

Enhance performance of generative language models with self-consistency prompting on Amazon Bedrock
Generative language models have proven remarkably skillful at solving logical and analytical natural language processing (NLP) tasks… For example, chain-of-thought (CoT) is known to improve a model’s capacity for complex multi-step problems… Amazon Bedrock is a fully managed service that offe…
Generative language models have proven remarkably skillful at solving logical and analytical natural language processing (NLP) tasks. Furthermore, the use of prompt engineering can notably enhance their performance. For example, chain-of-thought (CoT) is known to improve a model’s capacity for complex multi-step problems. To additionally boost accuracy on tasks that involve reasoning, a self-consistency prompting approach has been suggested, which replaces greedy with stochastic decoding during language generation.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models from leading AI companies and Amazon via a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. With the batch inference API, you can use Amazon Bedrock to run inference with foundation models in batches and get responses more efficiently. This post shows how to implement self-consistency prompting via batch inference on Amazon Bedrock to enhance model performance on arithmetic and multiple-choice reasoning tasks.
Overview of solution
Self-consistency prompting of language models relies on the generation of multiple responses that are aggregated into a final answer. In contrast to single-generation approaches like CoT, the self-consistency sample-and-marginalize procedure creates a range of model completions that lead to a more consistent solution. The generation of different responses for a given prompt is possible due to the use of a stochastic, rather than greedy, decoding strategy.
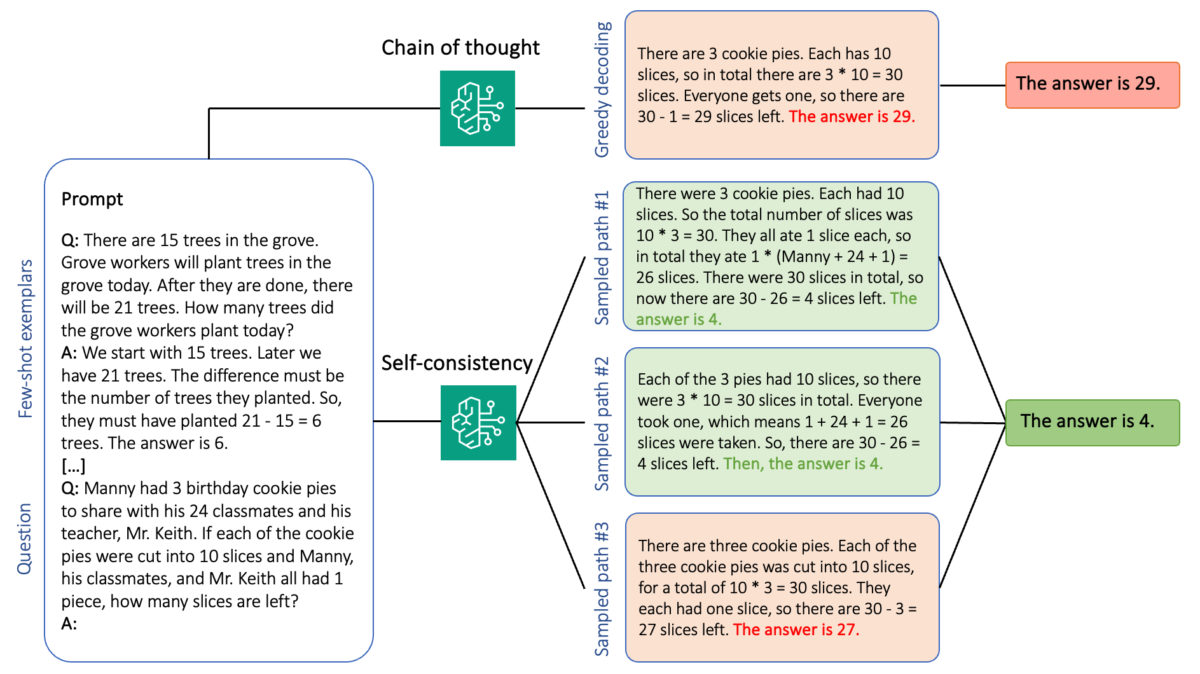
The following figure shows how self-consistency differs from greedy CoT in that it generates a diverse set of reasoning paths and aggregates them to produce the final answer.

Decoding strategies for text generation
Text generated by decoder-only language models unfolds word by word, with the subsequent token being predicted on the basis of the preceding context. For a given prompt, the model computes a probability distribution indicating the likelihood of each token to appear next in the sequence. Decoding involves translating these probability distributions into actual text. Text generation is mediated by a set of inference parameters that are often hyperparameters of the decoding method itself. One example is the temperature, which modulates the probability distribution of the next token and influences the randomness of the model’s output.
Greedy decoding is a deterministic decoding strategy that at each step selects the token with the highest probability. Although straightforward and efficient, the approach risks falling into repetitive patterns, because it disregards the broader probability space. Setting the temperature parameter to 0 at inference time essentially equates to implementing greedy decoding.
Sampling introduces stochasticity into the decoding process by randomly selecting each subsequent token based on the predicted probability distribution. This randomness results in greater output variability. Stochastic decoding proves more adept at capturing the diversity of potential outputs and often yields more imaginative responses. Higher temperature values introduce more fluctuations and increase the creativity of the model’s response.
Prompting techniques: CoT and self-consistency
The reasoning ability of language models can be augmented via prompt engineering. In particular, CoT has been shown to elicit reasoning in complex NLP tasks. One way to implement a zero-shot CoT is via prompt augmentation with the instruction to “think step by step.” Another is to expose the model to exemplars of intermediate reasoning steps in few-shot prompting fashion. Both scenarios typically use greedy decoding. CoT leads to significant performance gains compared to simple instruction prompting on arithmetic, commonsense, and symbolic reasoning tasks.
Self-consistency prompting is based on the assumption that introducing diversity in the reasoning process can be beneficial to help models converge on the correct answer. The technique uses stochastic decoding to achieve this goal in three steps:
- Prompt the language model with CoT exemplars to elicit reasoning.
- Replace greedy decoding with a sampling strategy to generate a diverse set of reasoning paths.
- Aggregate the results to find the most consistent answer in the response set.
Self-consistency is shown to outperform CoT prompting on popular arithmetic and commonsense reasoning benchmarks. A limitation of the approach is its larger computational cost.
This post shows how self-consistency prompting enhances performance of generative language models on two NLP reasoning tasks: arithmetic problem-solving and multiple-choice domain-specific question answering. We demonstrate the approach using batch inference on Amazon Bedrock:
- We access the Amazon Bedrock Python SDK in JupyterLab on an Amazon SageMaker notebook instance.
- For arithmetic reasoning, we prompt Cohere Command on the GSM8K dataset of grade school math problems.
- For multiple-choice reasoning, we prompt AI21 Labs Jurassic-2 Mid on a small sample of questions from the AWS Certified Solutions Architect – Associate exam.
Prerequisites
This walkthrough assumes the following prerequisites:
- An AWS account with a ml.t3.medium notebook Instance hosted in SageMaker.
- An AWS Identity and Access Management (IAM) SageMaker execution role with attached AmazonBedrockFullAccess and
iam:PassRolepolicies to run Jupyter inside the SageMaker notebook instance. - An IAM
BedrockBatchInferenceRolerole for batch inference with Amazon Bedrock with Amazon Simple Storage Service (Amazon S3) access andsts:AssumeRoletrust policies. For more information, refer to Set up permissions for batch inference. - Access to models hosted on Amazon Bedrock. Choose Manage model access on the Amazon Bedrock console and choose among the list of available options. We use Cohere Command and AI21 Labs Jurassic-2 Mid for this demo.

The estimated cost to run the code shown in this post is $100, assuming you run self-consistency prompting one time with 30 reasoning paths using one value for the temperature-based sampling.
Dataset to probe arithmetic reasoning capabilities
GSM8K is a dataset of human-assembled grade school math problems featuring a high linguistic diversity. Each problem takes 2–8 steps to solve and requires performing a sequence of elementary calculations with basic arithmetic operations. This data is commonly used to benchmark the multi-step arithmetic reasoning capabilities of generative language models. The GSM8K train set comprises 7,473 records. The following is an example:
{"question": "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?", "answer": "Natalia sold 48/2 = <<48/2=24>>24 clips in May.nNatalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May.n#### 72"}
Set up to run batch inference with Amazon Bedrock
Batch inference allows you to run multiple inference calls to Amazon Bedrock asynchronously and improve the performance of model inference on large datasets. The service is in preview as of this writing and only available through the API. Refer to Run batch inference to access batch inference APIs via custom SDKs.
After you have downloaded and unzipped the Python SDK in a SageMaker notebook instance, you can install it by running the following code in a Jupyter notebook cell:
Format and upload input data to Amazon S3
Input data for batch inference needs to be prepared in JSONL format with recordId and modelInput keys. The latter should match the body field of the model to be invoked on Amazon Bedrock. In particular, some supported inference parameters for Cohere Command are temperature for randomness, max_tokens for output length, and num_generations to generate multiple responses, all of which are passed together with the prompt as modelInput:
See Inference parameters for foundation models for more details, including other model providers.
Our experiments on arithmetic reasoning are performed in the few-shot setting without customizing or fine-tuning Cohere Command. We use the same set of eight few-shot exemplars from the chain-of-thought (Table 20) and self-consistency (Table 17) papers. Prompts are created by concatenating the exemplars with each question from the GSM8K train set.
We set max_tokens to 512 and num_generations to 5, the maximum allowed by Cohere Command. For greedy decoding, we set temperature to 0 and for self-consistency, we run three experiments at temperatures 0.5, 0.7, and 1. Each setting yields different input data according to the respective temperature values. Data is formatted as JSONL and stored in Amazon S3.
Create and run batch inference jobs in Amazon Bedrock
Batch inference job creation requires an Amazon Bedrock client. We specify the S3 input and output paths and give each invocation job a unique name:
Jobs are created by passing the IAM role, model ID, job name, and input/output configuration as parameters to the Amazon Bedrock API:
Listing, monitoring, and stopping batch inference jobs is supported by their respective API calls. On creation, jobs appear first as Submitted, then as InProgress, and finally as Stopped, Failed, or Completed.
If the jobs are successfully complete, the generated content can be retrieved from Amazon S3 using its unique output location.
[Out]: 'Natalia sold 48 * 1/2 = 24 clips less in May. This means she sold 48 + 24 = 72 clips in April and May. The answer is 72.'
Self-consistency enhances model accuracy on arithmetic tasks
Self-consistency prompting of Cohere Command outperforms a greedy CoT baseline in terms of accuracy on the GSM8K dataset. For self-consistency, we sample 30 independent reasoning paths at three different temperatures, with topP and topK set to their default values. Final solutions are aggregated by choosing the most consistent occurrence via majority voting. In case of a tie, we randomly choose one of the majority responses. We compute accuracy and standard deviation values averaged over 100 runs.
The following figure shows the accuracy on the GSM8K dataset from Cohere Command prompted with greedy CoT (blue) and self-consistency at temperature values 0.5 (yellow), 0.7 (green), and 1.0 (orange) as a function of the number of sampled reasoning paths.

The preceding figure shows that self-consistency enhances arithmetic accuracy over greedy CoT when the number of sampled paths is as low as three. Performance increases consistently with further reasoning paths, confirming the importance of introducing diversity in the thought generation. Cohere Command solves the GSM8K question set with 51.7% accuracy when prompted with CoT vs. 68% with 30 self-consistent reasoning paths at T=1.0. All three surveyed temperature values yield similar results, with lower temperatures being comparatively more performant at less sampled paths.
Practical considerations on efficiency and cost
Self-consistency is limited by the increased response time and cost incurred when generating multiple outputs per prompt. As a practical illustration, batch inference for greedy generation with Cohere Command on 7,473 GSM8K records finished in less than 20 minutes. The job took 5.5 million tokens as input and generated 630,000 output tokens. At current Amazon Bedrock inference prices, the total cost incurred was around $9.50.
For self-consistency with Cohere Command, we use inference parameter num_generations to create multiple completions per prompt. As of this writing, Amazon Bedrock allows a maximum of five generations and three concurrent Submitted batch inference jobs. Jobs proceed to the InProgress status sequentially, therefore sampling more than five paths requires multiple invocations.
The following figure shows the runtimes for Cohere Command on the GSM8K dataset. Total runtime is shown on the x axis and runtime per sampled reasoning path on the y axis. Greedy generation runs in the shortest time but incurs a higher time cost per sampled path.

Greedy generation completes in less than 20 minutes for the full GSM8K set and samples a unique reasoning path. Self-consistency with five samples requires about 50% longer to complete and costs around $14.50, but produces five paths (over 500%) in that time. Total runtime and cost increase step-wise with every extra five sampled paths. A cost-benefit analysis suggests that 1–2 batch inference jobs with 5–10 sampled paths is the recommended setting for practical implementation of self-consistency. This achieves enhanced model performance while keeping cost and latency at bay.
Self-consistency enhances model performance beyond arithmetic reasoning
A crucial question to prove the suitability of self-consistency prompting is whether the method succeeds across further NLP tasks and language models. As an extension to an Amazon-related use case, we perform a small-sized analysis on sample questions from the AWS Solutions Architect Associate Certification. This is a multiple-choice exam on AWS technology and services that requires domain knowledge and the ability to reason and decide among several options.
We prepare a dataset from SAA-C01 and SAA-C03 sample exam questions. From the 20 available questions, we use the first 4 as few-shot exemplars and prompt the model to answer the remaining 16. This time, we run inference with the AI21 Labs Jurassic-2 Mid model and generate a maximum of 10 reasoning paths at temperature 0.7. Results show that self-consistency enhances performance: although greedy CoT produces 11 correct answers, self-consistency succeeds on 2 more.
The following table shows the accuracy results for 5 and 10 sampled paths averaged over 100 runs.
| . | Greedy decoding | T = 0.7 |
| # sampled paths: 5 | 68.6 | 74.1 ± 0.7 |
| # sampled paths: 10 | 68.6 | 78.9 ± 0.3 |
In the following table, we present two exam questions that are incorrectly answered by greedy CoT while self-consistency succeeds, highlighting in each case the correct (green) or incorrect (red) reasoning traces that led the model to produce correct or incorrect responses. Although not every sampled path generated by self-consistency is correct, the majority converges on the true answer as the number of sampled paths increases. We observe that 5–10 paths are typically enough to improve over the greedy results, with diminishing returns in terms of efficiency past those values.
| Question | A web application allows customers to upload orders to an S3 bucket. The resulting Amazon S3 events trigger a Lambda function that inserts a message to an SQS queue. A single EC2 instance reads messages from the queue, processes them, and stores them in a DynamoDB table partitioned by unique order ID. Next month traffic is expected to increase by a factor of 10 and a Solutions Architect is reviewing the architecture for possible scaling problems. Which component is MOST likely to need re-architecting to be able to scale to accommodate the new traffic? A. Lambda function | An application running on AWS uses an Amazon Aurora Multi-AZ DB cluster deployment for its database. When evaluating performance metrics, a solutions architect discovered that the database reads are causing high I/O and adding latency to the write requests against the database. What should the solutions architect do to separate the read requests from the write requests? A. Enable read-through caching on the Aurora database. |
| Correct answer | C – A single EC2 instance will not scale and is a single point of failure in the architecture. A much better solution would be to have EC2 instances in an Auto Scaling group across 2 availability zones read messages from the queue. The other responses are all managed services that can be configured to scale or will scale automatically. | C – Aurora Replicas provide a way to offload read traffic. Aurora Replicas share the same underlying storage as the main database, so lag time is generally very low. Aurora Replicas have their own endpoints, so the application will need to be configured to direct read traffic to the new endpoints. |
| Greedy decoding | Scaling the EC2 instance directly may not be possible, as it may not be possible to resize the instance. Scaling the Lambda function may not be sufficient, as Lambda functions have a 6 GB of memory allocation limit. Scaling the SQS queue may not be sufficient, as SQS has a 10,000 message limit. DynamoDB tables can be scaled by provisioning more capacity units. The correct answer is D. | Modifying the application to read from the Multi-AZ standby instance (option B) is the best approach. The standby instance is asynchronously replicated from the primary instance, so read operations will not interfere with write operations. Enabling read-through caching (option A) or creating an Aurora replica (option C) will not solve the I/O contention issue. Creating a second Aurora database and linking it as a read replica (option D) will not solve the I/O contention issue either. The correct answer is B. |
| Sampled path #1 | Scaling the EC2 instance to 10 times its current size may not be feasible, either from a cost or performance perspective. It would require a larger instance, which can be expensive. A more cost-effective approach might be to use a swarm of smaller instances (e.g., Auto Scaling Group) to share the load. In this case, the EC2 instance would likely need to be re-architected. The correct answer is C. | Modifying the application to use the appropriate endpoints is not a practical solution as it would require changes to the application code. The correct answer is C: Create an Aurora replica and modify the application to use the appropriate endpoints. |
| Sampled path #2 | Scaling a single EC2 instance is more difficult and problematic than scaling the other service components. Amazon SQS, Lambda, and DynamoDB can all scale automatically to cope with the increased load. The correct answer is C. | (C) Create an Aurora replica and modify the application to use the appropriate endpoints. By configuring an Aurora Replica, you can separate read traffic from write traffic. The Aurora Replicas use different endpoint URLs, allowing you to direct read traffic to the replica instead of the primary database. The replica can process read requests in parallel with write requests to the primary database, reducing I/O and latency. |
Clean up
Running batch inference in Amazon Bedrock is subject to charges according to the Amazon Bedrock Pricing. When you complete the walkthrough, delete your SageMaker notebook instance and remove all data from your S3 buckets to avoid incurring future charges.
Considerations
Although the demonstrated solution shows improved performance of language models when prompted with self-consistency, it’s important to note that the walkthrough is not production-ready. Before you deploy to production, you should adapt this proof of concept to your own implementation, keeping in mind the following requirements:
- Access restriction to APIs and databases to prevent unauthorized usage.
- Adherence to AWS security best practices regarding IAM role access and security groups.
- Validation and sanitization of user input to prevent prompt injection attacks.
- Monitoring and logging of triggered processes to enable testing and auditing.
Conclusion
This post shows that self-consistency prompting enhances performance of generative language models in complex NLP tasks that require arithmetic and multiple-choice logical skills. Self-consistency uses temperature-based stochastic decoding to generate various reasoning paths. This increases the ability of the model to elicit diverse and useful thoughts to arrive at correct answers.
With Amazon Bedrock batch inference, the language model Cohere Command is prompted to generate self-consistent answers to a set of arithmetic problems. Accuracy improves from 51.7% with greedy decoding to 68% with self-consistency sampling 30 reasoning paths at T=1.0. Sampling five paths already enhances accuracy by 7.5 percent points. The approach is transferable to other language models and reasoning tasks, as demonstrated by results of the AI21 Labs Jurassic-2 Mid model on an AWS Certification exam. In a small-sized question set, self-consistency with five sampled paths increases accuracy by 5 percent points over greedy CoT.
We encourage you to implement self-consistency prompting for enhanced performance in your own applications with generative language models. Learn more about Cohere Command and AI21 Labs Jurassic models available on Amazon Bedrock. For more information about batch inference, refer to Run batch inference.
Acknowledgements
The author thanks technical reviewers Amin Tajgardoon and Patrick McSweeney for helpful feedback.
About the Author

Lucía Santamaría is a Sr. Applied Scientist at Amazon’s ML University, where she’s focused on raising the level of ML competency across the company through hands-on education. Lucía has a PhD in astrophysics and is passionate about democratizing access to tech knowledge and tools.
Author: Lucia Santamaria