory caches, can reduce the latency compared to maintaining session data internally.
- Flexibility and extensibility: Stateless architectures provide flexibility and agility in application development. Offloaded session data provides more flexibility to adopt different technologies and services within the architecture. Applications can easily integrate with other AWS services for enhanced functionality, such as analytics, near real-time notifications, or personalization.
Conclusion
Converting stateful applications to stateless applications requires careful planning, design, and implementation. Your choice of architecture depends on your application’s specific needs. If an application is simple to develop and debug, then a stateful architecture might be a good choice. However, if an application needs to be scalable and fault tolerant, then a stateless architecture might be a better choice. It’s important to understand the current application thoroughly before embarking on a refactoring journey.
Further reading
Author: Sarat Para