

Create a document lake using large-scale text extraction from documents with Amazon Textract
AWS customers in healthcare, financial services, the public sector, and other industries store billions of documents as images or PDFs in Amazon Simple Storage Service (Amazon S3)… With AWS intelligent document processing (IDP) using AI services such as Amazon Textract, you can take advantage of i…
AWS customers in healthcare, financial services, the public sector, and other industries store billions of documents as images or PDFs in Amazon Simple Storage Service (Amazon S3). However, they’re unable to gain insights such as using the information locked in the documents for large language models (LLMs) or search until they extract the text, forms, tables, and other structured data. With AWS intelligent document processing (IDP) using AI services such as Amazon Textract, you can take advantage of industry-leading machine learning (ML) technology to quickly and accurately process data from PDFs or document images (TIFF, JPEG, PNG). After the text is extracted from the documents, you can use it to fine-tune a foundation model, summarize the data using a foundation model, or send it to a database.
In this post, we focus on processing a large collection of documents into raw text files and storing them in Amazon S3. We provide you with two different solutions for this use case. The first allows you to run a Python script from any server or instance including a Jupyter notebook; this is the quickest way to get started. The second approach is a turnkey deployment of various infrastructure components using AWS Cloud Development Kit (AWS CDK) constructs. The AWS CDK construct provides a resilient and flexible framework to process your documents and build an end-to-end IDP pipeline. Through the use of the AWS CDK, you can extend its functionality to include redaction, store the output in Amazon OpenSearch, or add a custom AWS Lambda function with your own business logic.
Both of these solutions allow you to quickly process many millions of pages. Before running either of these solutions at scale, we recommend testing with a subset of your documents to make sure the results meet your expectations. In the following sections, we first describe the script solution, followed by the AWS CDK construct solution.
Solution 1: Use a Python script
This solution processes documents for raw text through Amazon Textract as quickly as the service will allow with the expectation that if there is a failure in the script, the process will pick up from where it left off. The solution utilizes three different services: Amazon S3, Amazon DynamoDB, and Amazon Textract.
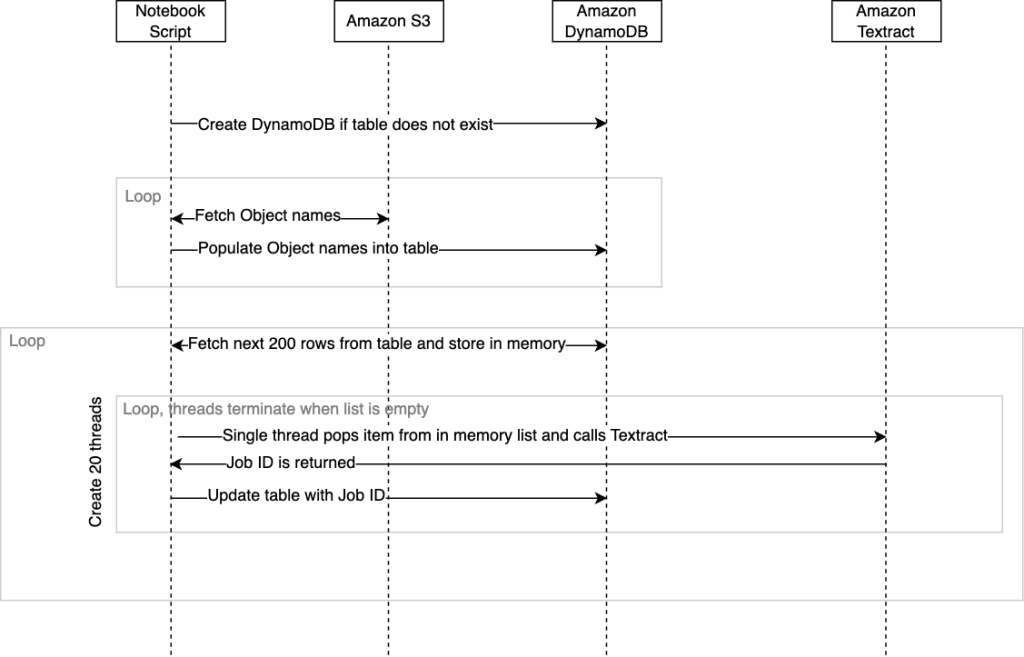
The following diagram illustrates the sequence of events within the script. When the script ends, a completion status along with the time taken will be returned to the SageMaker studio console.

We have packaged this solution in a .ipynb script and .py script. You can use any of the deployable solutions as per your requirements.
Prerequisites
To run this script from a Jupyter notebook, the AWS Identity and Access Management (IAM) role assigned to the notebook must have permissions that allow it to interact with DynamoDB, Amazon S3, and Amazon Textract. The general guidance is to provide least-privilege permissions for each of these services to your AmazonSageMaker-ExecutionRole role. To learn more, refer to Get started with AWS managed policies and move toward least-privilege permissions.
Alternatively, you can run this script from other environments such as an Amazon Elastic Compute Cloud (Amazon EC2) instance or container that you would manage, provided that Python, Pip3, and the AWS SDK for Python (Boto3) are installed. Again, the same IAM polices need to be applied that allow the script to interact with the various managed services.
Walkthrough
To implement this solution, you first need to clone the repository GitHub.
You need to set the following variables in the script before you can run it:
- tracking_table – This is the name of the DynamoDB table that will be created.
- input_bucket – This is your source location in Amazon S3 that contains the documents that you want to send to Amazon Textract for text detection. For this variable, provide the name of the bucket, such as
mybucket. - output_bucket – This is for storing the location of where you want Amazon Textract to write the results to. For this variable, provide the name of the bucket, such as
myoutputbucket. - _input_prefix (optional) – If you want to select certain files from within a folder in your S3 bucket, you can specify this folder name as the input prefix. Otherwise, leave the default as empty to select all.
The script is as follows:
The following DynamoDB table schema gets created when the script is run:
When the script is run for the first time, it will check to see if the DynamoDB table exists and will automatically create it if needed. After the table is created, we need to populate it with a list of document object references from Amazon S3 that we want to process. The script by design will enumerate over objects in the specified input_bucket and automatically populate our table with their names when ran. It takes approximately 10 minutes to enumerate over 100,000 documents and populate those names into the DynamoDB table from the script. If you have millions of objects in a bucket, you could alternatively use the inventory feature of Amazon S3 that generates a CSV file of names, then populate the DynamoDB table from this list with your own script in advance and not use the function called fetchAllObjectsInBucketandStoreName by commenting it out. To learn more, refer to Configuring Amazon S3 Inventory.
As mentioned earlier, there is both a notebook version and a Python script version. The notebook is the most straightforward way to get started; simply run each cell from start to finish.
If you decide to run the Python script from a CLI, it is recommended that you use a terminal multiplexer such as tmux. This is to prevent the script from stopping should your SSH session finish. For example: tmux new -d ‘python3 textractFeeder.py’.
The following is the script’s entry point; from here you can comment out methods not needed:
The following fields are set when the script is populating the DynamoDB table:
- objectName – The name of the document located in Amazon S3 that will be sent to Amazon Textract
- bucketName – The bucket where the document object is stored
These two fields must be populated if you decide to use a CSV file from the S3 inventory report and skip the auto populating that happens within the script.
Now that the table is created and populated with the document object references, the script is ready to start calling the Amazon Textract StartDocumentTextDetection API. Amazon Textract, similar to other managed services, has a default limit on the APIs called transactions per second (TPS). If required, you can request a quota increase from the Amazon Textract console. The code is designed to use multiple threads concurrently when calling Amazon Textract to maximize the throughput with the service. You can change this within the code by modifying the threadCountforTextractAPICall variable. By default, this is set to 20 threads. The script will initially read 200 rows from the DynamoDB table and store these in an in-memory list that is wrapped with a class for thread safety. Each caller thread is then started and runs within its own swim lane. Basically, the Amazon Textract caller thread will retrieve an item from the in-memory list that contains our object reference. It will then call the asynchronous start_document_text_detection API and wait for the acknowledgement with the job ID. The job ID is then updated back to the DynamoDB row for that object, and the thread will repeat by retrieving the next item from the list.
The following is the main orchestration code script:
The caller threads will continue repeating until there are no longer any items within the list, at which point the threads will each stop. When all threads operating within their swim lanes have stopped, the next 200 rows from DynamoDB are retrieved and a new set of 20 threads are started, and the whole process repeats until every row that doesn’t contain a job ID is retrieved from DynamoDB and updated. Should the script crash due to some unexpected problem, then the script can be run again from the orchestrate() method. This makes sure that the threads will continue processing rows that contain empty job IDs. Note that when rerunning the orchestrate() method after the script has stopped, there is a potential that a few documents will get sent to Amazon Textract again. This number will be equal to or less than the number of threads that were running at the time of the crash.
When there are no more rows containing a blank job ID in the DynamoDB table, the script will stop. All the JSON output from Amazon Textract for all the objects will be found in the output_bucket by default under the textract_output folder. Each subfolder within textract_output will be named with the job ID that corresponds to the job ID that was stored in the DynamoDB table for that object. Within the job ID folder, you will find the JSON, which will be numerically named starting at 1 and can potentially span additional JSON files that would be labeled 2, 3, and so on. Spanning JSON files is a result of dense or multi-page documents, where the amount of content extracted exceeds the Amazon Textract default JSON size of 1,000 blocks. Refer to Block for more information on blocks. These JSON files will contain all the Amazon Textract metadata, including the text that was extracted from within the documents.
You can find the Python code notebook version and script for this solution in GitHub.
Clean up
When the Python script is complete, you can save costs by shutting down or stopping the Amazon SageMaker Studio notebook or container that you spun up.
Now on to our second solution for documents at scale.
Solution 2: Use a serverless AWS CDK construct
This solution uses AWS Step Functions and Lambda functions to orchestrate the IDP pipeline. We use the IDP AWS CDK constructs, which make it straightforward to work with Amazon Textract at scale. Additionally, we use a Step Functions distributed map to iterate over all the files in the S3 bucket and initiate processing. The first Lambda function determines how many pages your documents has. This enables the pipeline to automatically use either the synchronous (for single-page documents) or asynchronous (for multi-page documents) API. When using the asynchronous API, an additional Lambda function is called to all the JSON files that Amazon Textract will produce for all of your pages into one JSON file to make it straightforward for your downstream applications to work with the information.
This solution also contains two additional Lambda functions. The first function parses the text from the JSON and saves it as a text file in Amazon S3. The second function analyzes the JSON and stores that for metrics on the workload.
The following diagram illustrates the Step Functions workflow.

Prerequisites
This code base uses the AWS CDK and requires Docker. You can deploy this from an AWS Cloud9 instance, which has the AWS CDK and Docker already set up.
Walkthrough
To implement this solution, you first need to clone the repository.
After you clone the repository, install the dependencies:
Then use the following code to deploy the AWS CDK stack:
You must provide both the source bucket and source prefix (the location of the files you want to process) for this solution.
When the deployment is complete, navigate to the Step Functions console, where you should see the state machine ServerlessIDPArchivePipeline.

Open the state machine details page and on the Executions tab, choose Start execution.

Choose Start execution again to run the state machine.

After you start the state machine, you can monitor the pipeline by looking at the map run. You will see an Item processing status section like the following screenshot. As you can see, this is built to run and track what was successful and what failed. This process will continue to run until all documents have been read.

With this solution, you should be able to process millions of files in your AWS account without worrying about how to properly determine which files to send to which API or corrupt files failing your pipeline. Through the Step Functions console, you will be able to watch and monitor your files in real time.
Clean up
After your pipeline is finished running, to clean up, you can go back into your project and enter the following command:
This will delete any services that were deployed for this project.
Conclusion
In this post, we presented a solution that makes it straightforward to convert your document images and PDFs to text files. This is a key prerequisite to using your documents for generative AI and search. To learn more about using text to train or fine-tune your foundation models, refer to Fine-tune Llama 2 for text generation on Amazon SageMaker JumpStart. To use with search, refer to Implement smart document search index with Amazon Textract and Amazon OpenSearch. To learn more about advanced document processing capabilities offered by AWS AI services, refer to Guidance for Intelligent Document Processing on AWS.
About the Authors
 Tim Condello is a senior artificial intelligence (AI) and machine learning (ML) specialist solutions architect at Amazon Web Services (AWS). His focus is natural language processing and computer vision. Tim enjoys taking customer ideas and turning them into scalable solutions.
Tim Condello is a senior artificial intelligence (AI) and machine learning (ML) specialist solutions architect at Amazon Web Services (AWS). His focus is natural language processing and computer vision. Tim enjoys taking customer ideas and turning them into scalable solutions.
 David Girling is a senior AI/ML solutions architect with over twenty years of experience in designing, leading and developing enterprise systems. David is part of a specialist team that focuses on helping customers learn, innovate and utilize these highly capable services with their data for their use cases.
David Girling is a senior AI/ML solutions architect with over twenty years of experience in designing, leading and developing enterprise systems. David is part of a specialist team that focuses on helping customers learn, innovate and utilize these highly capable services with their data for their use cases.
Author: Tim Condello