

Develop and train large models cost-efficiently with Metaflow and AWS Trainium
Second, open source Metaflow provides the necessary software infrastructure to build production-grade ML/AI systems in a developer-friendly manner… In the following sections, we first introduce Metaflow and the Trainium integration… Metaflow overview Metaflow was originally developed at Netf…
This is a guest post co-authored with Ville Tuulos (Co-founder and CEO) and Eddie Mattia (Data Scientist) of Outerbounds.
To build a production-grade AI system today (for example, to do multilingual sentiment analysis of customer support conversations), what are the primary technical challenges? Historically, natural language processing (NLP) would be a primary research and development expense. In 2024, however, organizations are using large language models (LLMs), which require relatively little focus on NLP, shifting research and development from modeling to the infrastructure needed to support LLM workflows.
For AWS and Outerbounds customers, the goal is to build a differentiated machine learning and artificial intelligence (ML/AI) system and reliably improve it over time. This often means the method of using a third-party LLM API won’t do for security, control, and scale reasons. Owning the infrastructural control and knowhow to run workflows that power AI systems is a requirement.
Returning to the original question, three MLOps challenges may arise:
- You need high-quality data to train and fine-tune models
- You need a diverse cloud infrastructure for experimentation, training, tracking, and orchestrating the production system
- You need a significant amount of compute to power the system
In this post, we highlight a collaboration between Outerbounds and AWS that takes a step towards addressing the last two challenges. First, the AWS Trainium accelerator provides a high-performance, cost-effective, and readily available solution for training and fine-tuning large models. Second, open source Metaflow provides the necessary software infrastructure to build production-grade ML/AI systems in a developer-friendly manner. It provides an approachable, robust Python API for the full infrastructure stack of ML/AI, from data and compute to workflows and observability.
In the following sections, we first introduce Metaflow and the Trainium integration. We then show how to set up the infrastructure stack you need to take your own data assets and pre-train or fine-tune a state-of-the-art Llama2 model on Trainium hardware.
Metaflow overview
Metaflow was originally developed at Netflix to enable data scientists and ML engineers to build ML/AI systems quickly and deploy them on production-grade infrastructure. Netflix open sourced the framework in 2019 with integrations to AWS services like AWS Batch, AWS Step Functions (see Unbundling Data Science Workflows with Metaflow and AWS Step Functions), Kubernetes, and throughput-optimized Amazon Simple Storage Service (Amazon S3), so you can build your own Netflix-scale ML/AI environment in your AWS account.
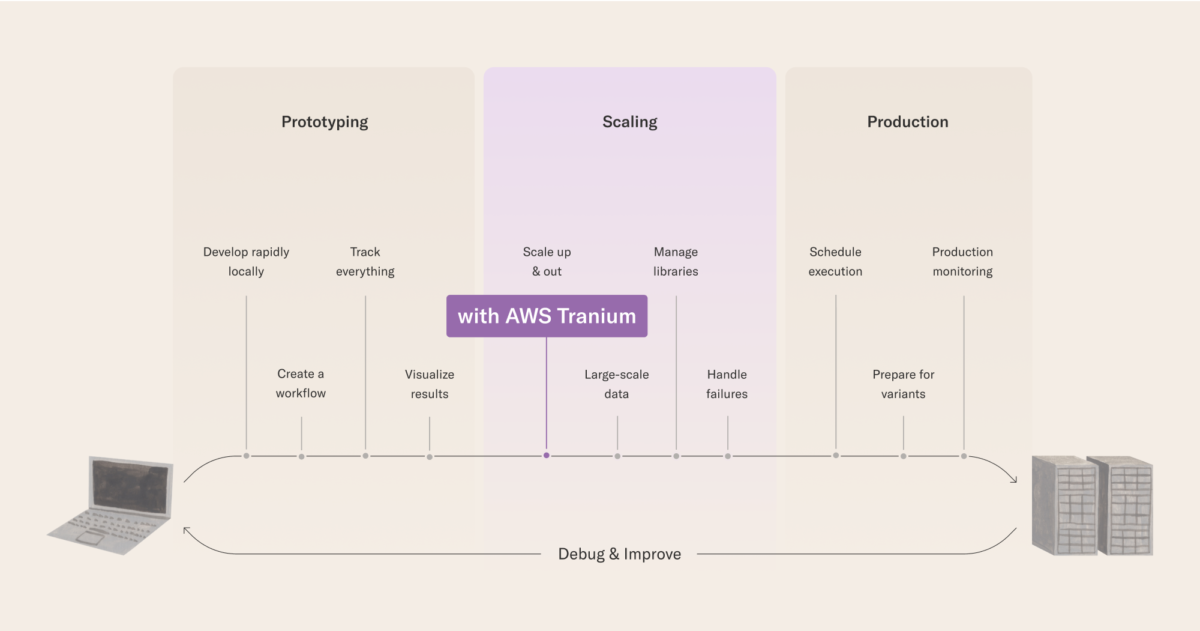
The key motivation of Metaflow is to address the typical needs of all ML/AI projects with a straightforward, human-centric API, from prototype to production (and back). The following figure illustrates this workflow.

Metaflow’s coherent APIs simplify the process of building real-world ML/AI systems in teams. Metaflow helps scientists and engineers access, move, and manipulate data efficiently; track and version experiments and models; orchestrate and integrate workflows to surrounding systems; and scale compute to the cloud easily. Moreover, it has first-class support for teams, such as namespacing and deploying workflows in versioned production branches.
Now, with today’s announcement, you have another straightforward compute option for workflows that need to train or fine-tune demanding deep learning models: running them on Trainium.
How Metaflow integrates with Trainium
From a Metaflow developer perspective, using Trainium is similar to other accelerators. After a Metaflow deployment is configured to access Trainium chips through the compute platform customers use with Metaflow (which we discuss later in this post), ML engineers and data scientists can operate autonomously in the land of deep learning code. Scientists can write PyTorch, Hugging Face, and use the AWS Neuron SDK along with the NeuronX Distributed SDK to optimize these frameworks to target Trainium devices, and Metaflow integrates with the underlying AWS services to separate concerns about how to actually run the code at scale.
As illustrated by the following figure, you can declare the following in a few lines of Python code:
- How many nodes to launch
- How many Trainium devices to use per node
- How the nodes are interconnected (Elastic Fabric Adapter)
- How often to check the resource utilization
- What training script the torchrun process should run on each node

You can initialize the training process in the start step, which directs the next train step to run on two parallel instances (num_parallel=2). The decorators of the train step configure your desired training setup:
@torchrun– Sets up PyTorch Distributed across two instances@batch– Configures the Trainium nodes, managed by AWS Batch@neuron_monitor– Activates the monitoring UI that allows you to monitor the utilization of the Trainium cores
Metaflow allows you to configure all this functionality in a few lines of code. However, the main benefit is that you can embed Trainium-based training code inside a larger production system, using the scaffolding provided by Metaflow.
Benefits of using Trainium with Metaflow
Trainium and Metaflow work together to solve problems like what we discussed earlier in this post. The Trainium devices and Neuron software stack make it straightforward for teams to access and effectively use the high-performance hardware needed for cutting-edge AI.
Trainium provides a few key benefits for building real-world AI systems:
- Trainium instances can help reduce generative AI model training and fine-tuning costs by up to 50% over comparable instances on AWS
- It is readily available in many AWS Regions, is often more available than GPU-based instance types, and scaling is available in the most popular Regions worldwide
- The hardware and software are mature and actively developed by AWS
If you have been struggling with GPU availability and cost, you’ll surely appreciate these benefits. Using Trainium effectively can require a bit of infrastructure effort and knowledge, which is a key motivation for this integration. Through Metaflow and the deployment scripts provided in this post, you should be able to get started with Trainium with ease.
Besides easy access, using Trainium with Metaflow brings a few additional benefits:
Infrastructure accessibility
Metaflow is known for its developer-friendly APIs that allow ML/AI developers to focus on developing models and applications, and not worry about infrastructure. Metaflow helps engineers manage the infrastructure, making sure it integrates with existing systems and policies effortlessly.
Data, model, and configuration management
Metaflow provides built-in, seamless artifact persistence, tracking, and versioning, which covers the full state of the workflows, making sure you’ll follow MLOps best practices. Thanks to Metaflow’s high-throughput S3 client, you can load and save datasets and model checkpoints very quickly, without having to worry about extra infrastructure such as shared file systems. You can use artifacts to manage configuration, so everything from hyperparameters to cluster sizing can be managed in a single file, tracked alongside the results.
Observability
Metaflow comes with a convenient UI, which you can customize to observe metrics and data that matter to your use cases in real time. In the case of Trainium, we provide a custom visualization that allows you to monitor utilization of the NeuronCores inside Trainium instances, making sure that resources are used efficiently. The following screenshot shows an example of the visualization for core (top) and memory (bottom) utilization.

Multi-node compute
Finally, a huge benefit of Metaflow is that you can use it to manage advanced multi-instance training clusters, which would take a lot of involved engineering otherwise. For instance, you can train a large PyTorch model, sharded across Trainium instances, using Metaflow’s @torchrun and @batch decorators.
Behind the scenes, the decorators set up a training cluster using AWS Batch multi-node with a specified number of Trainium instances, configured to train a PyTorch model across the instances. By using the launch template we provide in this post, the setup can benefit from low-latency, high-throughput networking via Elastic Fabric Adapter (EFA) networking interfaces.
Solution overview
As a practical example, let’s set up the complete stack required to pre-train Llama2 for a few epochs on Trainium using Metaflow. The same recipe applies to the fine-tuning examples in the repository.
Deploy and configure Metaflow
If you already use a Metaflow deployment, you can skip to the next step to deploy the Trainium compute environment.
Deployment
To deploy a Metaflow stack using AWS CloudFormation, complete the following steps:
- Download the CloudFormation template.
- On the CloudFormation console, choose Stacks in the navigation pane.
- Choose Create new stack.
- For Prepare template¸ select Template is ready.
- For Template source, select Upload a template file.
- Upload the template.
- Choose Next.

- If you are brand new to Metaflow, or are trying this recipe as a proof of concept, we suggest you change the
APIBasicAuthparameter tofalseand leave all other default parameter settings. - Complete the stack creation process.

After you create the CloudFormation stack and configure Metaflow to use the stack resources, there is no additional setup required. For more information about the Metaflow components that AWS CloudFormation deploys, see AWS Managed with CloudFormation.
Configuration
To use the stack you just deployed from your laptop or cloud workstation, complete the following steps:
- Prepare a Python environment and install Metaflow in it:
- Run
metaflow configure awsin a terminal.
After the CloudFormation stack deployment is complete, the Outputs on the stack details page will contain a list of resource names and their values, which you can use in the Metaflow AWS configuration prompts.
Deploy a Trainium compute environment
The default Metaflow deployment from the previous step has an AWS Batch compute environment, but it will not be able to schedule jobs to run on Amazon Elastic Compute Cloud (Amazon EC2) instances with Trainium devices. To deploy an AWS Batch compute environment for use with Trainium accelerators, you can use the following CloudFormation template. Complete the following steps:
- Download the CloudFormation template.
- On the CloudFormation console, choose Stacks in the navigation pane.
- Choose Create new stack.
- For Prepare template¸ select Template is ready.
- For Template source, select Upload a template file.
- Upload the template.
- Choose Next.
- Complete the stack creation process.
Take note of the name of the AWS Batch job queue that you created to use in a later step.
Prepare a base Docker image to run Metaflow tasks
Metaflow tasks run inside Docker containers when AWS Batch is used as a compute backend. To run Trainium jobs, developers need to build a custom image and specify it in the @batch decorator Metaflow developers use to declare task resources:
To make the image, complete the following steps:
- Create an Amazon Elastic Container Registry (Amazon ECR) registry to store your image in.
- Create and log in to an EC2 instance with sufficient memory. For this post, we used Ubuntu x86 OS on a C5.4xlarge instance.
- Install Docker.
- Copy the following Dockerfile to your instance.
- Authenticate with the upstream base image provider:
- Build the image:
- On the Amazon ECR console, navigate to the ECR registry you created, and you will find the commands needed to authenticate from the EC2 instance and push your image.
Clone the repository on your workstation
Now you’re ready to verify the infrastructure is working properly, after which you can run complex distributed training code like Llama2 training. To get started, clone the examples repository to the workstation where you configured Metaflow with AWS:
Verify the infrastructure with an allreduce example
To validate your infrastructure configuration, complete the following steps:
- Navigate to the
allreduceexample:
- Open the flow.py file and make sure to set the job queue and image to the name of the queue you deployed with AWS CloudFormation and the image you pushed to Amazon ECR, respectively.
- To run the
allreducecode, run the following Metaflow command:
You can find the logs (truncated in the following code snippet for readability) in the Metaflow UI:
Configure and run any Neuron distributed code
If the allreduce test runs successfully, you are ready to move on to meaningful workloads. To complete this onboarding, complete the following steps:
- Navigate to the
llama2-7b-pretrain-trndirectory. - Similar to the all reduce example, before using this code, you need to modify the config.py file so that it matches the AWS Batch job queue and ECR image that you created. Open the file, find these lines, and modify them to your values:
- After modifying these values, and any others you want to experiment with, run the following command:
- Then run the workflow to pre-train your own Llama2 model from scratch:
This will train the model on however many nodes you specify in the config.py file, and will push the trained model result to Amazon S3 storage, versioned by Metaflow’s data store using the flow name and run ID.
Logs will appear like the following (truncated from a sample run of five steps for readability):
Clean up
To clean up resources, delete the CloudFormation stacks for your Metaflow deployment and Trainium compute environment:
Conclusion
You can get started experimenting with the solution presented in this post in your environment today. Follow the instructions in the GitHub repository to pre-train a Llama2 model on Trainium devices. Additionally, we have prepared examples for fine-tuning Llama2 and BERT models, demonstrating how you can use the Optimum Neuron package to use the integration from this post with any Hugging Face model.
We are happy to help you get started. Join the Metaflow community Slack for support, to provide feedback, and share experiences!
About the authors
 Ville Tuulos is a co-founder and CEO of Outerbounds, a developer-friendly ML/AI platform. He has been developing infrastructure for ML and AI for over two decades in academia and as a leader at a number of companies. At Netflix, he led the ML infrastructure team that created Metaflow, a popular open-source, human-centric foundation for ML/AI systems. He is also the author of a book, Effective Data Science Infrastructure, published by Manning.
Ville Tuulos is a co-founder and CEO of Outerbounds, a developer-friendly ML/AI platform. He has been developing infrastructure for ML and AI for over two decades in academia and as a leader at a number of companies. At Netflix, he led the ML infrastructure team that created Metaflow, a popular open-source, human-centric foundation for ML/AI systems. He is also the author of a book, Effective Data Science Infrastructure, published by Manning.  Eddie Mattia is in scientific computing and more recently building machine learning developer tools. He has worked as a researcher in academia, in customer-facing and engineering roles at MLOps startups, and as a product manager at Intel. Currently, Eddie is working to improve the open-source Metaflow project and is building tools for AI researchers and MLOps developers at Outerbounds.
Eddie Mattia is in scientific computing and more recently building machine learning developer tools. He has worked as a researcher in academia, in customer-facing and engineering roles at MLOps startups, and as a product manager at Intel. Currently, Eddie is working to improve the open-source Metaflow project and is building tools for AI researchers and MLOps developers at Outerbounds.  Vidyasagar specializes in high performance computing, numerical simulations, optimization techniques and software development across industrial and academic environments. At AWS, Vidyasagar is a Senior Solutions Architect developing predictive models, generative AI and simulation technologies. Vidyasagar has a PhD from the California Institute of Technology.
Vidyasagar specializes in high performance computing, numerical simulations, optimization techniques and software development across industrial and academic environments. At AWS, Vidyasagar is a Senior Solutions Architect developing predictive models, generative AI and simulation technologies. Vidyasagar has a PhD from the California Institute of Technology.  Diwakar Bansal is an AWS Senior Specialist focused on business development and go-to-market for GenAI and Machine Learning accelerated computing services. Diwakar has led product definition, global business development, and marketing of technology products in the fields of IOT, Edge Computing, and Autonomous Driving focusing on bringing AI and Machine leaning to these domains. Diwakar is passionate about public speaking and thought leadership in the Cloud and GenAI space.
Diwakar Bansal is an AWS Senior Specialist focused on business development and go-to-market for GenAI and Machine Learning accelerated computing services. Diwakar has led product definition, global business development, and marketing of technology products in the fields of IOT, Edge Computing, and Autonomous Driving focusing on bringing AI and Machine leaning to these domains. Diwakar is passionate about public speaking and thought leadership in the Cloud and GenAI space.  Sadaf Rasool is a Machine Learning Engineer with the Annapurna ML Accelerator team at AWS. As an enthusiastic and optimistic AI/ML professional, he holds firm to the belief that the ethical and responsible application of AI has the potential to enhance society in the years to come, fostering both economic growth and social well-being.
Sadaf Rasool is a Machine Learning Engineer with the Annapurna ML Accelerator team at AWS. As an enthusiastic and optimistic AI/ML professional, he holds firm to the belief that the ethical and responsible application of AI has the potential to enhance society in the years to come, fostering both economic growth and social well-being.  Scott Perry is a Solutions Architect on the Annapurna ML accelerator team at AWS. Based in Canada, he helps customers deploy and optimize deep learning training and inference workloads using AWS Inferentia and AWS Trainium. His interests include large language models, deep reinforcement learning, IoT, and genomics.
Scott Perry is a Solutions Architect on the Annapurna ML accelerator team at AWS. Based in Canada, he helps customers deploy and optimize deep learning training and inference workloads using AWS Inferentia and AWS Trainium. His interests include large language models, deep reinforcement learning, IoT, and genomics.Author: Ville Tuulos