

Creating an organizational multi-Region failover strategy
You can use these fault boundaries to build multi-Region applications that consist of independent, fault-isolated replicas in each Region that limit shared fate scenarios… This allows you to build multi-Region applications and leverage a spectrum of approaches from backup and restore to pilot lig…
AWS Regions provide fault isolation boundaries that prevent correlated failure and contain the impact from AWS service impairments to a single Region when they occur. You can use these fault boundaries to build multi-Region applications that consist of independent, fault-isolated replicas in each Region that limit shared fate scenarios. This allows you to build multi-Region applications and leverage a spectrum of approaches from backup and restore to pilot light to active/active to implement your multi-Region architecture. However, applications typically don’t operate in isolation; consider both the components you will use and their dependencies as part of your failover strategy. Generally, multiple applications make up what we refer to as a user story, a specific capability offered to an end user, like “posting a picture and caption on a social media app” or “checking out on an e-commerce site”. Because of this, you should develop an organizational multi-Region failover strategy that provides the necessary coordination and consistency to make your approach successful.
Overview
There are four high-level strategies that organizations can pick from to guide a multi-Region approach:
- Component-level failover
- Individual application failover
- Dependency graph failover
- Entire application portfolio failover
These strategies move from the most granular to the coarsest approach. Each strategy has tradeoffs and addresses different challenges, including flexibility of failover decision making, testability of the failover combinations, presence of modal behavior, and organizational investment in planning and implementation. By the end of this post, you will be able to identify the pros and cons of each strategy so you can make intentional choices about which you select for your multi-Region failover solution.
Component-level failover
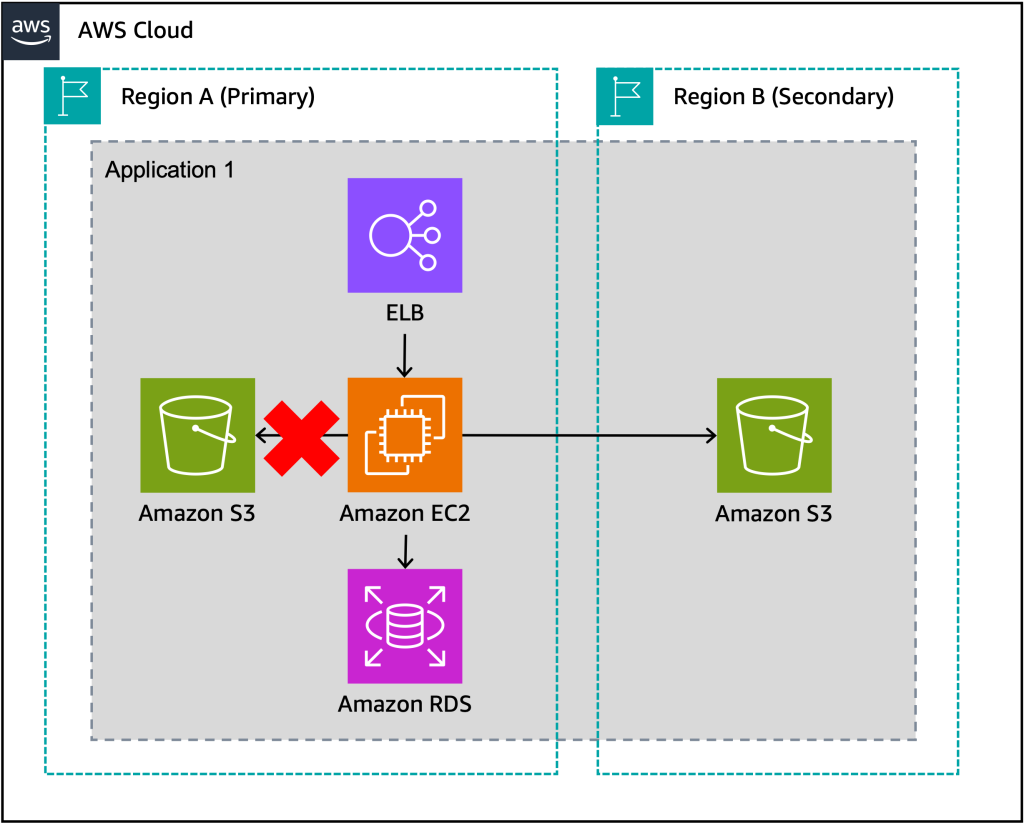
Applications are made up of multiple components, including their infrastructure, code and config, data stores, and dependencies. The component-level failover strategy helps you recover from individual component impairments. This means that when a single component is impaired, the application will fail over to a component hosted in a different Region. Consider the application in Figure 1. When the Amazon Simple Storage Service (Amazon S3) resources used by the application experience elevated error rates or higher latency, the application fails over to use data from an S3 bucket in its secondary Region.

Figure 1. When the application experiences an impairment using S3 resources in the primary Region, it fails over to use an S3 bucket in the secondary Region.
This strategy gives the most autonomy and flexibility to individual applications, but has four main tradeoffs:
- It adds latency by using resources in a second Region because they are physically further away. This gives the application multiple modes of behavior, lower latency when all components are in one Region, and higher latency when the components are split between Regions. Modal behavior can produce unexpected and undesirable results.
- It introduces the possibility for inconsistent data if asynchronous replication is used in the data store.
- It typically requires a runtime update of the application’s configuration to switch a component to a different Region, which can be unreliable during a failure scenario.
- There are 2N-1 possible configurations (where N is the number of components in the application) of the application, which can make every possible combination in an application difficult to test.
Individual application failover
The next strategy allows individual applications to make an autonomous decision to fail over all of its components together, shown in Figure 2. This removes the latency tradeoff from the previous strategy by keeping all of the application components in the same Region. It also significantly reduces the complexity by only having two possible configurations per application. Additionally, applications can be failed over to another Region without updating their configuration by using approaches like Amazon Route 53 DNS failover, removing the unreliability of runtime configuration updates.

Figure 2. Application 3 experiences an impairment and fails over to the secondary Region
However, allowing individual applications to make their own failover decision can introduce the same modal behavior we saw with component-level failover, just in a different dimension. In the worst case, 50% of the applications in a user story could fail over while 50% don’t, meaning every application interaction could be a cross-Region request, shown in Figure 3.

Figure 3. The worst-case scenario of allowing applications to make failover decisions independently
Additionally, while this approach removes the complexity of the component failover approach, it still exhibits a level of similar complexity, albeit smaller, by having 2N-1 combinations of application locations across Regions, also making this approach difficult to test and coordinate.
Dependency graph failover
To solve the complexity of the previous strategy, you might decide to coordinate failover of all applications that support a user story as a single unit. We call this a dependency graph and it ensures that all applications that interact with each other will always be in the same Region, as shown in Figure 4.

Figure 4. A dependency graph of applications that all support user story “A”
While this solves the previous latency, modal behavior, and complexity tradeoffs, it comes with its own challenges. In a portfolio with multiple user stories and applications, this graph can be very large and discovering each dependency, especially infrequently used ones, can be difficult. In fact, seemingly unrelated dependency graphs can be connected by a single vertex that is shared between them, as shown in Figure 5.

Figure 5. Two unrelated user stories share a dependency on Application 4, requiring both dependency graphs to failover if either experience an impairment
For example, if every user story you provide depends on a single authentication and authorization system, when one graph of applications needs to failover, then so does the entire authorization system. In turn, every other user story that depends on that authorization system needs to fail over as well. To mitigate this, you might implement independent replicas of these types of applications in each Region, if possible, to remove edges from the dependency graph.
Entire portfolio failover
The final strategy is failing over an entire application portfolio, whether or not applications are impacted or have any interaction with those that are, as shown in Figure 6. This strategy helps remove the operational burden of creating and maintaining dependency graphs for every user story your business supports.

Figure 6. Every user story fails over together regardless of observed impact from a failure
The major tradeoff is the organizational investment to create multi-Region capabilities for every application – you might not have made that broad investment in the other strategies. You can make this strategy slightly more granular by implementing it for specific application tiers, for example, failing over all tier-1 applications together, as long as you know there aren’t dependencies across applications of different criticality.
You can also combine this approach with the second strategy. Let individual applications make failover decisions until you see broad enough impact, or impact from the modal behavior, that you decide to make all applications failover to your secondary Region to mitigate the effects.
Conclusion
This blog post has looked at four different high-level approaches for creating an organizational multi-Region failover strategy.
Each strategy optimizes for different outcomes. Component-level failover gives you the highest degree of flexibility without organizational capabilities or coordination, but introduces the most complexity and bimodal behavior. Individual application failover optimizes for less complexity in failover combinations than component-level while still maintaining decentralized flexibility in failover decision making. Dependency graph failover optimizes for only needing to failover the minimum set of applications to support a capability, which removes the presence of modal behavior while requiring more organizational investment to do so. Finally, portfolio failover optimizes for not needing to maintain dependency graphs, but requires significant additional investment to build a multi-Region capability for every application.
Creating the strategy can be an iterative journey. You might start with allowing individual applications to make failover decisions while you build toward a future state of managing failover of independent dependency graphs. For more information on creating multi-Region architectures, see AWS Multi-Region Fundamentals and Disaster Recovery of Workloads on AWS.
Author: Michael Haken