

Distributed training and efficient scaling with the Amazon SageMaker Model Parallel and Data Parallel Libraries
There has been tremendous progress in the field of distributed deep learning for large language models (LLMs), especially after the release of ChatGPT in December 2022… In December 2023, Amazon announced the release of the SageMaker model parallel library 2…0 (SMP), which achieves state-of-the-…
There has been tremendous progress in the field of distributed deep learning for large language models (LLMs), especially after the release of ChatGPT in December 2022. LLMs continue to grow in size with billions or even trillions of parameters, and they often won’t fit into a single accelerator device such as GPU or even a single node such as ml.p5.32xlarge because of memory limitations. Customers training LLMs often must distribute their workload across hundreds or even thousands of GPUs. Enabling training at such scale remains a challenge in distributed training, and training efficiently in such a large system is another equally important problem. Over the past years, the distributed training community has introduced 3D parallelism (data parallelism, pipeline parallelism, and tensor parallelism) and other techniques (such as sequence parallelism and expert parallelism) to address such challenges.
In December 2023, Amazon announced the release of the SageMaker model parallel library 2.0 (SMP), which achieves state-of-the-art efficiency in large model training, together with the SageMaker distributed data parallelism library (SMDDP). This release is a significant update from 1.x: SMP is now integrated with open source PyTorch Fully Sharded Data Parallel (FSDP) APIs, which allows you to use a familiar interface when training large models, and is compatible with Transformer Engine (TE), unlocking tensor parallelism techniques alongside FSDP for the first time. To learn more about the release, refer to Amazon SageMaker model parallel library now accelerates PyTorch FSDP workloads by up to 20%.
In this post, we explore the performance benefits of Amazon SageMaker (including SMP and SMDDP), and how you can use the library to train large models efficiently on SageMaker. We demonstrate the performance of SageMaker with benchmarks on ml.p4d.24xlarge clusters up to 128 instances, and FSDP mixed precision with bfloat16 for the Llama 2 model. We start with a demonstration of near-linear scaling efficiencies for SageMaker, followed by analyzing contributions from each feature for optimal throughput, and end with efficient training with various sequence lengths up to 32,768 through tensor parallelism.
Near-linear scaling with SageMaker
To reduce the overall training time for LLM models, preserving high throughput when scaling to large clusters (thousands of GPUs) is crucial given the inter-node communication overhead. In this post, we demonstrate robust and near-linear scaling (by varying the number of GPUs for a fixed total problem size) efficiencies on p4d instances invoking both SMP and SMDDP.
In this section, we demonstrate SMP’s near-linear scaling performance. Here we train Llama 2 models of various sizes (7B, 13B, and 70B parameters) using a fixed sequence length of 4,096, the SMDDP backend for collective communication, TE enabled, a global batch size of 4 million, with 16 to 128 p4d nodes. The following table summarizes our optimal configuration and training performance (model TFLOPs per second).
| Model size | Number of nodes | TFLOPs* | sdp* | tp* | offload* | Scaling efficiency |
| 7B | 16 | 136.76 | 32 | 1 | N | 100.0% |
| 32 | 132.65 | 64 | 1 | N | 97.0% | |
| 64 | 125.31 | 64 | 1 | N | 91.6% | |
| 128 | 115.01 | 64 | 1 | N | 84.1% | |
| 13B | 16 | 141.43 | 32 | 1 | Y | 100.0% |
| 32 | 139.46 | 256 | 1 | N | 98.6% | |
| 64 | 132.17 | 128 | 1 | N | 93.5% | |
| 128 | 120.75 | 128 | 1 | N | 85.4% | |
| 70B | 32 | 154.33 | 256 | 1 | Y | 100.0% |
| 64 | 149.60 | 256 | 1 | N | 96.9% | |
| 128 | 136.52 | 64 | 2 | N | 88.5% |
*At the given model size, sequence length, and number of nodes, we show the globally optimal throughput and configurations after exploring various sdp, tp, and activation offloading combinations.
The preceding table summarizes the optimal throughput numbers subject to sharded data parallel (sdp) degree (typically using FSDP hybrid sharding instead of full sharding, with more details in the next section), tensor parallel (tp) degree, and activation offloading value changes, demonstrating a near-linear scaling for SMP together with SMDDP. For example, given the Llama 2 model size 7B and sequence length 4,096, overall it achieves scaling efficiencies of 97.0%, 91.6%, and 84.1% (relative to 16 nodes) at 32, 64, and 128 nodes, respectively. The scaling efficiencies are stable across different model sizes and increase slightly as the model size gets larger.
SMP and SMDDP also demonstrate similar scaling efficiencies for other sequence lengths such as 2,048 and 8,192.
SageMaker model parallel library 2.0 performance: Llama 2 70B
Model sizes have continued to grow over the past years, along with frequent state-of-the-art performance updates in the LLM community. In this section, we illustrate performance in SageMaker for the Llama 2 model using a fixed model size 70B, sequence length of 4,096, and a global batch size of 4 million. To compare with the previous table’s globally optimal configuration and throughput (with SMDDP backend, typically FSDP hybrid sharding and TE), the following table extends to other optimal throughputs (potentially with tensor parallelism) with extra specifications on the distributed backend (NCCL and SMDDP), FSDP sharding strategies (full sharding and hybrid sharding), and enabling TE or not (default).
| Model size | Number of nodes | TFLOPS | TFLOPs #3 config | TFLOPs improvement over baseline | ||||||||
| . | . | NCCL full sharding: #0 | SMDDP full sharding: #1 | SMDDP hybrid sharding: #2 | SMDDP hybrid sharding with TE: #3 | sdp* | tp* | offload* | #0 → #1 | #1 → #2 | #2 → #3 | #0 → #3 |
| 70B | 32 | 150.82 | 149.90 | 150.05 | 154.33 | 256 | 1 | Y | -0.6% | 0.1% | 2.9% | 2.3% |
| 64 | 144.38 | 144.38 | 145.42 | 149.60 | 256 | 1 | N | 0.0% | 0.7% | 2.9% | 3.6% | |
| 128 | 68.53 | 103.06 | 130.66 | 136.52 | 64 | 2 | N | 50.4% | 26.8% | 4.5% | 99.2% | |
*At the given model size, sequence length, and number of nodes, we show the globally optimal throughput and configuration after exploring various sdp, tp, and activation offloading combinations.
The latest release of SMP and SMDDP supports multiple features including native PyTorch FSDP, extended and more flexible hybrid sharding, transformer engine integration, tensor parallelism, and optimized all gather collective operation. To better understand how SageMaker achieves efficient distributed training for LLMs, we explore incremental contributions from SMDDP and the following SMP core features:
- SMDDP enhancement over NCCL with FSDP full sharding
- Replacing FSDP full sharding with hybrid sharding, which reduces communication cost to improve throughput
- A further boost to throughput with TE, even when tensor parallelism is disabled
- At lower resource settings, activation offloading might be able to enable training that would otherwise be infeasible or very slow due to high memory pressure
FSDP full sharding: SMDDP enhancement over NCCL
As shown in the previous table, when models are fully sharded with FSDP, although NCCL (TFLOPs #0) and SMDDP (TFLOPs #1) throughputs are comparable at 32 or 64 nodes, there is a huge improvement of 50.4% from NCCL to SMDDP at 128 nodes.
At smaller model sizes, we observe consistent and significant improvements with SMDDP over NCCL, starting at smaller cluster sizes, because SMDDP is able to mitigate the communication bottleneck effectively.
FSDP hybrid sharding to reduce communication cost
In SMP 1.0, we launched sharded data parallelism, a distributed training technique powered by Amazon in-house MiCS technology. In SMP 2.0, we introduce SMP hybrid sharding, an extensible and more flexible hybrid sharding technique that allows models to be sharded among a subset of GPUs, instead of all training GPUs, which is the case for FSDP full sharding. It’s useful for medium-sized models that don’t need to be sharded across the entire cluster in order to satisfy per-GPU memory constraints. This leads to clusters having more than one model replica and each GPU communicating with fewer peers at runtime.
SMP’s hybrid sharding enables efficient model sharding over a wider range, from the smallest shard degree with no out of memory issues up to the whole cluster size (which equates to full sharding).
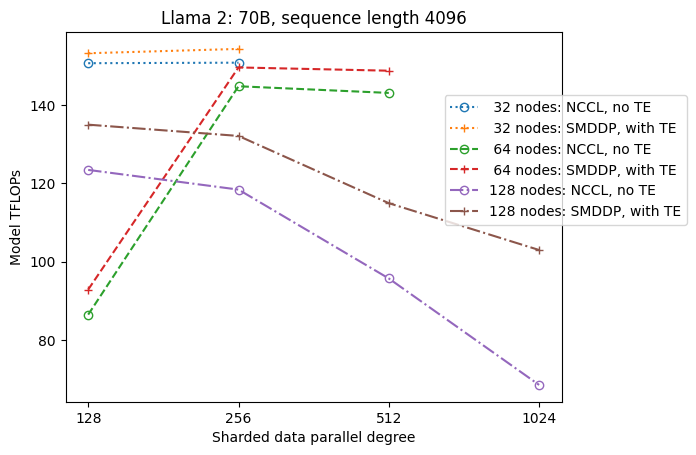
The following figure illustrates the throughput dependence on sdp at tp = 1 for simplicity. Although it’s not necessarily the same as the optimal tp value for NCCL or SMDDP full sharding in the previous table, the numbers are quite close. It clearly validates the value of switching from full sharding to hybrid sharding at a large cluster size of 128 nodes, which is applicable to both NCCL and SMDDP. For smaller model sizes, significant improvements with hybrid sharding start at smaller cluster sizes, and the difference keeps increasing with cluster size.

Improvements with TE
TE is designed to accelerate LLM training on NVIDIA GPUs. Despite not using FP8 because it’s unsupported on p4d instances, we still see significant speedup with TE on p4d.
On top of MiCS trained with the SMDDP backend, TE introduces a consistent boost for throughput across all cluster sizes (the only exception is full sharding at 128 nodes), even when tensor parallelism is disabled (tensor parallel degree is 1).
For smaller model sizes or various sequence lengths, the TE boost is stable and non-trivial, in the range of approximately 3–7.6%.
Activation offloading at low resource settings
At low resource settings (given a small number of nodes), FSDP might experience a high memory pressure (or even out of memory in the worst case) when activation checkpointing is enabled. For such scenarios bottlenecked by memory, turning on activation offloading is potentially an option to improve performance.
For example, as we saw previously, although the Llama 2 at model size 13B and sequence length 4,096 is able to train optimally with at least 32 nodes with activation checkpointing and without activation offloading, it achieves the best throughput with activation offloading when limited to 16 nodes.
Enable training with long sequences: SMP tensor parallelism
Longer sequence lengths are desired for long conversations and context, and are getting more attention in the LLM community. Therefore, we report various long sequence throughputs in the following table. The table shows optimal throughputs for Llama 2 training on SageMaker, with various sequence lengths from 2,048 up to 32,768. At sequence length 32,768, native FSDP training is infeasible with 32 nodes at a global batch size of 4 million.
| . | . | . | TFLOPS | ||
| Model size | Sequence length | Number of nodes | Native FSDP and NCCL | SMP and SMDDP | SMP improvement |
| 7B | 2048 | 32 | 129.25 | 138.17 | 6.9% |
| 4096 | 32 | 124.38 | 132.65 | 6.6% | |
| 8192 | 32 | 115.25 | 123.11 | 6.8% | |
| 16384 | 32 | 100.73 | 109.11 | 8.3% | |
| 32768 | 32 | N.A. | 82.87 | . | |
| 13B | 2048 | 32 | 137.75 | 144.28 | 4.7% |
| 4096 | 32 | 133.30 | 139.46 | 4.6% | |
| 8192 | 32 | 125.04 | 130.08 | 4.0% | |
| 16384 | 32 | 111.58 | 117.01 | 4.9% | |
| 32768 | 32 | N.A. | 92.38 | . | |
| *: max | . | . | . | . | 8.3% |
| *: median | . | . | . | . | 5.8% |
When the cluster size is large and given a fixed global batch size, some model training might be infeasible with native PyTorch FSDP, lacking a built-in pipeline or tensor parallelism support. In the preceding table, given a global batch size of 4 million, 32 nodes, and sequence length 32,768, the effective batch size per GPU is 0.5 (for example, tp = 2 with batch size 1), which would otherwise be infeasible without introducing tensor parallelism.
Conclusion
In this post, we demonstrated efficient LLM training with SMP and SMDDP on p4d instances, attributing contributions to multiple key features, such as SMDDP enhancement over NCCL, flexible FSDP hybrid sharding instead of full sharding, TE integration, and enabling tensor parallelism in favor of long sequence lengths. After being tested over a wide range of settings with various models, model sizes, and sequence lengths, it exhibits robust near-linear scaling efficiencies, up to 128 p4d instances on SageMaker. In summary, SageMaker continues to be a powerful tool for LLM researchers and practitioners.
To learn more, refer to SageMaker model parallelism library v2, or contact the SMP team at sm-model-parallel-feedback@amazon.com.
Acknowledgements
We’d like to thank Robert Van Dusen, Ben Snyder, Gautam Kumar, and Luis Quintela for their constructive feedback and discussions.
About the Authors

Xinle Sheila Liu is an SDE in Amazon SageMaker. In her spare time, she enjoys reading and outdoor sports.
 Suhit Kodgule is a Software Development Engineer with the AWS Artificial Intelligence group working on deep learning frameworks. In his spare time, he enjoys hiking, traveling, and cooking.
Suhit Kodgule is a Software Development Engineer with the AWS Artificial Intelligence group working on deep learning frameworks. In his spare time, he enjoys hiking, traveling, and cooking.
 Victor Zhu is a Software Engineer in Distributed Deep Learning at Amazon Web Services. He can be found enjoying hiking and board games around the SF Bay Area.
Victor Zhu is a Software Engineer in Distributed Deep Learning at Amazon Web Services. He can be found enjoying hiking and board games around the SF Bay Area.
 Derya Cavdar works as a software engineer at AWS. Her interests include deep learning and distributed training optimization.
Derya Cavdar works as a software engineer at AWS. Her interests include deep learning and distributed training optimization.
 Teng Xu is a Software Development Engineer in the Distributed Training group in AWS AI. He enjoys reading.
Teng Xu is a Software Development Engineer in the Distributed Training group in AWS AI. He enjoys reading.
Author: Xinle Sheila Liu